词向量
词向量是自然语言处理(Natural Language Processing)中的一组语言建模和特征学习技术的名称,其中来自语料库的单词短语对应着唯一的多维向量。理论上,词向量涉及到了从每一个单词的高维度向量空间到低维度的连续向量空间的多维向量。生成这种映射的方法包括降维词共现矩阵,神经网络,基于概率的模型以及单词所在语境显示。已经有研究表明,单词和短语向量作为基础输入表示时,可以提高NLP任务的性能,如句法分析和情感分析。
最初的词向量是冗长的,它使用的是词向量维度大小为整个单词表的大小,对于每个具体的单词,将其对应位置置1。如一个由6个单词组成的单词表,单词“北京”序号为1,“上海”序号为2,“南京”序号为3,则它们的词向量为(1,0,0,0,0,0),(0,1,0,0,0,0)和(0,0,1,0,0,0)。这种编码称之为离散表示(One hot representation)。显然,对于中文词库,需要的向量维数过于庞大,但也带来一个好处,就是在高维向量中,很多应用任务线性可分。
分布式表示(Dristributed representation)可以解决离散表示所带来的问题。它的思路是通过对于给定的某一特定自然语言的语料库进行训练,将语料库中每个单词都映射到一个相对维度较低的词向量上来。这些单词构成的低维向量集合构成了一个自然语言的向量空间,进而可以用统计学的方法来研究词与词之间的潜在关系。这个低维的词向量的维度一般需要我们在训练时自己来指定。如对于上文同样的6个单词的单词表,“北京”的词向量可能为(0.9,0.19,0.25),“上海”的词向量可能为(0.9,0.31,0.85),这样子就完成了较低维度的词向量来表示较多的单词,这个低维词向量的维度和具体值在不同的实际情况中有所不同。这种方式的词向量模型使得各个单词之间有了相似关系,对于自然语言处理产生帮助。
目前的词向量(通常是向量空间模型)的主要限制之一是单词的可能含义被合并成单个表示(语义空间中的单个矢量)。基于感知的词向量模型是解决这个问题的方法:单词的单词意义在向量空间中表示为不同的向量。但是目前来说发展较为局限,进展缓慢。
目前仍有许多科研人员和高校研究院在研究词向量模型的优化与降维。 2013年,Google公司计算机科学家Tomas Mikolov领导的一个科研团队创建了word2vec,这个词向量工具包可以比以前的方法更快地训练矢量空间模型。目前来说,许多新兴词向量技术更多的依赖于神经网络,替代了早期广泛流行的n-gram模型和无监督学习模型。
word2vec与自然语言模型
word2vec(word to vector)是Google公司于2013年推出的用于自然语言处理的深度学习开源训练集,是一组用于训练生成词向量的模型, 该神经网络模型层数不多,一般为两层,经过训练可重构语言的语境。word2vec用于将单词转换为多维词向量。它可以将百万数量级的语料库进行高效训练,通过所给语料库中各个单词的位置和词频等信息算出各个词向量。我们可以根据向量与向量之间的关系,来分析单词与单词之间的关系,挖掘文档中单词的联系。word2vec将输入的大量文本作为输入,并生成一个向量空间,通常为几百个维度,每个唯一的单词在语料库中被分配一个相应的空间向量。词向量位于向量空间中,使得在语料库中共享公共上下文的词在空间中彼此靠近。
