将数据保存在数据库中,而不是出于安全原因,但要避免性能错误。通常,加速应用程序的最佳方法是让数据库服务器按照其设计要执行的操作:对数据进行操作。
大多数现代编程语言和框架将数据库隐藏在一个优雅,美丽的抽象层之后。今天的开发人员不需要编写甚至不需要理解数据库服务器的本地语言结构化查询语言(SQL)。我们认为SQL是20世纪70年代计算机科学的低级技术文献,最好留在学术期刊和大学教室中。
但是,不学习和深入理解SQL将是一个巨大的错误。事实上,许多与数据相关的性能问题都是使用高级语言(如Ruby或Python)来处理数据而不是SQL的结果。将您的数据保存在数据库中。使用数据库服务器对数据进行适当的操作,然后获取应用程序实际需要的结果。
让我用一个简单的例子向你展示我的意思。
帖子和评论
假设我有一对多关系的数据:一篇文章有很多评论。使用ActiveRecord,流行的Ruby ORM,我通过编写实现一对多关联:
class Post < ActiveRecord :: Base has_many :comments 结束 class Comment < ActiveRecord :: Base belongs_to :post end
Ruby强大的动态行为使我能够以一种非常自然的,人性化的方式查询给定帖子的评论:
post = Post .find(1) post.comments
但记住ActiveRecord不是一个神奇的框架。它没有与我的数据库中的表的秘密连接。它必须像其他人一样与数据库服务器通信,使用服务器的语言:SQL。读取我的日志文件,我可以看到ActiveRecord如何将post.comments转换为SQL:
选择评论。* from comments where where.post_id = 1
执行完此SQL语句后,ActiveRecord将结果集转换为一个Ruby对象数组,然后可以在我的代码中使用它。例如,如果我想要一篇文章的最新评论,我可以写:
一流的 邮政 高清 latest_comment comments.max {| a,b | a.updated_at <=> b.updated_at} 年底 结束
在这里,我要求Ruby对评论对象进行排序并返回最新的评论对象,评论的最大值为updated_at。现在,我可以通过写下以下内容来找到撰写最新评论的人:
post.latest_comment.author

我的数据在哪里?
这种方法的问题是它不能缩放。假设这篇文章有数百甚至数千条评论; 在这种情况下,ActiveRecord会将它们全部转换为Ruby对象,以便我可以在latest_comment方法中遍历它们 。
我的错误是让我的数据离开数据库。相反,我应该要求数据库为我完成这项工作。
让我们仔细看看latest_comment的工作原理:

在右边,我从数据库中的所有评论开始,成千上万的人说。接下来,我需要搜索与我的帖子相关的评论,并对post_id列进行过滤。这产生了一个子集,例如数百条评论。最后,我对这些过滤的评论进行排序并取最后一个,得到最新的评论。
我的Ruby解决方案的问题是我在数据库中执行过滤,但在Ruby中进行排序。在这之间,一篇文章的整个评论子集必须从数据库服务器传输到我的Ruby应用服务器:
