对于神经网络的解释有很多,多是从不同的视角进行阐述,包括生物学的视角、空间变换的视角、数学的角度、特征工程的角度等等。如果从生物学的角度看,神经网络是模拟人的神经元工作激励,当所受刺激信号达到一定程度之后会向下传递信号,从而完成各层的信号传递,但是梯度下降法训练可能在人脑中没有,有的是当我们为之前做出的决定或反应所极大地伤害或者说我们的利益因为决定而受损则导致我们在下一次调整决策的策略,可是实际生活中哪有那么多数据供你训练来优化决策策略啊。从空间变换的角度看,神经网络W*x、b和激活函数分别完成线性的升维/降维、放大/缩小、旋转和线性的平移和非线性弯曲变换,将数据从输入空间变换到输出空间,每一层的单元数代表数据的维度,层数代表可变换的空间数。从特征工程的角度看,权重的大小代表对该属性的重视程度,意味着重心的确定,也就是在抽取数据的特征,层级越高特征的抽象程度越高。或者从perception到仍为线性分类的multi-layers percetion再到加了非线性激活函数的感知机来解释ANN。实际上对于神经网络不论是何种变形,我都是想从三个方面去理解,一个是对模型的数学证明,二是实验,三是物理意义。另外机器学习模型是用有限的数据进行训练,使用有限的数据进行test,可是应用到无限的应用数据上面,所以对未来数据处理的准确度或者说正确性的概率大小是没有基底可以计算的,因为统计的前提就不成立,因为无限的数据。
RNN打破了传统的神经网络和卷积神经网络输入输出数据尺寸固定的限制,因为添加了时间的维度。善于处理序列化数据的RNN也可以用来处理非序列化数据。一些地方说明某些操作是differentiable可微分的,就是这些操作背后的所基于的数学公式是可求导的,例如可以使用链式法则求其梯度。RNN的增强版包括neural Turning machines,Attentional Interfaces、Adaptive computational time、neural programmer,都是基于attention机制的。。。。。。。
sigmoid函数将x映射到0~1之间,但是可能会出现饱和情况导致梯度变化缓慢,同时因为sigmoid输出值不是以0为中心,导致梯度下降时权重权威正或负,导致梯度下降晃动,tanh则将数值映射到-1~1之间,也存在饱和问题,不存在梯度下降晃动问题。ReLU函数形式为f(x)=max(0,x),计算简单而且对梯度下降有加速作用,但是可能会导致神经元死亡状态,比饱和现象还严重。
传统计算梯度的算法:
计算梯度的方法可以是通过数学中的极限思想来用函数值的变化值除以自变量的变化值,即数值梯度法,或者对函数公式进行微分,然后利用公式直接求得梯度,可以使用微分分析梯度求得的值域数值梯度求得的值比较得出正确性,即梯度检查。同时梯度下降的核心代码段:
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 进行梯度更新梯度下降衍生品mini_batch gradient descent小批量梯度下降SGD针对训练数据超大而通过计算一部分数据来得到梯度进而近似总体梯度,可以避免计算所有数据之后才得到梯度值:
while True:
data_batch = sample_training_data(data, 256) # 256个数据
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 参数更新随机梯度下降Stochastic gradient descent(SGD)是每个batch中只有一个样本进行计算梯度值的大小。这些都是因为梯度下降可能会拘泥于某个局部极小值点所做的调整学习步伐大小的方法,或者也可以优化起点例如使权重的初始化符合一定的分布情况等,而这意味着下降是从哪个点开始下降的。随机梯度下降可能会导致优化在最小值周围震荡,因为每次更新的是基于单个样本的,所以应该随着算法的运行逐渐减小学习率,更加易于接近最小值。而且SGD比每次更新都遍历训练集中所有的样本以它们的预测误差之和为依据更新的BGD速度更快。
对于数据的预处理,使用均值减法,每个特征都会减去其平均值,即零中心化得到处理之后的数据,再进行处理;也可以使用归一化处理,将每个维度的数值都映射到近似相同的范围,可以先做零中心化,之后是每个维度除以其标准差,或者将数值范围映射到-1~1之间;或者使用PCA主成分分析降维之后加快运算;或者使用白化处理数据。
https://zhuanlan.zhihu.com/p/21560667?refer=intelligentunit
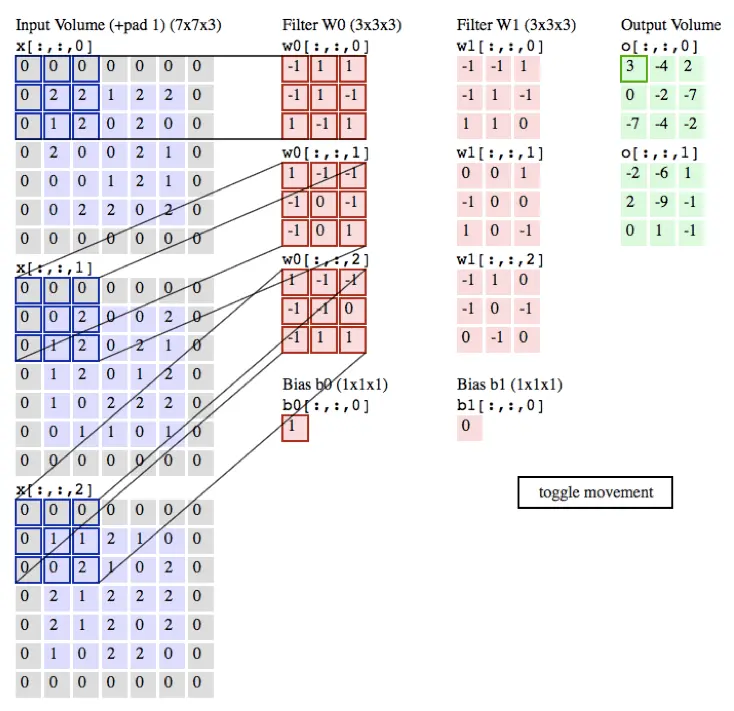
