1>互斥锁
模拟一个买票软件,多个进程共享同一文件,用多个进程模拟多个人执行抢票任务。
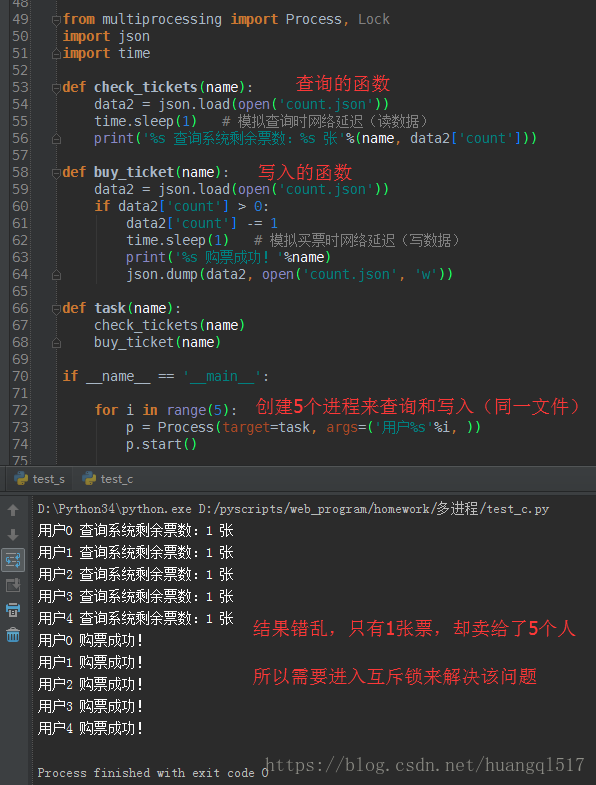
如上,并发运行,效率高,但是操作同一文件,数据写入错乱,引入互斥锁解决
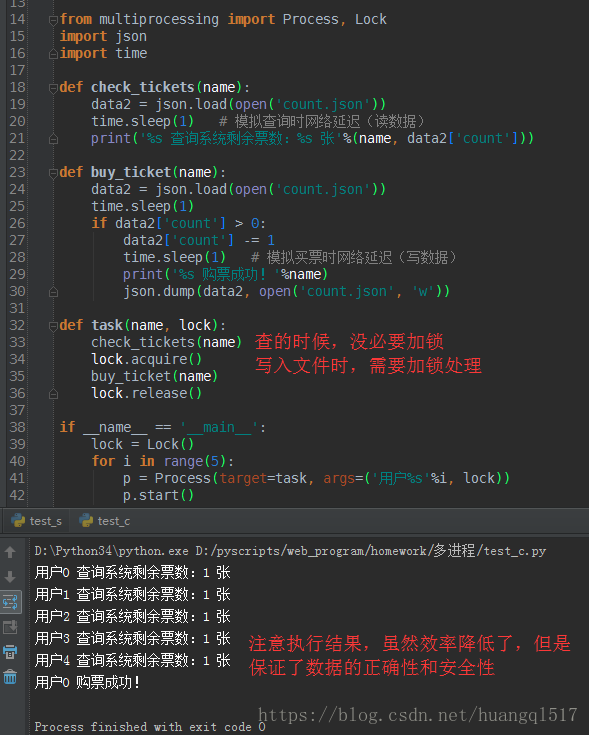
为何查的时候不用加锁,因为查只是去单纯获取公共资源,大家同一时间查的数据是一样的,没必要一个一个去查,
这样效率就太低了,很明显,这样的动作是完全可以并发执行的,提升效率。但是写入数据就不同了,多个用户对同一个文件
进行写入操作,那数据不是乱了,所以,需要加锁保证数据的正确性。
2>互斥锁和join的区别
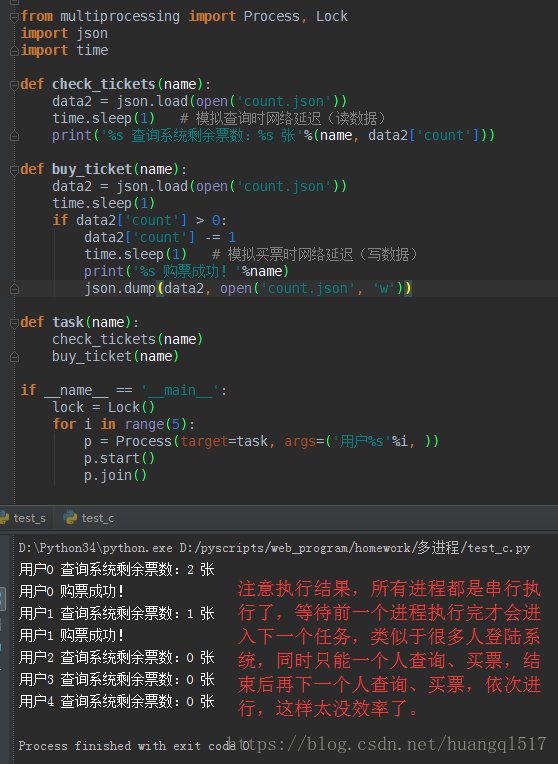
疑问点:互斥锁是把并发变成串行,join也可以把并发变成串行,为何不直接用join呢?
