一、集合
from builtins import print
list_1 = [1, 3, 4, 5, 4, 3, 7, 9, 6, 8]
# 列表转集合,可以去掉重复的数据
list_1 = set(list_1)
list_2 = set([2, 6, 0, 66, 22, 8, 4])
print(list_1, list_2)
# 交集
print(list_1.intersection(list_2))
print(list_1 & list_2)
# 并集并去掉重复的数据
print(list_1.union(list_2))
print(list_1 | list_2)
# 差集 将list_1在list_2中有的元素去掉
print(list_1.difference(list_2))
print(list_1 - list_2)
# 子集
list_3 = set([1, 4, 6])
print(list_1.issubset(list_2))
print(list_1.issuperset(list_2))
print(list_3.issubset(list_1))
# 对称差集 将list_1和list_2都有的去掉,其它的合并在一起
print(list_1.symmetric_difference(list_2))
print(list_1 ^ list_2)
# 判断是否有交集,没有返回为True
list_4 = set([5, 7, 9])
print(list_3.isdisjoint(list_4))
# 添加
list_1.add(999)
list_1.update([888, 777, 666])
print(list_1)
# 删除,如果不存在,就报错
list_1.remove(999)
print(list_1)
# 长度
print(len(list_1))
# 测试是否是成员
print(888 in list_1)
# 测试不是成员
print(1000 in list_1)
# 随机删除,并返回这个元素
print(list_1.pop())
# 删除,如果不存在,不会报错
print(list_1.discard(1000))
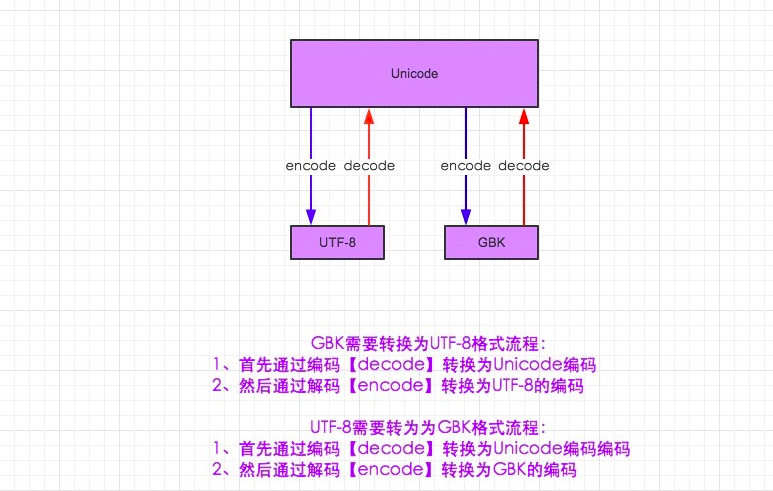
二、编码
# coding:utf-8
# Author:White Bai
# 虽然声名文件为utf-8 但变量 s 仍然为unicode(python3)
s = '你好'
print(s.encode('utf-8'))
三、文件操作
data = open('news', encoding="utf-8").read()
# f 文件句柄 文件内存对象
# r:只读模式
f = open('news', 'r', encoding="utf-8")
# 读取所有内容
data = f.read()
data2 = f.read()
print(data)
print("-------data2-------")
# 文件指针已经读到最后,所以data2没有读出任何数据
print(data2)
f.close()
# w:创建新文件,如果文件存在,将原来的内容覆盖
f = open('news1', 'w', encoding="utf-8")
f.write('123456\n')
f.write('7890')
f.close()
# a:追加模式,只能写不能读
f = open('news1', 'a', encoding="utf-8")
f.write('123456\n')
f.write('7890')
f.close()
f = open('news', 'r', encoding="utf-8")
# 读取一行数据
data = f.readline()
print(data)
# 将数据读取到列表中,每天为一个元素,这种不能读大文件
data = f.readlines()
print(data)
# 高效循环 一行一行的读取,内存中只保存一行数据,可以处理大文件
for line in f:
print(line)
# 文件指针位置
print(f.tell())
print(f.readline())
print(f.tell())
# 移动文件指针位置
f.seek(0)
print(f.tell())
# 返回文件编码
print(f.encoding)
# 返回文件句柄的编号
print(f.fileno())
# 判断是否可以文件指针
print(f.seekable())
# 判断文件是否可读
print(f.readable())
# 写模式,将文件缓冲区的数据写到硬件
print(f.flush())
f = open('news', 'w', encoding="utf-8")
# 文件截断,不写参数就是清空,有参数时例10,从送截10个字符
f.truncate(10)
# r+:读写模式 先读再写
f = open('news1', 'r+', encoding='utf-8')
print(f.readline())
print(f.readline())
print(f.readline())
f.write('------ddd------')
# w+:写读模式,先写再读,没什么用
f = open('news1', 'w+', encoding='utf-8')
print(f.readline())
print(f.readline())
print(f.readline())
f.write('------ddd------')
# a+:追加读写模式
f = open('news1', 'a+', encoding='utf-8')