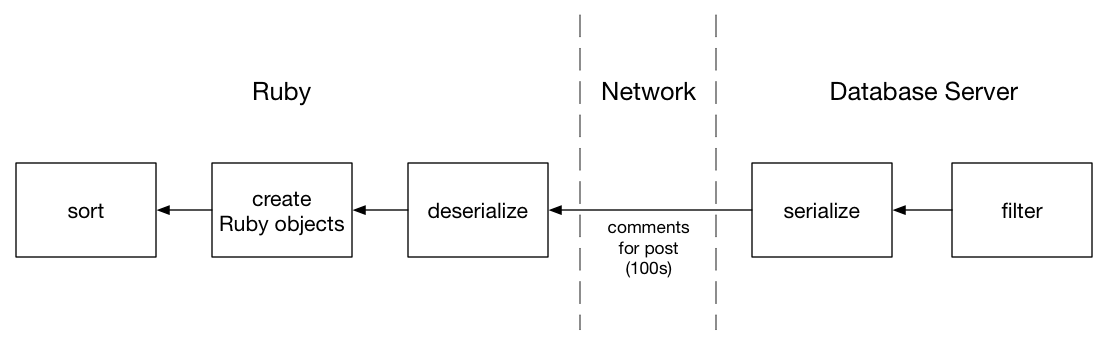
为了传输所有这些记录,数据库需要将它们序列化为一些二进制格式,这是我的Ruby代码(或我的数据库驱动程序实际上)以后需要解压缩的格式。最后,ActiveRecord必须将这个二进制数据转换成Ruby对象。
这个过程需要时间; 特别是创建数百或数千个Ruby对象涉及分配一系列内存结构并将它们放入一个大型数组中。使用称为“垃圾收集”的过程,Ruby甚至可能需要查找和回收旧的未使用的Ruby对象来保存注释,这需要更多时间。
数据库比你快
解决方案很明显:在数据库中执行搜索,只返回最新评论。但是,如何让我的数据库服务器搜索最新评论?通过使用ActiveRecord方法(如where, order和first来描述我想要的),而不是在Ruby中编写自己的代码。这条线将做的伎俩:
post.comments.order(的updated_at::降序)。首先
ActiveRecord将其转换为SQL代码,如下所示:
选择注释。* 从评论 其中 comments.post_id = 1个 顺序 通过 comments.updated_at 降序极限1
这将比我以前的解决方案运行得更快,因为我的数据库只通过网络将一条评论记录传输到我的Ruby服务器:最新的一个。Ruby仅创建一个Ruby对象,以获取最新评论:
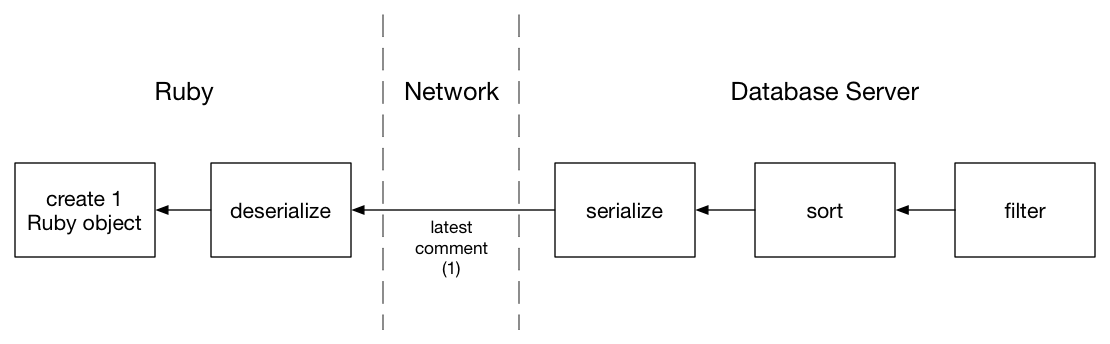
现在,高度优化的C代码运行在包含评论表数据的同一台服务器上,通过发布过滤评论,并按时间戳对匹配进行排序。多年来,该代码已被全世界数百万开发人员使用和测试; 不要试图通过使用Ruby自己重写类来重新发明轮子。
缓存最新评论
假设在我的用户界面中,我总是在每篇文章旁边显示最新评论的作者。现在要显示我的页面,我需要对每个帖子反复执行此评论搜索。一种完全避免评论查询的方法是在posts表中缓存最新评论的作者。这样,我会在加载帖子时自动获得最新评论的作者。无需重复搜索,或根本就不需要任何查询!
在实践中,如果我已经记住在post_id和updated_at列上创建索引,那么即使我执行了很多次,上面的注释搜索SQL也会很快运行。我甚至可以使用单个SQL查询加载所有帖子的最新评论,但为了今天的争论,我们仍然可以探索缓存解决方案。
ActiveRecord再次使这一点变得简单。我需要做的就是写这样的迁移:
class AddLatestCommentAuthorToPosts < ActiveRecord :: Migration def change add_column :posts,:latest_comment_author,:string end end
现在我只需要确保在用户每次写入新评论时更新帖子:
post.update_attribute(:latest_comment_author,“ 用户名”)
使用Ruby进行数据迁移
当然,我忘记了一些重要的东西。使用update_attribute我保存作者的任何新的评论,但所有现有的评论呢?如何为数据库中已有的所有评论设置此列的初始值?