继续上面的例子,假设现在系统余票2张,5个人同时购买,引入join()执行结果如下:
再看下之前的互斥锁,如下
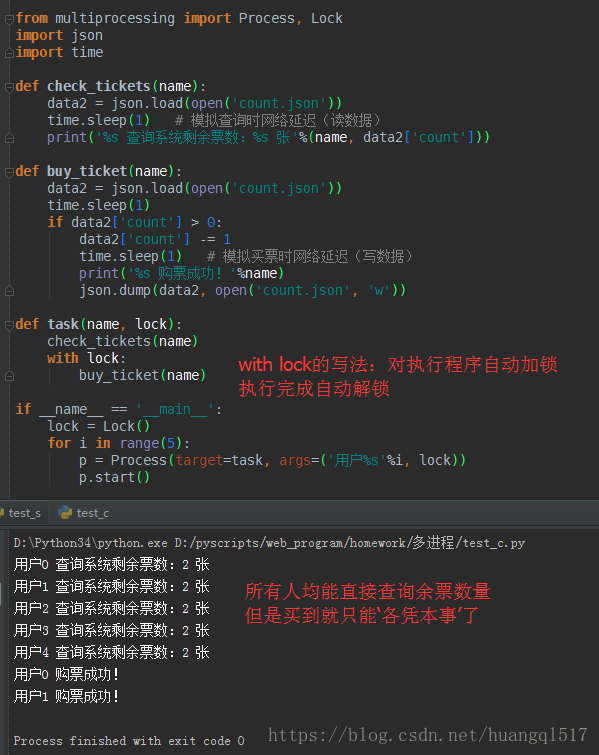
所以,对比下,就不难看出区别了:join是将一个任务整体串行,而互斥锁的则是可以将一个任务中的某一段代码串行,
比如上面的,只需要对写入数据串行,其他该并发的继续并发,保证效率。
3>队列
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行地修改,牺牲了速度却保证了
数据安全。
虽然可以用文件共享数据实现进程间通信,但是:1、效率低(共享数据基于文件,而文件是硬盘上的数据)
2、需要自己加锁处理
因此我们引入队列来解决这些问题:
1、效率高(多个进程共享一块内存的数据)
2、帮我们处理好锁问题。
3.2>什么是队列?
