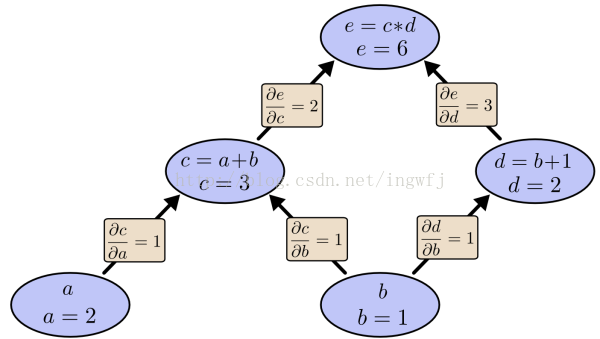
AI自动编程领域核心问题在于IPS归纳式程序合成问题,就是机器通过观察一系列输入输出的样例来生成一个程序,使得它的行为满足样例中的数据。利用AI来解决IPS问题的思路有两种:一种是网络产生程序式的,通过input-output examples 和程序来训练神经网络,得到其训练的参数,该网络会对新的输入输出数据提取特征,预测目标程序中函数出现的概率,选取大概率出现的函数配以搜索算法,在代码段组合空间中进行搜索,从而得到最后的代码段组合即目标程序,所以训练神经网络的目的在于预测新input-output所对应的目标程序中函数的概率分布情况,而预测的目的在于搜索之前的预处理,所以关键在于减小程序空间和设计更好的搜索算法。减小代码空间使用DSL,就是精简的程序语言,函数有限功能逻辑有限。更好的搜索算法则可以传统的枚举式搜索,或者结合机器学习方法中的神经网络来搜索,深度神经网络的优势在于特征的提取和学习复杂概率分布的能力。典型代表有DeepCoder和RobustFill;一种NTM(Neural Turning Machines),直接使用样例训练深度神经网络,最终的程序就是神经网络。神经网络训练的目标在于权重参数w和阀值θ。也就是通过样例的训练之后,对得到的深度神经网络模型直接喂养input数据,则可以得到对应的output。神经网络也仅仅是个模型,训练方法诸多,常用的梯度下降方法。梯度是一个向量,指向函数上升最快的方向,计算梯度需要求解偏导数,而重要的一点是和的导数等于导数的和。梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,直至收敛即不会再下降,也就是到达最底端,或者说是局部极小值,但是局部极小值不代表全局最小值,除非函数是凸函数,凸函数的局部机制就是全局最值,而跳出局部极小值寻找全局最小值仍有包括给定多初始点、模拟退火或者随机方法等多种方法。NTM的关键在于是程序离散的行为differentiable可微分化即连续化,涉及到RNN模型及其机制,采用BP(back propagation)反向传播算法训练神经网络。