这本笔记的参考书目和课程为:
《机器学习基础教程》:机械工业出版社
模式识别与机器学习(PRML)
统计学习方法:清华大学出版社,李航
Deep Learning:Ian Goodfellow,Yoshua Bengio,Aaron Counrville
斯坦福《机器学习公开课》吴恩达
之后的内容都是来源于这几本书的学习和一些反思,后面就不强调了。这里的机器学习默认是统计机器学习,后面也不再强调了。
一.统计学习方法概论
Ⅰ.背景
统计方法是从事物的外在数量上的表现去推断该事物可能的规律性。 科学规律性的东西一般总是隐藏得比较深,最初总是从其数量表现上通过统计分析看出一些线索,然后提出一定的假说或学说,作进一步深入的理论研究。当理论研究 提出一定的结论时,往往还需要在实践中加以验证。就是说,观测一些自然现象或专门安排的实验所得资料,是否与理论相符、在多大的程度上相符、偏离可能是朝哪个方向等等问题,都需要用统计分析的方法处理。
从1960年至1980年间,统计学领域出现了一场革命,要从观测数据对依赖关系进行估计,只要知道未知依赖关系所属的函数集的某些一般的性质就足够了。
60年代的四项发现:
Tikhonov, Ivanov 和 Philips 发现的关于解决不适定问题的正则化原则;
Parzen, Rosenblatt 和Chentsov 发现的非参数统计学;
Vapnik 和Chervonenkis 发现的在泛函数空间的大数定律,以及它与学习过程的关系;
Kolmogorov, Solomonoff 和Chaitin 发现的算法复杂性及其与归纳推理的关系。
Ⅱ.统计学习方法
统计学习(statistical learning)是关于计算机基于数据构建概率统计模型并且运用模型对数据进行预测与分析的一门学科.
统计学习的对象是数据,他从数据出发,提取数据的特性,抽象出数据的模型,发现数据中的知识,又回到对数据的分析与预测中去.
统计学习关于数据的基本假设是同类数据具有一定的统计规律性,这是统计学习的前提.有统计规律性才能够用概率统计的方式来处理.(比如用随机变量描述数据的特征,同概率分布描述数据的统计规律)
在统计学习的过程中以变量或者变量组表示数据.(当然可以分为连续变量和离散变量表示的类型)
统计学习的目标就是考虑学习什么样的模型和如何学习模型,使得能够对数据进行准确的预测与分析,同时考虑尽可能的提高学习效率.
统计学习由监督学习(supervised learning),非监督学习(unsupervised learning),半监督学习(semi-supervised learning)和强化学习(reinforcement learning)等组成.
统计学习方法可以概括为:
从给定的,有限的,用于学习的训练数据集合(数据是独立同分布产生的)出发;并且假设要学习的模型属于某个函数的集合,称为假设空间(hypothesis space);应用某个评价准则(evaluation criterion),从假设空间中选取一个最优模型,使它对已知训练数据及未知测试数据在给定的评价准则中有最优化的预测.
统计方法处理过程可以分为三个阶段:
( 1)搜集数据:采样、实验设计
( 2)分析数据:建模、知识发现、可视化
( 3)进行推理:预测、分类
常见的统计方法有:
回归分析(多元回归、自回归等)
判别分析(贝叶斯判别、费歇尔判别、非参数判别等)
聚类分析(系统聚类、动态聚类等)
探索性分析(主元分析法、相关分析法等)等
Ⅲ.统计学习一些概念
1.输入空间,特征空间和输出空间
将输入与输出所有可能取值的集合分别称为输入空间(***input space)与输出空间*(output space).输入空间和输出空间可以是同一个空间,也可以是不同的空间.一般来说,输出空间远远小于输入空间.
每个具体的输入数据也叫一个实例(instance)通常由特征向量(feature vector)表示.这时候,所有特征向量存在的空间称为特征空间(feature space).特征空间的每一维对应于一个特征.想到数据预处理这个过程,就相当于把未处理过得数据(raw data)抽取我们想要的特征(feature extraction)变换到特征空间上面去.输入空间与特征空间可以不同也可以相同,根据问题的需要来.
模型实际上都是定义在特征空间上面的.