进程彼此之间互相隔离,要实现进程间通信(IPC),multiprocessing模块支持两种形式:队列和管道,
这两种方式都是使用消息传递的。
队列和管道都是将数据存放于内存中,而队列又是基于(管道+锁)实现的。
3.3>基本用法
3.3.1>Queue类及参数介绍
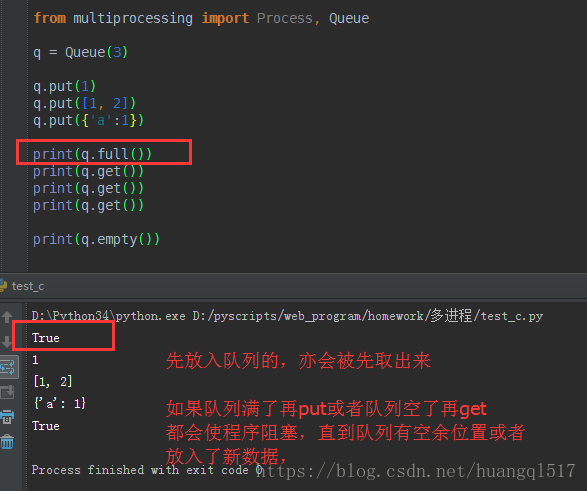
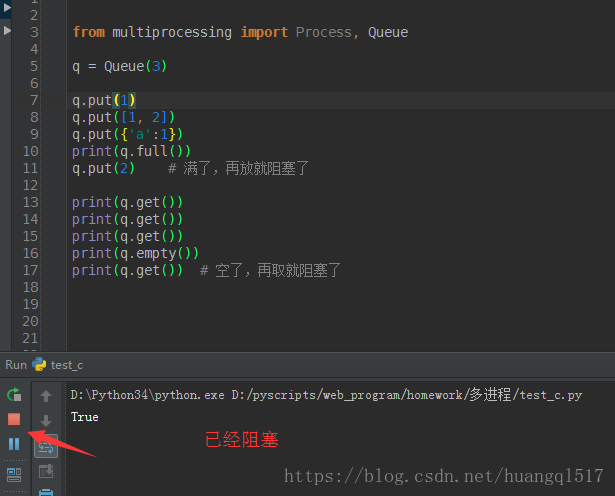
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
maxsize是队列中允许最大项数,省略则无大小限制(队列存的是消息而非大数据,队列占用的是内存空间,所以
即使不填写max值,大小也受限于内存大小)
q.put(),插入数据到队列中
q.get(),从队列读取数据并删除对应数据
q.full(),判断队列消息个数是都已达上限
q.empty(),判断队列中是否为空
4>生产者消费者模型
4.1>为什么要使用这个模型
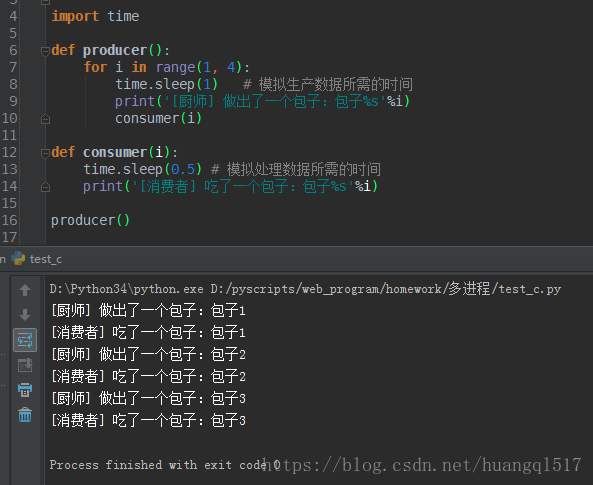
如上例子,生产者指的是生产数据的任务,消费者指的是处理数据的任务,在并发编程中,
如果生产者生产速度大于消费者处理速度,那么生产者就必须等待消费者处理完,才能继续生产数据。
反过来也一样,这将造成极大的资源浪费,为了解决这个问题于是引入了生产者和消费者模式。
4.2>什么是生产者消费者模型
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,生产者
生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,
