递归算法
如果深入探讨递归,会有非常多的东西。在做这几个题的时候,使用递归能大大简化代码复杂度。在旧认知篇里面,自己提到了递归和迭代是等价的,更准确的说尾递归和迭代是等价的。然后做了以下几个题之后,我发现我似乎没有真正理解递归的精髓。本篇也是冰山一角,以后有时间再深入研究。
21. Merge Two Sorted Lists
已知mergeTwoLists返回两个链表合成后链表的头结点,则可以不断划分原问题成更小的子问题,充分利用上面已知的条件,可以写出下面的递归调用。虽然该递归非尾递归,但依然可以用迭代的方式实现。
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(l1 == NULL)
return l2;
if(l2 == NULL)
return l1;
if(l1->val > l2->val){
l2->next=mergeTwoLists(l1,l2->next);
return l2;
}
else{
l1->next=mergeTwoLists(l1->next,l2);
return l1;
}
}
};23. Merge k Sorted Lists
该题官网有很多其他的解法,但本文针对类似上题合并两个数的思路进行递归实现:
//未优化版本,和上一题的套路一样
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int record,i,val=99999;
for(i=0;i<lists.size();++i){
if(lists[i] != NULL && lists[i]->val <val){
record=i;
val=lists[i]->val;
}
}
if(val == 99999)
return NULL;
ListNode* tmp=lists[record];
lists[record]=lists[record]->next;
tmp->next=mergeKLists(lists);
return tmp;
}
};上面代码虽然AC,但是运行时间过长,可以进行优化:具有相同最小值的节点可以在一趟递归调用中进行处理:
//经过优化后的版本
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int record,i,val=99999;
for(i=0;i<lists.size();++i){
if(lists[i] != NULL && lists[i]->val <val){
record=i;
val=lists[i]->val;
}
}
if(val == 99999)
return NULL;
ListNode* head=lists[record],* pre=NULL;
for(i=0;i<lists.size();++i){
if(lists[i] != NULL && lists[i]->val ==val){
if(pre != NULL)
pre->next=lists[i];
pre=lists[i];
lists[i]=lists[i]->next;
}
}
pre->next=mergeKLists(lists);
return head;
}
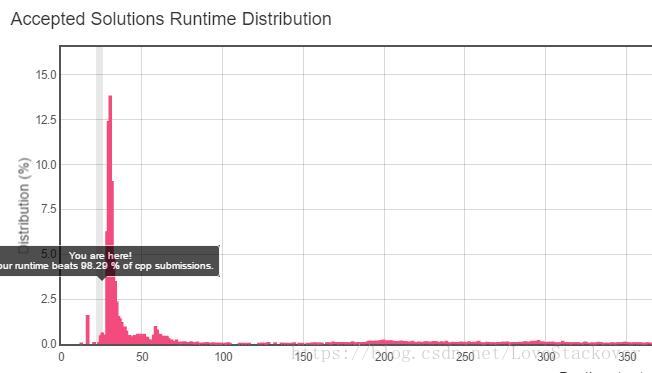
}; 如果借助其他数据结构,比如优先级堆可以进一步优化上面的时间复杂度,但是会增加空间消耗,以上两个代码的运行时间结果如下:

第二种只是做了一点点的优化,可以使运行时间提高10倍以上。与其他用户提交的代码相比较:
24. Swap Nodes in Pairs
已经swapPairs返回交换后链表的头结点,如何编写递归取决于如何划分子问题,本题中以2个节点为处理单元,递归调用解决:
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head == NULL|| head->next == NULL)
return head;
ListNode* tmp=head->next;
head->next=swapPairs(head->next->next);
tmp->next=head;
return tmp;
}
};25. Reverse Nodes in k-Group
与上面相同的思路,以k个节点为处理单元,并递归调用:
class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
if(head == NULL || k==0)
return head;
int count=0;
ListNode* tmp,* pre,* save;
for(tmp=head;tmp!= NULL && count< k ;tmp=tmp->next,++count);
if(count != k)
return head;
count=0;
for(tmp=head,pre=NULL;count< k;++count){
save=tmp->next;
tmp->next=pre;
pre=tmp;
tmp=save;
}
head->next=reverseKGroup(tmp,k);
return pre;
}
};小结
使用递归解决问题颇有动态规划的感觉,如何编程实现取决于如何拆分问题。21题和24题以两个节点拆分问题,23题和25题以k个节点拆分问题。不论怎么拆分问题,函数的返回结果一直是当前子问题的答案,这点很重要。再之后的82题、206题等都可以使用递归解决,到以后遇到的时候再次回顾。