神经网络参数的训练就像在拟合一个函数的参数,定义这些参数拟合的优劣的函数为cost function成本函数,该函数的变量正是这些参数,改变这些W参数使得cost function减小。因为训练的模型是多层的神经网络,层与层之间传递数值依赖于w和b,所以这些参数内部实际是有一定的关联性。采用梯度下降算法就需要求取cost function的梯度向量,从而求得某点的梯度大小,实际运算为求取复合函数对一系列变量的偏导数,BP算法采用反向传播形式求解多层复合函数对变量的偏导数,核心在于复合函数偏导数求解的链式法则(就是复合函数求导法则)。正向传播求解偏导数就是从原始函数对每一个变量以某条路径求解其偏导数,导致顶层的诸多共享的子路径多次被求解形成冗余求解,BP采用逆向的形式,从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放"些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以"层"为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。BP算法之所以就在于它的反向求解思路使得每一条连接都只经历一次。
采用神经网络来训练数据应该是看中神经网络(ANN)的特点。神经网络由神经元组成,涉及到的参数包括权重w、偏置b,阀值,input、output、actication function。从分类器角度看神经网络,他是一个分类器,是对那些线性不可分的数据进行非线性分类,不过感知机perception是只有输入层和输出层两层的神经网络,可以进行判别式的线性分类。将二维平面的直线f(x) = ax+b扩展到n维则为超平面h=a1*x1+a2*x2+......+an*xn+b,实际计算时使用矩阵W代表第L层到第L+1层的权重,以第L层的激活单元作为行数,以第L+1层的激活单元作为列数,从而构造相邻两层的权重矩阵,而Wx则是权重矩阵与输入值向量的内积,如果x是数据数据集构成的矩阵则是整个数据集与该层权重矩阵的内积。