而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
引入队列,改造程序如下
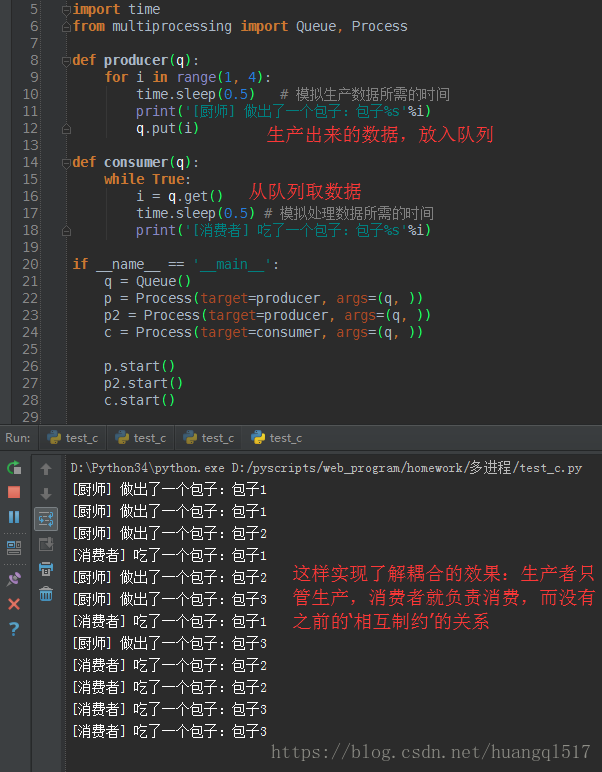
上面程序中还存在一个问题:程序被阻塞了,因为生产者始终都有生产范围(量的限定),但是消费者确实无限循环
去get数据,所以当队列为空时,get不到数据的时候,程序就阻塞了,
既然分析出问题是出在消费者这里,那么在最后一个有效数据送往队列之后,再发送一个‘结束指令’,然后让消费者
对接收到的‘结束指令’做相应处理,不就解决了?
4.3>正确但是比较low的解决之法如下:
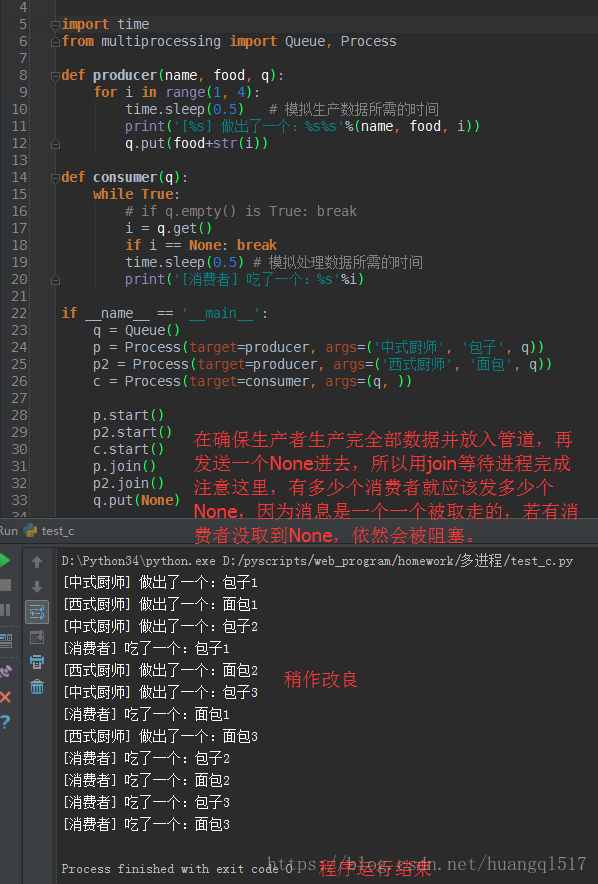
一些容易想到的错误的解法如下:
4.3.1>把结束指令放入函数里面,在生产数据完成之后,如下:
弊端:这样写只能保证该进程的数据正常传递完毕,却会影响其他并发进程,可以设想一下,再p.start()之后,所有
进程都等待操作系统分配资源去执行,极有可能就会出现进程1的数据生产完毕,但是其他进程还没有生产完毕,这时候
进程1传送了一个None过去,一个消费者收到None之后就不再get数据了,但其实后面还有很多(其他未完成的并发
进程)真实数据。
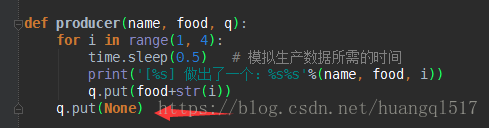
4.3.2>在消费者上面做判断,若管道为空就跳出循环,不再get
弊端:其实原因跟上面类似,因为不管是p.start还是c.start,都是给操作系统发指令去执行这些程序,但是具体怎么执行
,什么时候执行程序自身是无法控制或预知的。所以这个empty校验就可能出现在生产者之前,或者管道里暂时没有数据的
