Hadoop HBase存储原理结构学习
一 .简介
- 介于nosql和关系型数据库之间
- 表大、面向列、稀疏,空值列,并不占用存储空间
二. 逻辑视图
逻辑视图区别于具体在物理机上的存储,表现为数据库表的行列等概念;
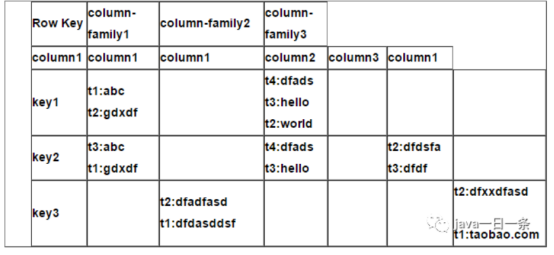
行键、列族、时间戳
- 行键:
存储按行键的字典顺序存储;--关系到表设计(尽量让热点事件不要按时间来设计,不然排到最下面,就是最旧的数据,查询任务是80%分在新数据上,这样容易造成突如其来的访问,造成集群宕机。如:微博因为鹿晗的事件访问造成集群宕机)
- 列名属于列族,
列族不超过3个,设计通常为一个;
访问控制、磁盘、内存统计都是列族层面进行;
- l时间戳
数据版本的索引;
不同版本的数据按时间倒叙排序,最新的数据排最前;
- lcell
无数据类型,底层二进制存储
三. 物理存储
- 行按rowkey 字典顺序
- Table行方向分割为Hregion;
- 每个表刚开始只有一个Hregion,随数据增长,达到阈值,Hregion分裂为两个;反复,会分裂成多个Hregion
- Hregion是分布式存储和负载均衡的最小单元。不同的Hregion可以分布在不同的Hregion server上,一个不会存储多个上;
- 0-多个StoreFile+1 个memStore--->Strore--->1个或多个Store-->HRegion
StoreFile==HFile--存储HDFS上
Store==一个conlumns 列族
HFile:
DataBlocks--DataIndex;
MetaBlocks--MetaIndex;
FileInfo
Trailer:
保存每段偏移量;
读取HFile---读取Trailer--DataBlock Index被读取到内存---检索key---从内存中找到key所在block;
HLog:
记录了数据的修改;
每个RegionServer 一个Hlog,减少磁盘寻址次数;
四. 系统架构
- lHbase的模型:
一个master节点协调管理一个或多个regionserver从属机;
Master:
负责启动一个全新的安装,把区域分配给注册的regionserver;
恢复regionserver的故障;
负载轻
Regionserver:
负责零个或多个区域region的管理及响应客户端的读写要求;
负责区域region的划分,并通知HBase master有新的子区域region;
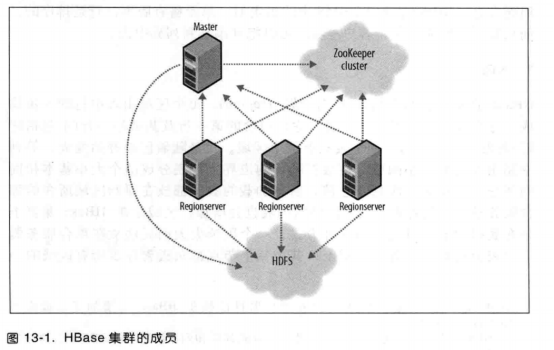
- l如果区域分配过程中有服务器崩溃,可通过ZooKeeper来进行分配的协调;
- Hbase通过Hadoop文件系统API来持久化存储数据
五. 关键算法/流程
运行中的HBase:
- 保留了特殊目录:维护了集群上所有region列表、状态和位置
- --ROOT表--META区域
- --META--区域
客户段查找过程:
META+region+regionserver
连接ZooKeeper集群--查找--ROOT位置--获取META--获取Region---客户端和regionserver交互;
读取---查看区域的memstore--找到需要的版本,查询结束;
- 客户端会缓存查找信息,查找从缓存找;
- 发生错误,或者区域被移动---获取META对应新位置--META被移动-----ROOT文件
RegionServer写操作:
log提交
追加--“提交日志(commit log)”---加入memStore--满了,输入flush文件系统;
Log--存于HDFS中
regionServer崩溃恢复:
崩溃--提交日志可用--master根据日志重新分配regionserver
文件刷新合并,处理垃圾数据
一个后台进程:
负责刷新文件个数压缩文件;
把多个文件合并重新写入一个文件;
删除掉过期数据;
另一个进程:
控制刷新文件大小,负责文件大小超出预值后,对区域分割;
六. Hbase的特性
- 没有真正的索引
- l自动分区
- l线性扩展和对于新节点的自动处理
- 普通商用硬件支持
- 容错:大量节点相对于每个节点重要性不突出,不用担心单个节点失效
- 批处理