神经网络
非线性假设

一般来说,分类问题的数据是非线性可分的,如上图左侧所示,若采用logistic回归分类这些数据,则必须考虑构造高阶特征,如上图右侧所示。
然而,若原始数据包含\(n\)种特征,若想手动构造出二阶特征,则可能构造出大约\(C_n^2=\frac{n(n-1)}2\)个特征,若想构造出更高阶的特征,则特征数目会更多。人工构造高阶特征和训练构造新特征后的数据所需的成本太高。
对于复杂的计算机视觉问题,往往输入数据的维度更高,在这类问题种使用构造高阶特征的logistic回归是完全不可行的。
神经网络单元:感知机
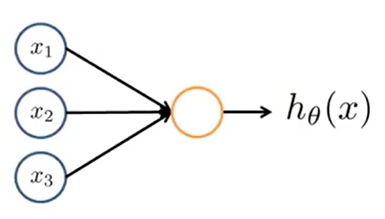
神经网络是由若干层感知机组成的。感知机的结构如上图所示。设输入感知机的列向量\(X=(1,x_1,x_2,\cdots,x_n)^T\),感知机参数(权重)\(\theta=(\theta_0,\cdots,\theta_n)^T\),则
\[h_\theta(x)=Sigmoid(\theta^TX)\]
神经网络
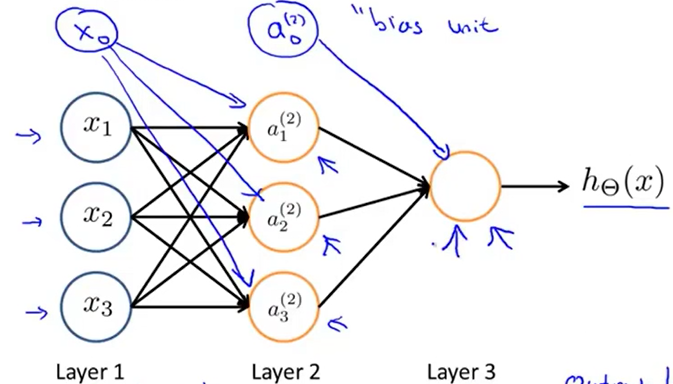
最简单的神经网络结构如上图所示,该网络包含两层感知机(Layer 2,Layer 3),Layer 1为输入层,输入数据。每一层的感知机从上一层接收数据,经处理后向下一层输出
其中,每一层的偏置(图中蓝色)不是感知机,但可以视作特殊的结点,这些结点输出恒为1
符号约定
\(s_l=\)第l层的神经元个数(不包括偏置结点)
\(a_i^{(l)}=\)第l层第i个结点的输出值
\(a^{(l)}=(1,a_1^{(l)},\cdots,a_{s_l}^{(l)})^T\)
\(z_i^{(l)}=\)第l层第i个结点从上一层接收数据后加权求和的值,注意这个值还未经激励函数处理
\(z^{(l)}=(z_1^{(l)},\cdots,z_{s_l}^{(l)})^T\)
\(\Theta^{(l)}\)为第l到第l+1层的参数矩阵,大小为\(s_{l+1}\times (s_l+1)\),\(\Theta^{(l)}_{i,j}=\)第l层第j个结点到第l+1层第i个结点的参数
以下简称激励函数Sigmoid函数为g(x)
为方便描述,虽然偏置结点并不是感知机,但每层偏置结点的输出值仍视为\(a^{(l)}_0\)
前向传播
\[z_i^{(l+1)}=\sum_{j=0}^{s_l}\Theta^{(l)}_{i,j}a^{(l)}_j\]
\[z^{(l+1)}=\Theta^{(l)}a^{(l)}\]
\[a^{(l+1)}=(1,g(z^{(l+1)}))\]