1、httrack使用方法
概念介绍: httrack 是一看网站镜像程序,也叫做扒皮工具。 使用者可以直接把互联网上的网站下载到本地计算机上,在默认的设置下,httrack对网站的下载方式是按照原站点子昂对的链接结构在组织的。httrack使用网络爬虫下载网站,对于用robots.txt的网站,如果不在程序运行时取消限制,默认设置下,程序不会把网站完全镜像,Httrack能够跟随基本的JavaScript、或者Applet、flash中的链接,但是对于复杂的链接(使用函数或者表达式创建的链接)或者服务器端的imageMap 则显得无能为力。imagemap控件是一个在图片上定义热点区域的控制器,用户可以点击这些热点区域进行回发(postback)操作或者定向到(navigate)到某一个url该控件主要用在对某张图片的操作定义属性有HotSpotMode、HotSpot、Click
最难点通配符的规则,wildcards(通配符) 举例子如下:
httrack "www.baidu.com" -w -o " *.gif+www.*.com/*.zip-*img_.*zip" -%v
httrack "http://xiaomi.blog.163.com" -o /home/back/www/" + ".xiaomi.163.com / * " -v

这里我就拿另一个mirror做例子,形象一点,打开一个我已经mirror的网站
2、Google搜索指令的应用
搜索指令,其实是根据不同的搜索引擎的底层设置来操作的。很多都是通用的,Google搜索指令大多在百度中适用,
详细的指令我之前在博客中已经写过,可以查看,重点写一些常见的
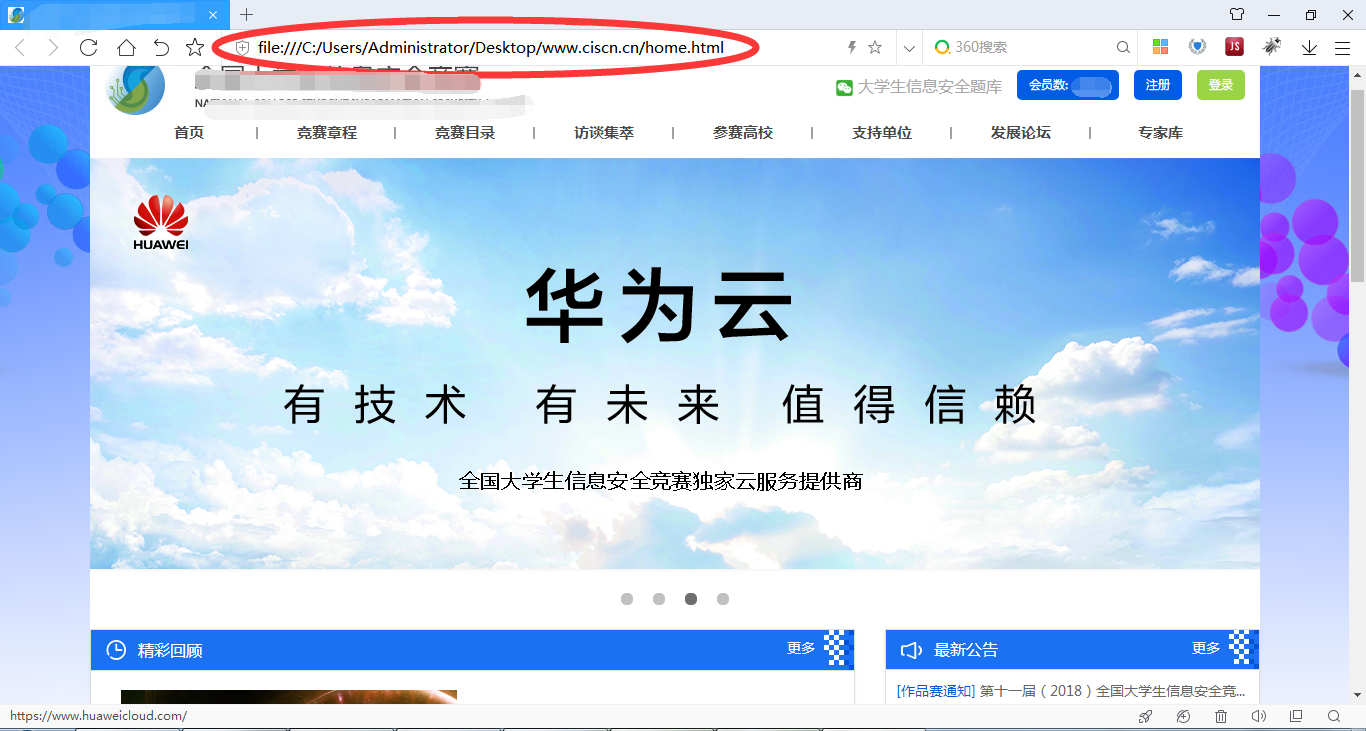
site:指令 网站内检索指令 eg、在兰州理工大学中检索我的名字 site:rjxy.lut.cn/ 我的名字