自然语言模型,就是通过对自然语言的单词,句子进行建模,表示为计算机可以理解并处理的数学语言,使得计算机将其视为机器语言,并使用机器语言的处理方式来处理并分析人类的自然语言。word2vec可以利用两种模型架构中的任何一种来产生分布式的词语表达:CBOW连续词袋(continuous bags of words)模型或连续跳跃词(skip-gram)模型。在连续词袋结构中,模型从周围环境词的窗口中预测当前词,上下文词语的顺序不影响预测(词袋假设)。在连续跳跃式体系结构中,模型使用当前词来预测环境词的周围窗口。skip-gram体系结构权衡附近的上下文词语比距离更远的上下文词语重。相对来说,CBOW速度快,而skip-gram速度较慢,但对于处理不常见的词语,后者做得更好。
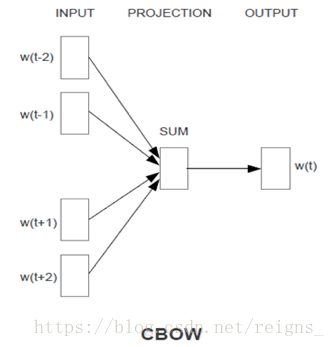
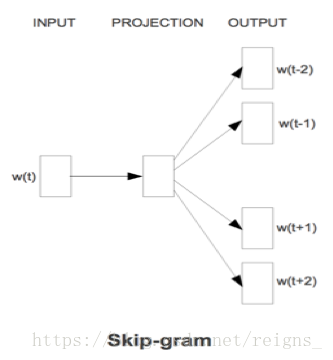
模型训练
Python中word2vec的模型训练十分简单,我们只需导入gensim.models下的word2vec包,并使用之前获取的已分词的维基百科中文语料库进行训练,得到可用于中文文档的词向量模型。代码如下:
from gensim.models import word2vec
import logging
logging.basicConfig(format = '%(asctime)s : %(levelname)s : %(message)s', level = logging.INFO)
sentences = word2vec.LineSentence(u'./cut_zh_wiki_00.txt')
model = word2vec.Word2Vec(sentences, size=200, window=10, min_count=64, sg=1, hs=1, iter=10, workers=25)
model.save(u'./word2vec2');其训练时间较长,本人的计算机配置(2.8GHz四核 Intel Core i7,16GB内存,Intel HD Graphics 630 1536 MB)所需要训练时间约为3小时。训练结束,我们得到了基于维基百科中文语料的中文词向量模型word2vec2。接下来我们使用一组简单的单词来测试模型。测试代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from gensim.models import word2vec
model = word2vec.Word2Vec.load("word2vec2")
s = model.similarity(u'南京', u'上海')
print "'南京'与'上海'的相似度为:",s
s = model.similarity(u'南京', u'北京')
print "'南京'与'北京'的相似度为:",s
print
print("与'南京'最相近的单词:")
result = model.most_similar(u'南京')
for each in result:
print each[0], each[1]
print
print("与'邮电'最相近的单词:")
result = model.most_similar(u'邮电')
for each in result:
print each[0], each[1]
print
print("与'大学'最相近的单词:")
result = model.most_similar(u'大学')
for each in result:
print each[0], each[1]结果如下图:
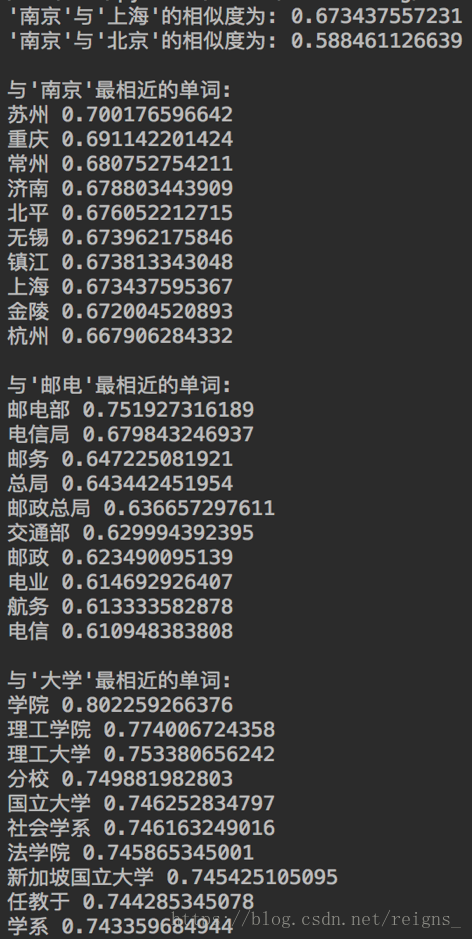
可以根据实际情况分析,我们训练出的模型的词向量关系可信度较高,也说明维基百科中文语料库的资料较为准确,可以用于接下来的自动文摘研究。