卷积神经网络CNN在很多方面与ANN没有区别,假设输入数据是图像数据,如果采用神经元之间全连接的方式则参数过多因为图像像素的数据量很大,导致训练困难而且过拟合,CNN可以减少参数数量,因为CNN中每一层的神经元都是有宽度、高度和深度的3维神经元,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。从宏观来看,每一层用一些含或者不含参数的可微分的函数,将输入的3D数据变换为3D的输出数据。CNN由卷积层、pooling层和全连接层构成,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。之后经过激活函数的运算输入进pooling层,pooling层在空间维度上进行downsampling操作将结果直接送到全连接层。其中卷基层和全连接层是参数的,而pooling层没有。卷积层的参数是由一些可学习的滤波器即卷积核集合构成的。每个滤波器在空间上(宽度和高度)的尺寸F都比较小,但是深度和输入数据一致。在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(更精确地说是卷积),然后计算整个滤波器和输入数据任一处的内积。当滤波器沿着输入数据的宽度和高度滑过后,会生成一个2维的激活图(activation map),激活图给出了在每个空间位置处滤波器的反应。在每个卷积层上,我们会有一整个集合的滤波器(比如12个),每个都会生成一个不同的二维激活图。将这些激活映射在深度方向上层叠起来就生成了输出数据。卷基层中每个神经元只与输入数据的一个局部区域连接,连接的空间大小为receptive field,超参数F,就是卷积核的尺寸。卷积层中的每个神经元都只是与输入数据体的一个局部在空间上相连,但是与输入数据体的所有深度维度全部相连。在深度方向上有多个神经元。卷基层输出数据体的尺寸由深度depth、步长stride和零填充数量决定,depth和使用的滤波器数量一致,将卷积层中沿着深度方向排列,receptive field相同的神经元集合称为深度列(depth column),同一个depth column中的神经元的receptive field相同,与其receptive field的输入数据全连接,但是参数(权重和偏置)不同。步长就是每次滤波器卷积核的步幅大小,而零填充是为了滤波器在原始图像上滑动的时候输入的尺寸能够整除滤波器的尺寸,零填充数量就是在输入数据体的边界外填充零的尺寸,输出数据体空间尺寸为(W-F +2P)/S+1。而一个卷基层输出数据体的尺寸就是这个卷积层中神经元的个数。卷积层使用参数共享的策略来减少参数的数量,一个卷积层的深度K与使用的卷积核的数量是相同的,将一个卷积层中按照深度切片,切成K片,每一片的尺寸就是输出数据体的尺寸,每个深度切片上使用同样的权重和偏置参数。在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。前向传播的过程中实际是计算神经元权重和输入数据体的卷积,所以实际是卷积核和输入数据的局部区域做点积并加和偏置b。输入数据体的尺寸为W1、 H1、 D1,4个超参数:滤波器的数量K,滤波器的空间尺寸F,步长S,零填充数量P‘输出数据体的尺寸为W2、 H2、 D2,其中:W2=(W1-F+2P)/S+1,H2=(H_1-F+2P)/S+1,D2=K;由于参数共享,每个滤波器包含F*F*D1个权重,卷积层一共有F*F*D1*K个权重和K个偏置;在输出数据体中,第d个深度切片(空间尺寸是W2*H2),用第d个滤波器和输入数据进行有效卷积运算的结果(使用步长S),最后在加上第d个偏差。卷积层运行示例图:https://pic2.zhimg.com/333077b83ed421d6bd53eb7a44fd5799_r.jpg
{kind=link}
在连续的卷积层之间会周期性地插入一个汇聚pooling层。它的作用是逐渐降低数据体的空间尺寸。pooling层对输入数据体的每一个深度切片独立进行操作,改变它的空间尺寸。最常见的形式是汇聚层使用尺寸2x2的滤波器,以步长为2来对每个深度切片进行降采样downsampling,pooling不引入参数只是进行downsampleing采样计算。全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在每一层切片中的神经元共享参数。卷积神经网络最常见的形式就是将一些卷积层和ReLU层放在一起,其后紧跟汇聚层,然后重复如此直到图像在空间上被缩小到一个足够小的尺寸,在某个地方过渡成成全连接层也较为常见。最后的全连接层得到输出。
马尔可夫过程:一种随机过程,该过程中未来的状态不依赖于过去的状态,将来与过去独立的性质为马尔可夫性质。
HMM隐含马尔科夫模型:用来描述隐含未知参数的统计模型,用显性结果来推测隐含参数的概率。使用(观测空间;隐参数即状态空间;初始状态概率;状态转移概率;输出观测概率)来描述。HMM中的马尔可夫链其实是指隐含状态链,即系统下一时刻的状态仅仅由当前状态决定,不依赖于以往的任何状态。HMM是最简单的动态贝叶斯网,用有向无环图来表示变量之间的依赖关系。主要关心的三个问题:如何评估模型与观测序列之间的匹配程度;如何根据观测序列推断出隐藏的模型状态;如何训练模型参数使其能够最好的描述观测数据。具体解决思路和算法还需要读论文。
各种学习模型包括神经网络、深度学习、增强学习等都是覆盖实际问题的范围越广,与实际情况越贴切。增强学习reinforcement learning本身就有延迟后果性质和局部可观测性,他是一种序列化决策过程。
参考链接:
https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunitCNN概述