intitle,和allintitle是针对网页标题中搜索关键字,举例 在工大计通学院中检索网页标题中含有教授的所用网页链接

inrul:是在网页链接中搜索信息,网址中含有某种字符的链接 ,举例,记住每个检索字段之间要有空格
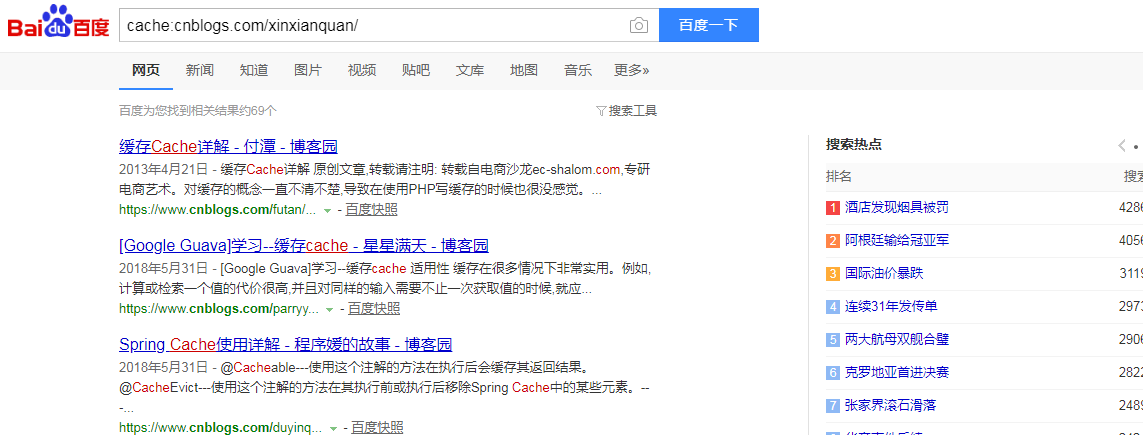
cache:指令是另外一个比较重要的指令,可以在引擎快照中搜索信息,举例在快照中搜索我的信息
filetype:这个我就不解释啦
3、使用whois命令旨在查询服务器信息,举一列查询兰州理工大学服务器信息
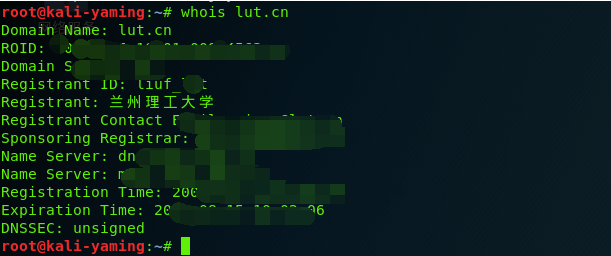
使用nslookup是查询电脑连接的一个最近端设备信息,今天我连接的是校园无线所以了什么都查不出

4、The Harvester挖掘邮箱地址信息,首先安装theharvester


如下是挖掘西安理工大学的邮箱,以及隐藏的二级域名,由于涉密安全,自动打码


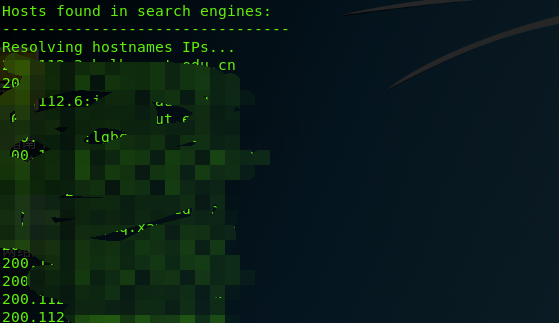
另外就是使用whois.net 网站对要查询的网站域名进行挖掘,该网站whois搜索出来具体的服务器信息,以及额外的信息,另外就是whois提供对url的引用,“url:(referral url:)”字段提供的链接地址做进一步搜索,利用safename的whois的服务。

另一个信息搜索的网站就是Netcraft,网站地址: http://news.netcraft.com

最后一个就是dig和host工具的使用,这个我不写了,百度一下。