本篇主要介绍关于多进程的相关知识,同时需对进程与线程之间的关系和区别及应用进行了解,其实包含 multiprocessing模块下的 Process类、进行进程间通信的 Queue类以及进程池 Pool类的学习,最后实现一个实例 模拟文件夹copy器;
一、什么是进程?
首先我们在了解进程之前,我们需要了解一下什么是程序?
程序:
其实就是一堆躺在操作系统下的二进制文件,是静态的;例如 wechar.exe文件,在我们没点击它时,就是一个静态的可执行文件。
进程:
进程就是跑起来的程序,即代码 + 操作系统根据其需求为其分配的资源称之为进程;例如:当一个 Wechat.exe文件我们点击运行时,操作系统会为其调配其所需资源,则运行该程序就是一个进程;进程是操作系统分配资源的基本单位。
需要注意的是:同一个程序执行两次,那就是两个进程;例如 打开腾讯视频--》一个可以播放西游记,一个可以播放红楼梦;
进程的状态:
在现实工作中,任务的数量要远远大于CPU的数量,所以要想实现真正意义上的并行几乎是不可能的,所以大多数情况下都是并发(伪并行),故当运行多个进程时,有的程序处于等待的状态、有的程序处于运行的状态,则进程就可以分为以下几种状态:
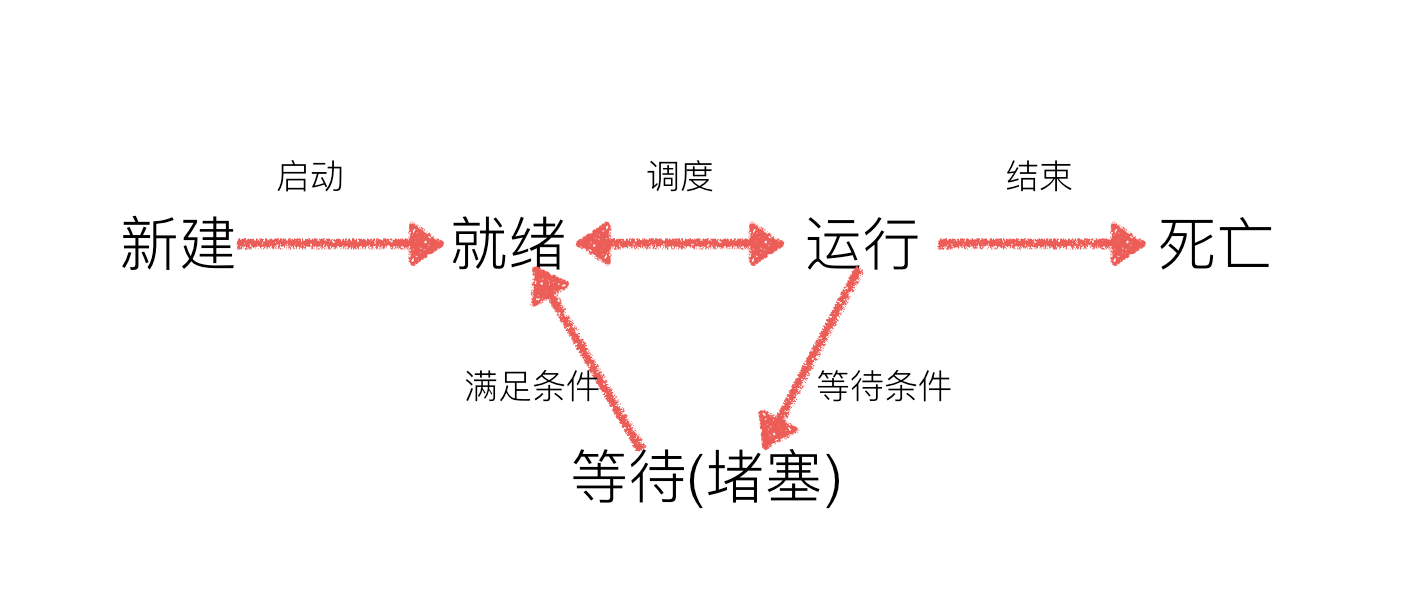
三种状态:
就绪:所有准备工作均完成,等待着操作系统分配CPU进行执行;
运行:正在被CPU执行的程序
堵塞:即待某些条件满足,例如一个程序sleep,此时就处于等待态。
二、多进程的创建过程:、
我们创建多进程主要通过模块 multiprocessing 下的Process类来创建进程对象,通过进程对象来实现创建进程的效果,不多说直接看示例,例如:
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing,time def sing(name): for i in range(10000): print("%s is singing --->%s"%(name,i)) # time.sleep(0.5) def dance(name): for i in range(10000): print("%s is dancing ---> %s"%(name,i)) # time.sleep(0.5) def main(): # 1、创建进程对象,传入工作函数,以及工作函数所需参数 p1 = multiprocessing.Process(target=sing,args=("alex",)) p2 =multiprocessing.Process(target=dance,args=("liudehua",)) # 2、启动进程 p1.start() p2.start() print("This is main process...") # 3、主进程等子进程运行完才关闭 p1.join() p2.join() if __name__=="__main__": main()