这么一个间隔,然后因为校验成功就退出了,很明显,也不合理
4.4>更高级的解决之法
如上4.3解决之法,有几个消费者就需要发送几次结束信号:比较low。下面引入JoinableQueue模块。
4.4.1>JoinableQueue类,类似Queue类,但它允许项目的使用者通知生成者项目已经被成功处理。
通知进程是使用共享的信号和条件变量来实现的。
4.4.2>参数介绍
JoinableQueue的对象除了与Queue对象相同的方法之外还具有:
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。
如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。
阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
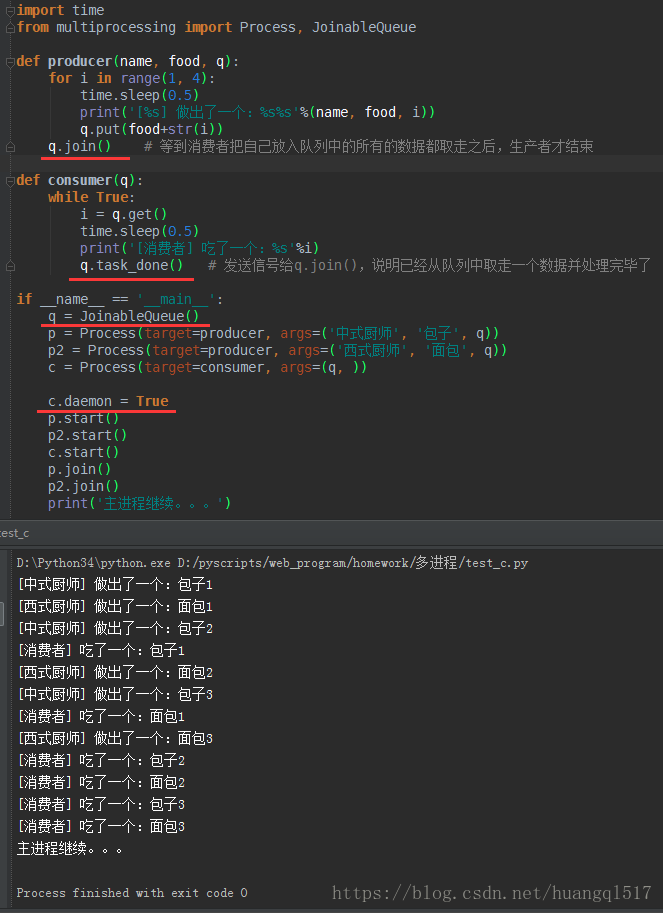
注意新增/改变的地方,分析:
1、主进程需等待p和p2结束,
2、p和p2结束的条件是当消费者把所有数据取走之后,处理数据会发送task_done信号
3、所以当p和p2结束的时候,消费者进程就没有继续存在的意义,所以把消费者进程设成守护进程。
4、这样,整个流程就是,p和p2和c进程开启,c处理完数据后,触发生产者的q.join(),生产者也结束,
触发自身的p.join(),进入主程序,此时守护进程c也随之终止,主程序继续。
所以,总结就是:引入生产这消费者模型解决的问题,1、平衡生产者和消费者的速度差;2、程序解耦。
引入容器----也就是队列来实现。