进行分类的是神经元,他接受N个x输入,经过函数计算得出一个值,根据该值进行了分类,神经元是对n个输入数据进行不同的非线性变换,不同之处在于权重值a和偏置b,而这种不同的非线性变换是在提取输入数据的不同方面的特征,作为结果传递到下一层。多层神经元就对数据进行了多次的分类,即切了很多刀,将空间中的数据切成多个模块,即进行分类。神经网络对预测值的计算是正向传播的,从input往output层计算,而对于计算cost function的偏导数则是反向传播的,从output往input计算,即首先用正向传播方法计算出每一层的激活单元, 利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播法计算出直至第二层的所有误差。神经网络的层数决定了它的特征提取的能力和对现实刻画的能力,而且感觉神经网络能够做出线性分类、逻辑回归问题,这取决于网络的层数和所用的激活函数。从另一个角度看,神经网络是区别于线性回归、逻辑回归的特征提取器。本质上将,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征 x 1 ,x 2 ,...,x n ,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制,线性回归、逻辑回归通过不同的函数对原始数据进行一次性的加工而直接使用得到的值加以分类,而且线性回归逻辑回归等仅能输出单个值而神经网络可以输出向量。在神经网络中,原始特征只是输入层,三层的神经网络中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征, 可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。当神经网络的层数增加的时候,有可能出现梯度消失和梯度爆炸的问题。梯度消失问题在于链式法则和使用的激活函数例如sigmoid函数,如果每一层神经元对上一层神经元的除数的导数乘以两者权重值的积均小于1,则随着这种项的增多最终结果趋近于0,导致距离input越近的神经元发生的改变量Δb对最终的loss function的影响很小,即梯度消失,而如果每一个积都很大则出现最终随着乘积链的增长对结果影响增大,即梯度爆炸,多层的神经网络采用ReLU、maxout等函数而非sigmoid函数。