然后很重要的就是输入样本的写法了。前面解释了特征向量的含义。一般用数学表示为
其中向量就是输入向量了(特征向量),其中的分量便是一个个的特征。这里用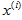
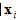
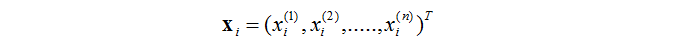
其实很简单。在监督学习中,每个输入向量还有一个对应的标签(label)来表示这个输入向量的“性质”(正样本负样本啊各种)。所以,一个输入样本可以写为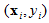
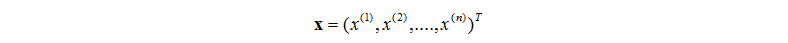
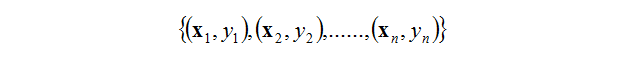
2.联合概率分布
假设输入和输出的随机变量X和Y遵循联合概率分布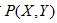
在学习过程中,假定这一联合概率分布存在,但是对于学习系统来说,这个概率分布的具体定义是未知的.
训练数据和测试数据被看做是依联合概率分布
假设学习假设数据存在一定的统计规律,X和Y具有联合概率分布的假设就是监督学习关于数据的基本假设.
3.假设空间
监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示.
模型输入由输入空间到输出空间映射的集合,这个集合就是假设空间(Hypothesis Space).假设空间的确定意味着学习范围的确定.
监督学习的模型可以是概率的或者是非概率的模型.由条件概率分布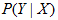
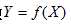
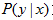
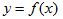
4.问题形式化
形式化1: 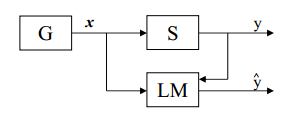
产生器(G):产生随机向量x Rn, 它们是从固,定但未知的概率分布函数F(x)中独立抽取的。
训练器Supervisor (S):对每个输入向量x 返回一个输出值y,产生输出的根据是同样固定但未知的条件分布函数 F(y|x)
学习机Learning Machine (LM):它能够实现一定的函数集其中是参数的集合。
关键概念: 学习的问题就是从给定的函数集中选择出能够最好地逼近训练器响应的函数。这种选择是基于训练集的,训练集由根据联合分布F(x,y)=F(x)F(y|x)抽取出的l个独立同分布( i.i.d) 观测(x1,y1), (x2,y2), … ,(xn,yn)组成.
形式化2:
监督学习利用训练数据集学习一个模型,再用模型对测试样本集进行预测.监督学习分为:学习和预测两个过程.由学习系统和预测系统完成.

Ⅳ.统计学习理论
1.统计学习理论是小样本统计估计和预测学习的最佳理论。
2.假设输出变量Y与输入变量X之间存在某种对应的依赖关系,即一未知概率分布P(X,Y),P(X,Y)反映了某种知识。学习问题可以概括为:根据L个独立同分布( independently drawn and identically distributed )的观测样本(train set),学习样本的函数.
这本笔记的参考书目和课程为:
《机器学习基础教程》:机械工业出版社
模式识别与机器学习(PRML)
统计学习方法:清华大学出版社,李航
Deep Learning:Ian Goodfellow,Yoshua Bengio,Aaron Counrville
斯坦福《机器学习公开课》吴恩达
之后的内容都是来源于这几本书的学习和一些反思,后面就不强调了。这里的机器学习默认是统计机器学习,后面也不再强调了。
一.统计学习方法概论
Ⅰ.背景
统计方法是从事物的外在数量上的表现去推断该事物可能的规律性。 科学规律性的东西一般总是隐藏得比较深,最初总是从其数量表现上通过统计分析看出一些线索,然后提出一定的假说或学说,作进一步深入的理论研究。当理论研究 提出一定的结论时,往往还需要在实践中加以验证。就是说,观测一些自然现象或专门安排的实验所得资料,是否与理论相符、在多大的程度上相符、偏离可能是朝哪个方向等等问题,都需要用统计分析的方法处理。
从1960年至1980年间,统计学领域出现了一场革命,要从观测数据对依赖关系进行估计,只要知道未知依赖关系所属的函数集的某些一般的性质就足够了。
60年代的四项发现:
Tikhonov, Ivanov 和 Philips 发现的关于解决不适定问题的正则化原则;
Parzen, Rosenblatt 和Chentsov 发现的非参数统计学;
Vapnik 和Chervonenkis 发现的在泛函数空间的大数定律,以及它与学习过程的关系;
Kolmogorov, Solomonoff 和Chaitin 发现的算法复杂性及其与归纳推理的关系。
Ⅱ.统计学习方法
统计学习(statistical learning)是关于计算机基于数据构建概率统计模型并且运用模型对数据进行预测与分析的一门学科.
统计学习的对象是数据,他从数据出发,提取数据的特性,抽象出数据的模型,发现数据中的知识,又回到对数据的分析与预测中去.