足够简单:我只是添加一个方法到我的迁移,调用update_attribute。以下是如何做到这一点:
class AddLatestCommentAuthorToPosts < ActiveRecord :: Migration def change add_column :posts,:latest_comment_author,:string populate_latest_comment_authors 结束 def populate_latest_comment_authors 发布 .all.each do | post | latest_author = post.comments.order(的updated_at::降序).first.author post.update_attribute(:latest_comment_author,latest_author) 结束 端 端
由于您使用Ruby编写迁移,因此ActiveRecord可以简单而优雅地执行复杂转换。使用Ruby我得到所有帖子,迭代每个帖子,查找该帖子的最新评论,并更新最新的评论作者字段。
但是我犯了和以前一样的性能错误!在运行此迁移之后查看我的Rails日志,我发现一系列重复的SQL语句:
SELECT“comments”。* FROM“comments”WHERE“comments”。“post_id”= $ 1 ORDER BY“comments”。“updated_at”DESC LIMIT 1 [[“post_id”,2]] UPDATE“posts”SET“latest_comment_author”= $ 1,“updated_at”= $ 2 WHERE“posts”。“id”= 2 [[“latest_comment_author”,“Harry”],[“updated_at”,2015-06-17 13: 58:42.512160" ]] SELECT“comments”。* FROM“comments”WHERE“comments”。“post_id”= $ 1 ORDER BY“comments”。“updated_at”DESC LIMIT 1 [[“post_id”,3]] UPDATE“posts”SET“latest_comment_author”= $ 1,“updated_at”= $ 2 WHERE“posts”。