从上述例子中可以看出:进程的创建过程与线程的创建过程几乎相同,除了使用模块不相同,其他的几乎类似。那么既然有了线程为什么还要有进程呢?接下来我们就了解一下进程和线程的区别。
三、线程和进程的区别及应用场景
首先我们需要知道无论是线程还是进程均可以实现多任务的效果,但是一个进程必然有一个线程,同时一个进程也可以有多个线程,例如:一个WeChat可以打开多个聊天窗口,与不同的人进行聊天。其关系如下图:
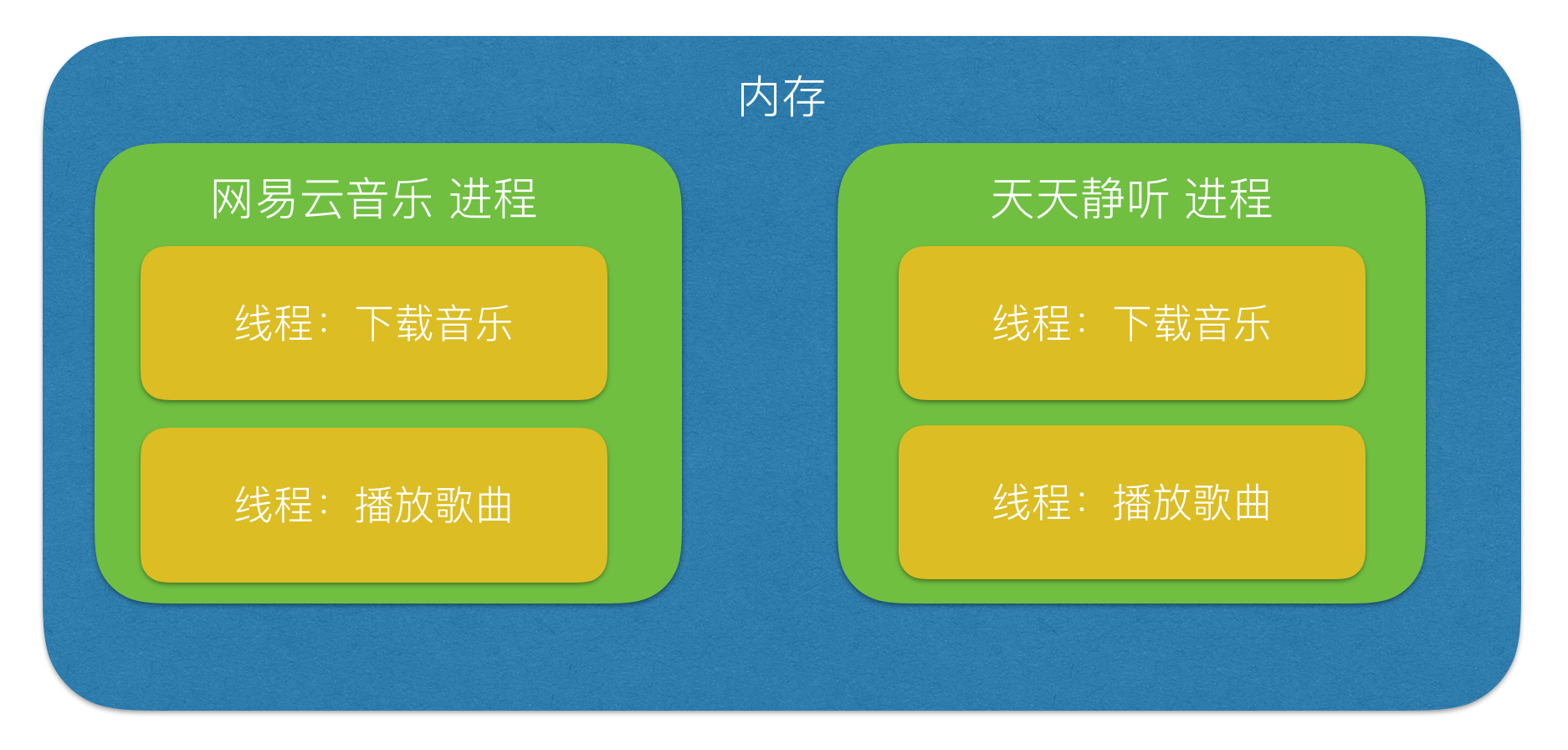
从上面的图我们可以很明确的看出进程与线程之间的关系和区别:
1、一个程序至少有一个进程(当然也可以有多个进程,例如:一个QQ可以同时登入两个用户;),一个进程至少有一个线程(当然也可由多个线程,例如:一个QQ可以同时与两个人进行聊天。)
2、线程无法独立存在,只能依附在进程内执行,即在QQ没有运行的情况下QQ聊天是无法实现的。
3、一个进程的运行需要调配的资源要多得多,但是进程要稳定许多,即一个进程的关闭不会影响另外一个进程的运行,即关闭网易云音乐队天天静听的执行没有任何影响;但是一个主线程的关闭必然会导致所有的子线程死亡,稳定性不如进程。
4、线程可以共享全局变量,而进程间无法全局变量的共享;(要想实现进程间的通信需使用队列等,在后面介绍。)
5、进程是操作系统进行资源管理的基本单位,而线程是对操作系统的分配下来的资源调用的基本单位。
其实我们也可以将进程和线程比喻成:车间流水线的工作(进程) 和 流水线上工人的工作(线程):

个人理解:
可以将进程比如成流水线的运行,即在该流水线的运行需要各种资源(即进程的运行需要操作系统调配资源),以及许多工人,这些工人在不停的工作(线程),他们对该流水线上的资源是共享的(线程间共享全局变量),同时若想提高流水线的运行速度,则可以为流水线增加一些工人(多线程),而同时若想提高车间的生产能力,则可以通过增加多条流水线(多进程),但是每增加一条流水线,所需的成本也高一些(即进程需调配的资源增加),同时每个流水线上的资源是不共享的(即进程间不共享全局变量。)。
4、获取进程的PID和PPID
每个进程均会有进程号以及父进程号,
5、Queue实现进程间的通信
首先,我们需要知道进程间不共享全局变量,例如:网易云音乐无法播放酷狗中的音乐,接下来我们从一个例子中验证:
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing,time # 创建全局变量 name =["alex","little-five","amanda"] def work1(): # work1修改全局变量 name.append("hello") print(name) def work2(): # work2查看全局变量 print("in the work2:--> ",name) def main(): p1 = multiprocessing.Process(target=work1) p2 = multiprocessing.Process(target=work2) p1.start() time.sleep(1) # 休眠1s,保证进程p1先运行 p2.start() print("in main process : ",name) p1.join() p2.join() if __name__=="__main__": main()
从输出结果可以得出 : 进程间不共享全局变量,即即使主进程与子进程间也不共享全局变量。这是由于:
进程每创建子线程时,老版本内核会相当于将主进程的资源和代码copy一份,但每个子线程运行的代码位置不同,但是新版本则不会拷贝代码而是代码共享,而当某个进程要修改代码时,则是相应的代码进行拷贝即写时拷贝。
那么我们怎么实现进程间的通信呢?
#!/usr/bin/env python # -*- coding:utf-8 -*- import multiprocessing def recv_msg(q): """数据的接收""" names =["alex","wupeiqi","linghaifeng"] for name in names: q.put(name) #将每个名字传入队列 def analysis_msg(q): """数据的分析""" new_names =list() while not q.empty(): new_name=q.get() # 获取队列中的名字 new_names.append(new_name) print(list(map(lambda x:x.title(),new_names))) #通过map 函数对列表进行处理 q=multiprocessing.Queue() # 创建队列对象 def main(): p1 = multiprocessing.Process(target=recv_msg,args=(q,)) #我们将队列作为工作函数的参数传入进程 p2 = multiprocessing.Process(target=analysis_msg,args=(q,)) p1.start() p2.start() p1.join() p2.join() if __name__=="__main__": main()
注:其实队列就像一根水管,即先入先出,后入后出,数据从水管的一边传入从另一边输出,通过队列来实现进程间的数据传递,实现进程间的通信。