统计学习关于数据的基本假设是同类数据具有一定的统计规律性,这是统计学习的前提.有统计规律性才能够用概率统计的方式来处理.(比如用随机变量描述数据的特征,同概率分布描述数据的统计规律)
在统计学习的过程中以变量或者变量组表示数据.(当然可以分为连续变量和离散变量表示的类型)
统计学习的目标就是考虑学习什么样的模型和如何学习模型,使得能够对数据进行准确的预测与分析,同时考虑尽可能的提高学习效率.
统计学习由监督学习(supervised learning),非监督学习(unsupervised learning),半监督学习(semi-supervised learning)和强化学习(reinforcement learning)等组成.
统计学习方法可以概括为:
从给定的,有限的,用于学习的训练数据集合(数据是独立同分布产生的)出发;并且假设要学习的模型属于某个函数的集合,称为假设空间(hypothesis space);应用某个评价准则(evaluation criterion),从假设空间中选取一个最优模型,使它对已知训练数据及未知测试数据在给定的评价准则中有最优化的预测.
统计方法处理过程可以分为三个阶段:
( 1)搜集数据:采样、实验设计
( 2)分析数据:建模、知识发现、可视化
( 3)进行推理:预测、分类
常见的统计方法有:
回归分析(多元回归、自回归等)
判别分析(贝叶斯判别、费歇尔判别、非参数判别等)
聚类分析(系统聚类、动态聚类等)
探索性分析(主元分析法、相关分析法等)等
Ⅲ.统计学习一些概念
1.输入空间,特征空间和输出空间
将输入与输出所有可能取值的集合分别称为输入空间(***input space)与输出空间*(output space).输入空间和输出空间可以是同一个空间,也可以是不同的空间.一般来说,输出空间远远小于输入空间.
每个具体的输入数据也叫一个实例(instance)通常由特征向量(feature vector)表示.这时候,所有特征向量存在的空间称为特征空间(feature space).特征空间的每一维对应于一个特征.想到数据预处理这个过程,就相当于把未处理过得数据(raw data)抽取我们想要的特征(feature extraction)变换到特征空间上面去.输入空间与特征空间可以不同也可以相同,根据问题的需要来.
模型实际上都是定义在特征空间上面的.
然后很重要的就是输入样本的写法了。前面解释了特征向量的含义。一般用数学表示为
其中向量就是输入向量了(特征向量),其中的分量便是一个个的特征。这里用
其实很简单。在监督学习中,每个输入向量还有一个对应的标签(label)来表示这个输入向量的“性质”(正样本负样本啊各种)。所以,一个输入样本可以写为
2.联合概率分布
假设输入和输出的随机变量X和Y遵循联合概率分布
在学习过程中,假定这一联合概率分布存在,但是对于学习系统来说,这个概率分布的具体定义是未知的.
训练数据和测试数据被看做是依联合概率分布
假设学习假设数据存在一定的统计规律,X和Y具有联合概率分布的假设就是监督学习关于数据的基本假设.
3.假设空间
监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示.
模型输入由输入空间到输出空间映射的集合,这个集合就是假设空间(Hypothesis Space).假设空间的确定意味着学习范围的确定.
监督学习的模型可以是概率的或者是非概率的模型.由条件概率分布
4.问题形式化
形式化1:
产生器(G):产生随机向量x Rn, 它们是从固,定但未知的概率分布函数F(x)中独立抽取的。
训练器Supervisor (S):对每个输入向量x 返回一个输出值y,产生输出的根据是同样固定但未知的条件分布函数 F(y|x)
学习机Learning Machine (LM):它能够实现一定的函数集其中是参数的集合。
关键概念: 学习的问题就是从给定的函数集中选择出能够最好地逼近训练器响应的函数。这种选择是基于训练集的,训练集由根据联合分布F(x,y)=F(x)F(y|x)抽取出的l个独立同分布( i.i.d) 观测(x1,y1), (x2,y2), … ,(xn,yn)组成.
形式化2:
监督学习利用训练数据集学习一个模型,再用模型对测试样本集进行预测.监督学习分为:学习和预测两个过程.由学习系统和预测系统完成.
Ⅳ.统计学习理论
1.统计学习理论是小样本统计估计和预测学习的最佳理论。
2.假设输出变量Y与输入变量X之间存在某种对应的依赖关系,即一未知概率分布P(X,Y),P(X,Y)反映了某种知识。学习问题可以概括为:根据L个独立同分布( independently drawn and identically distributed )的观测样本(train set),学习样本的函数.