“id”= 3 [[“latest_comment_author”,“Harry”],[“updated_at”,2015-06-17 13: 58:42.514676" ]] SELECT“comments”。* FROM“comments”WHERE“comments”。“post_id”= $ 1 ORDER BY“comments”。“updated_at”DESC LIMIT 1 [[“post_id”,1]] UPDATE“posts”SET“latest_comment_author”= $ 1,“updated_at”= $ 2 WHERE“posts”。“id”= 1 [[“latest_comment_author”,“Harry”],[“updated_at”,2015-06-17 13: 58:42.516071" ]]
再次,我已经将数据从数据库中删除了。通过使用Post.all加载所有帖子,并使用每个帖子 遍历它们,我触发了这一系列重复的SQL命令。现在我传输所有的发布数据,然后为我的数据库和我的Ruby应用程序之间的每篇文章来回更多的数据:
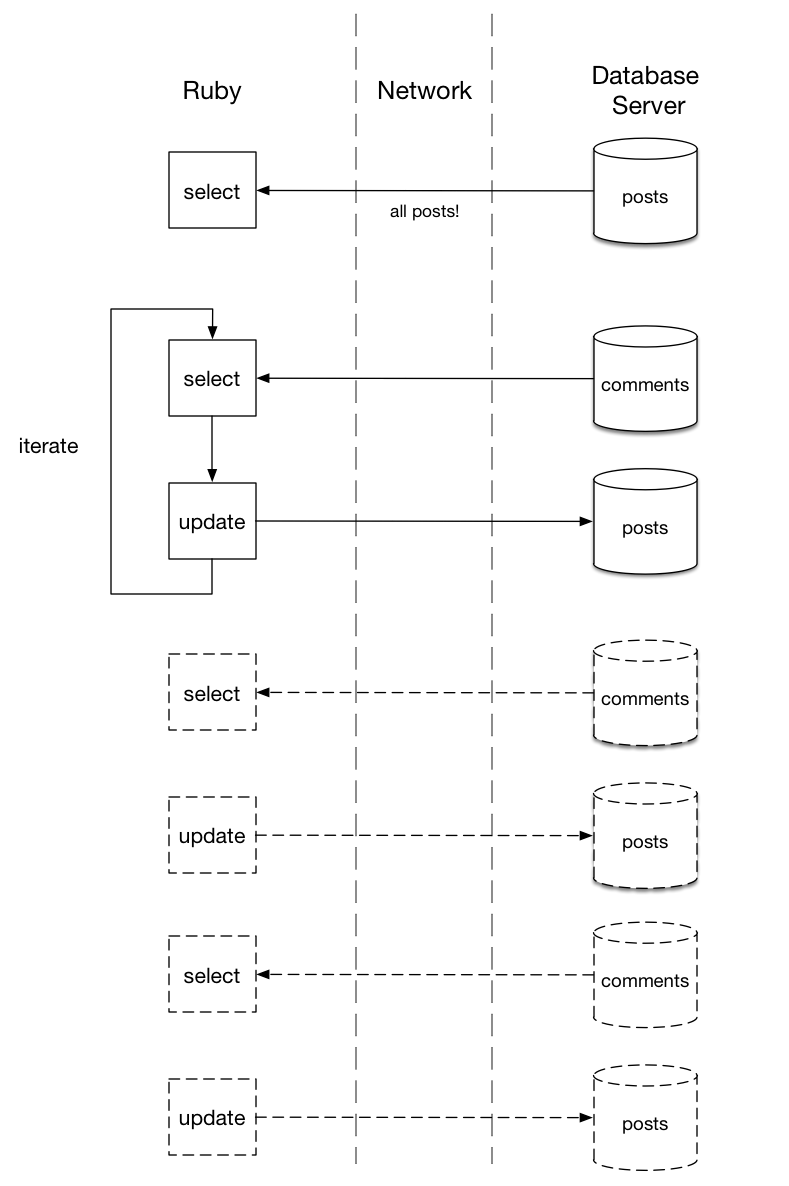
就像我以前的代码一样,这种迁移将表现不佳。如果我只有几个帖子,可能没关系。但想象一下,如果有数千甚至10万个帖子记录:此迁移可能需要几分钟甚至几小时才能完成!我的数据库服务器和Ruby需要为这些SQL命令中的每一个序列化,传输和反序列化数据。
一定会有更好的办法。
使用SQL进行数据迁移
解决方案与以前一样:不要让数据离开数据库。不要编写Ruby代码来更新每条帖子记录,而是要求数据库服务器执行此操作。我的数据库服务器已经以优化的格式存储了我的所有发布数据,可能会加载到内存中。它可以遍历帖子并更新它们。

但是如何?我如何要求数据库服务器更新所有帖子?我需要说出数据库的语言:SQL。通过直接编写SQL,我可以确定数据库正在做我想做的事,它使用了最有效的算法。我可以确定我的数据库和我了解对方。
以下是使用SQL更新所有帖子的一种方法:
更新帖子集 latest_comment_author =( 从评论 中选择作者where comments.post_id = posts.id order by comments.updated_at desc limit 1 )
这个微小的SQL程序实际上使用了类似于我在日志文件中重复发现的SQL命令。但是有一个重要的区别:这个SQL代码并没有提到硬编码的post ID值,比如1或者2.在这里我用一个命令更新了所有的帖子!
