引入
深度学习或机器学习模型,用于分类和回归任务,是我们很熟悉的用法。
目标检测任务,主要用于计算机视觉中,比如人体检测、车辆检测、人脸检测。目标检测的最终目标,是要在图像中找到检测对象的具体位置。

在传统的计算机视觉处理中,我们可以用连通体检测或SIFT等,通过一定的规则,找到检测对象。在深度学习中,我们是怎么找到检测对象的位置呢?
目标定位(Localization)
我们首先解释两个概念:
- Classification:分类问题,模型只需要输出label即可
- Localization:定位问题,模型需要输出检测对象的具体位置,比如(中心点x坐标,中心点y坐标,对象高度,对象宽度)。
对于目标定位问题(Localization),我们只需要在加Label(Y值)时,增加对位置信息的Label,如下例:
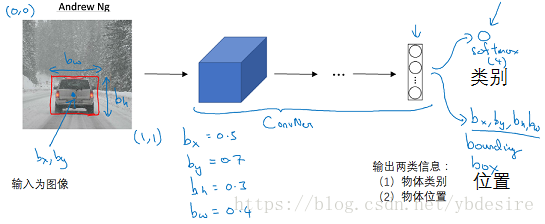
只需要对网络中的输出部分做简单改动:一个softmax做类别判断,一组其它神经元直接输出位置信息。注意位置信息被归一化为0到1之间的小数(便于网络处理,一般relu输出也是0~1之间)。
特征点检测(Landmark)
对于特征点检测(Landmark)问题,如下图,比如想检测人脸的关键区域特征(64个点),或者人体的骨骼特征(关节点和骨头线段):

本质上,也跟目标定位(Localization)一样,只需要在加Label时,把Y值标注为特征点的x-y坐标,直接训练模型,就可以。
目标检测
当图中有多个目标,想找到多个目标的位置,那目标定位就没法解决了(当然如果有很好的多目标标注Label,也可以做,但成本太高了)。
所以比较通用的深度学习目标检测问题,都是基于滑动窗口这种思路实现的:

这样只需要基于有对象和无对象的训练集,训练一个二分类器模型,就能实现目标检测。但这样需要多个不同大小的滑动窗口,每个窗口都要遍历图像上的所有场景,计算量非常大,所以早期的目标检测模型都用线性模型来做。这样用CNN之类的深度模型,计算量是非常大的。
总结
介绍了三种用深度网络做目标检测相关的方法:
目标定位:Label标记为检测对象坐标特征点检测:Label标记为每一个特征点的坐标目标检测:基于滑动窗口
Ref
本文图片来源于AndrewNG的深度学习课程,感谢Andrew。