# rb:读二进制文件,比如视频
f = open('news1', 'rb')
print(f.readline())
print(f.readline())
print(f.readline())
# wb:写二进制文件
f = open('news1', 'wb')
f.write("hello binary\n".encode())
四、文件修改
f = open('news', 'r', encoding='utf-8')
f_new = open('news.bak', 'w', encoding='utf-8')
for line in f:
if 'CEEC' in line:
line = line.replace('CEEC', 'OFFO')
f_new.write(line)
f.close()
f_new.close()
# 当语句执行超出with范围后,文件会自动close
with open('news', 'r', encoding='utf-8') as f, \
open('news1', 'r', encoding='utf-8'):
for line in f:
print(line)
五、函数
# 无参函数定义
def test():
"""文档说明,无参函数定义"""
s = '函数体'
print(s)
# 函数调用
test()
# 有参函数定义
def test(x, y):
"""文档说明,有参函数定义"""
print(x)
print(y)
# 有返回值参函数定义
def test(x, y):
"""文档说明,有参函数定义"""
print(x)
print(y)
return x + y
# 有参函数调用
# 按位置传参,形参与实参一一对应
test(1, 2)
# 关键字传参,形参与实参的位置无关
test(y=2, x=1)
# 位置传参与关键字传参同时使用时,关键字传参不能写在位置传参之前
test(1, y=2)
def test(x, y, z):
print(x, y, z)
# 这样调用也是可以的
test(1, z=6, y=2)
# 默认参数,如果不传相应的参数,就使用定义形参的默认值
def test(x, y=2):
print(x)
print(y)
test(1)
# 元组参数组定义 *args参数组只能接收n个位置参数,不能接收关键字参数,转换成元组方式
def test(*args):
print(args)
test(1, 2, 3, 4, 5)
test(*[1, 2, 3, 4])
# 字典参数组定义 **args参数组只能接收n个关键字参数,不能接收位置参数 把关键字参数转换成字典的方式
def test(**kwargs):
print(kwargs)
test(name='a', age=19)
test(**{'name': 'a', 'age': 19})
# 字典参数组与位置参数结合使用
def test(name, **kwargs):
print(name)
print(kwargs)
test('a')
test('a', age=18, sex='M')
# 字典参数组与位置参数结合使用
def test(name, age=18, **kwargs):
print(name)
print(age)
print(kwargs)
test('a', sex='m', hobby='tesla')
test('a', sex='m', hobby='tesla', age=3)
# 字典参数组、元组参数组与位置参数结合使用
def test(name, age=18, *args, **kwargs):
print(name)
print(age)
print(args)
print(kwargs)
test('a', 19, 'b', 'c', sex='M')
# 全局变量 在顶级定义的变量就是全局变量
school = 'abc'
# 局部变量 只在函数中生效,函数就是局部变量的作用域
def change_name(name):
print("before change:", name)
# school = 'sadf'
# 在函数内修改全局变量,尽量不要在函数内修改全局变量,但不应该在函数内定义新的全局变量
# 全局变量与局部变量同名时,调用变量时采用就近原则
global school
school = 'abcd'
name = 'Alex Li'
print("after change:", name)
name = 'alex'
change_name(name)
print(name)
print('school:', school)
# 引用类型的数据可以被修改,简单类型的数据不可以修改
names = ['a', 'b', 'c']
def change_name():
names[0] = 'd'
change_name()
print(names)
# 递归函数 效率低,不推荐使用
def calc(n):
print(n)
if int(n/2) > 0:
return calc(int(n/2))
calc(10)
# 高阶函数 将函数当作另一个函数的参数,这样的函数就是高阶函数
def add(a, b, f):
return f(a)+f(b)
res = add(3, -6, abs)
print(res)
# 字符串转字典
a = '''{
'bakend': 'www.baidu.com',
'record': {
'server': '100.1.7.8',
'weight': 20,
'maxconn': 30
}
}
'''
print(type(a))
a = eval(a)
print(type(a))