与神经网络相关的有CNN,RNN和DNN、LSTM等。神经网络本身存在问题有采用梯度下降算法可能导致陷入局部最优而非全局最优解;网络训练时间长;新增加训练样本则导致重新训练,以前训练好的参数被丢弃;每层的节点数的选择没有理论指导;出现过拟合问题。
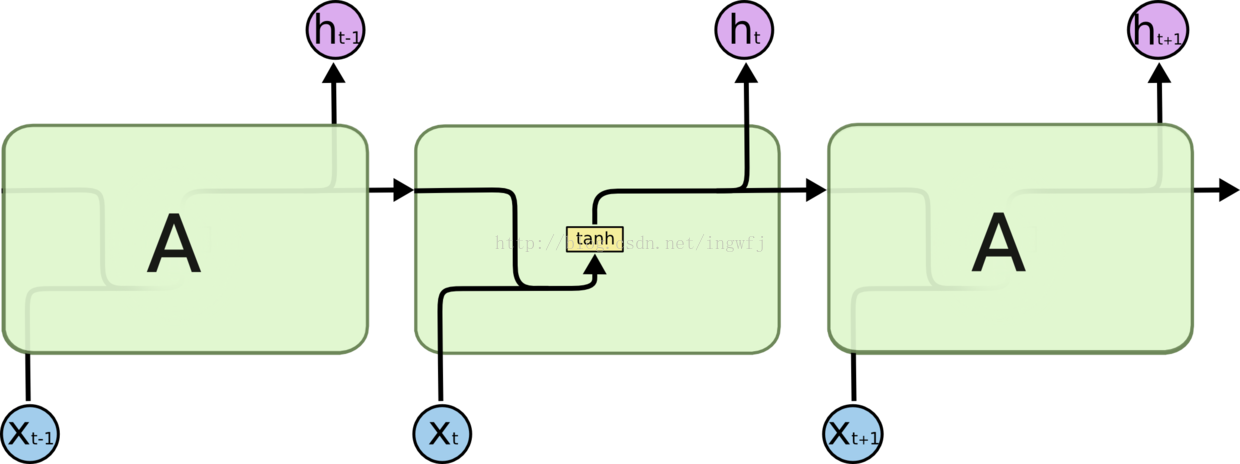
RNN递归神经网络与一般的前馈神经网络不同之处在于RNN允许网络之中出现环,使得神经元的输出可以作为下一时刻的一部分输入,从而网络在t时刻的输出取决于t时刻的input和t-1时刻的网络状态,即
RNN示意图:
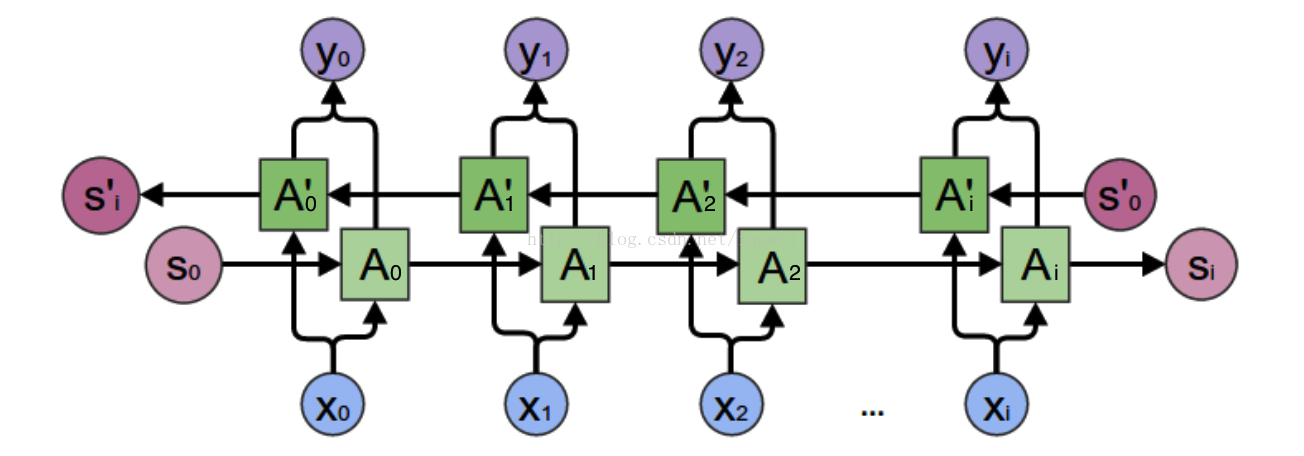
双向RNN:
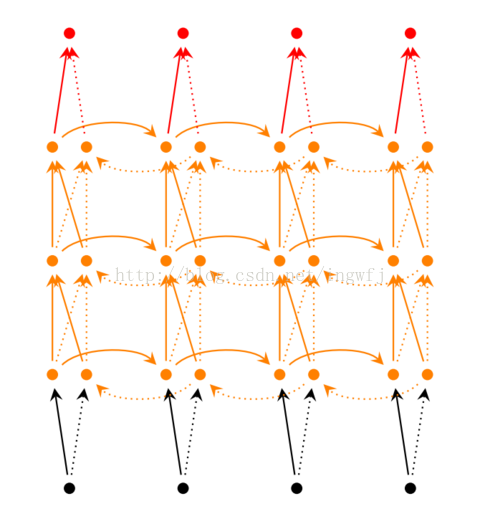
深度双向RNN:
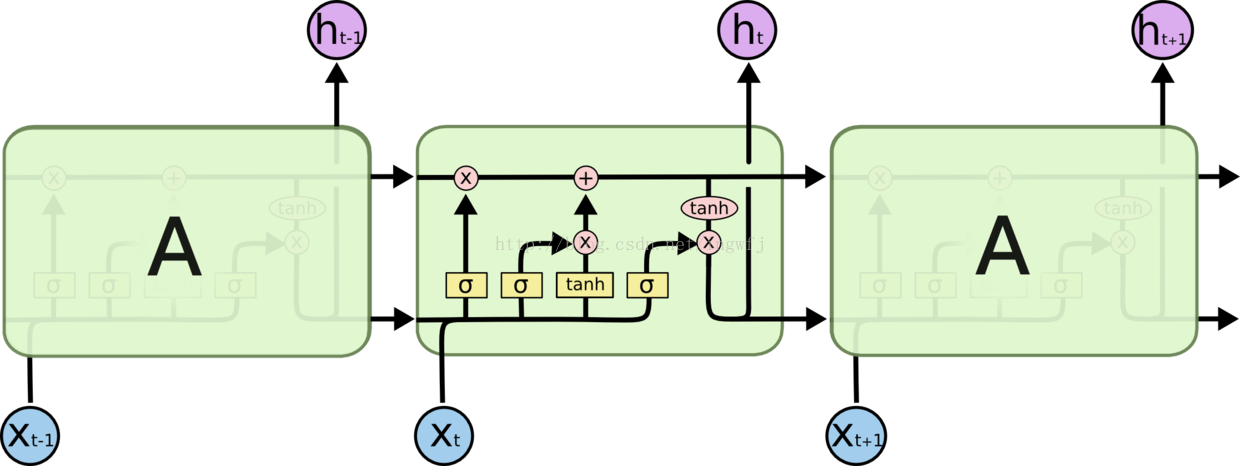
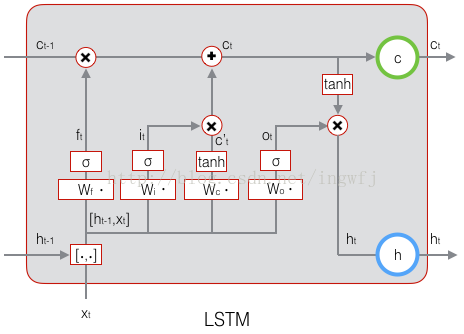
LSTM示意图:
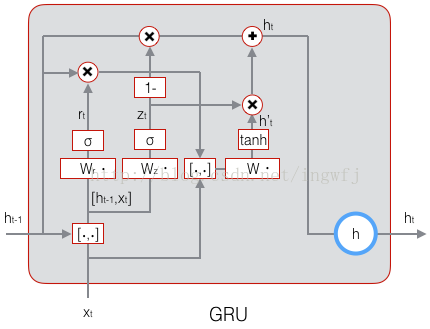
GRN:
原始的RNN每个隐藏点仅有h一个状态值进行短时间的记忆,而LSTM有增加了一个C单元状态来记录长时间的值,在t时刻,LSTM的输入有三个:当前时刻网络的输入值x(t)、上一时刻LSTM的输出值h(t-1)、以及上一时刻的单元状态c(t-1);LSTM的输出有两个:当前时刻LSTM输出值h(t)、和当前时刻的单元状态c(t)。注意x,h,t都是向量。
DNN深度神经网络醉着网络层数的增加出现过拟合、陷入局部最优、梯度消失和复杂问题,采用无监督逐层训练即“预训练+微调”来将大量参数分组,对每组先找到局部看起来较好的设置,然后再基于这些局部较优的结果联合起来进行全局寻优。或者采用每组神经元使用相同的链接权值来训练从而减少训练的参数,即CNN卷积神经网络采用的方法。
介绍LSTM的a great article:http://colah.github.io/posts/2015-08-Understanding-LSTMs/