这个怎么用?让我们来看看:
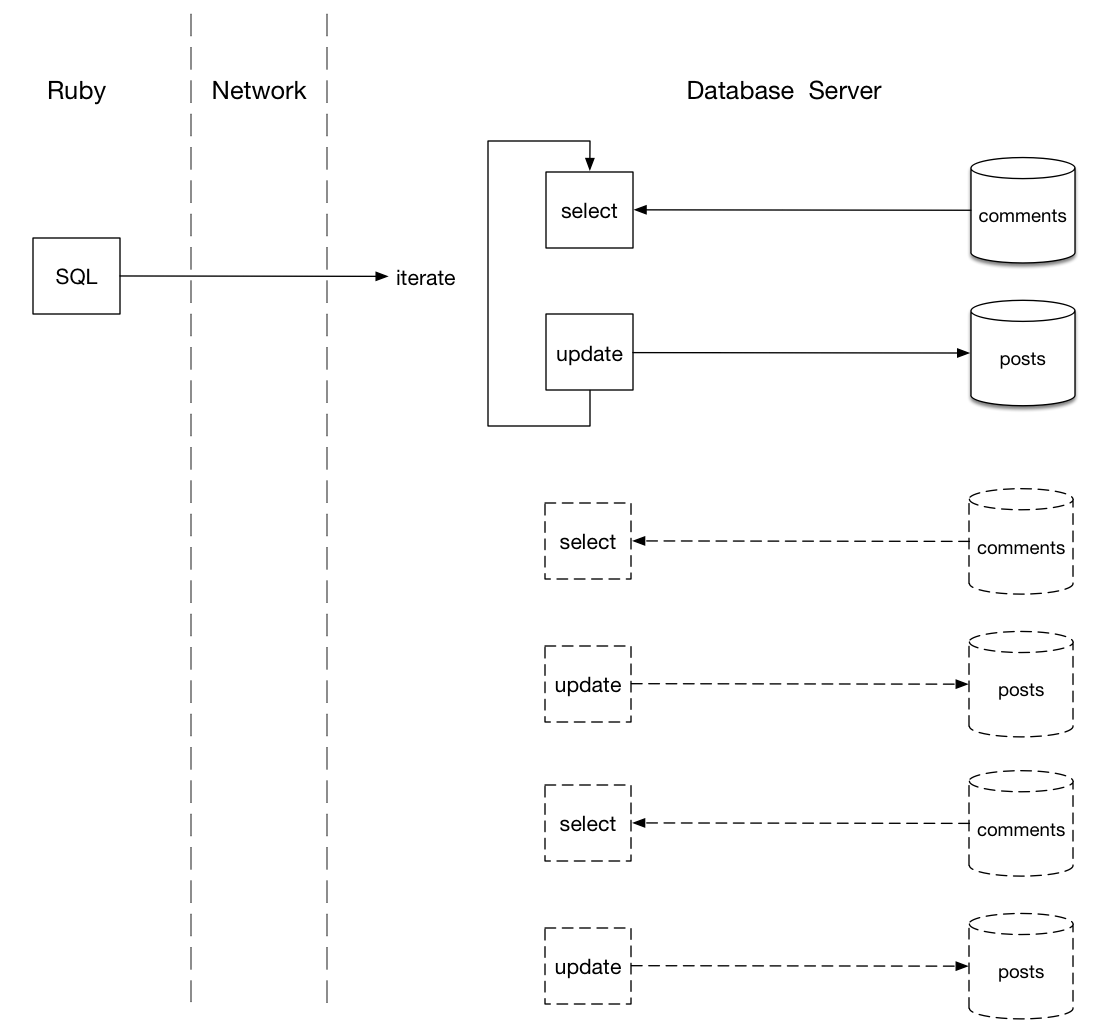
使用SQL迁移,我的Ruby代码向数据库服务器发送一条SQL命令,该命令通过网络传输到数据库。然后,在右侧,我的数据库服务器对posts表执行相同的迭代,为每个表选择最新的评论。
这看起来很相似,但是有一个重要的区别:迭代完全发生在数据库服务器内部。没有数据需要打包,传输到Ruby服务器并再次解压缩。实际上,执行重复SELECT语句的C代码 已经被编译为本地机器语言,并且运行速度非常快。获取最新评论后,它可以直接更新每篇文章,因为张贴表被存储在同一台服务器的硬盘驱动器中,甚至存储在内存中。
为什么SQL代码迭代?
您可能想知道为什么我在上面的数据库服务器中绘制了一个迭代。毕竟,我向数据库发送了一个包含1个UPDATE语句和1个SELECT 语句的简单命令。为什么我的数据库需要一遍又一遍地执行选择?
之所以这样,是因为我的SQL代码使用了相关的子查询,因为内部 SELECT使用了来自外部查询的值。这里再次提到SQL:

注意,内部SELECT语句引用了posts.id,这是一个来自周围UPDATE语句的值。这要求数据库服务器迭代所有的帖子,为每一行执行内部选择。我将把它作为练习让读者使用UPDATE-FROM语句,JOIN甚至Postgres窗口函数来重写,避免重复SELECT。
但是,请记住,评论表中的列中是否有索引,为每个帖子选择最新评论的迭代将非常快。它肯定会比通过网络从Ruby服务器发送重复的SELECT和UPDATE SQL语句快数千倍。
你需要学习SQL吗?
实际上,我可以使用Ruby代码编写此数据迁移。ActiveRecord提供了一组丰富的方法,甚至允许使用子选择的复杂查询。在极少数情况下,当ActiveRecord无法生成我需要的SQL时,我总是可以使用底层的Arel Ruby库。在实践中,你很少会真正需要在Rails应用程序中编写SQL代码。
那为什么要学习SQL?您应该学习SQL,因为它会让您深入了解数据库服务器的实际工作方式。您将了解数据库服务器可以做什么以及不能做什么。当你已经有一台服务器使用更强大和更复杂的算法来编写任何代码时,你不会试图重新发明轮子。
使用数据库服务器进行设计:解决数据问题。无论您是直接编写SQL还是使用ActiveRecord等工具自动生成SQL,都可以在数据库中执行所需的搜索,排序或计算。
除非您需要......直到您只有应用程序真正需要的值,否则不要将数据从数据库中移出。