一、什么是提升系统的高可用性
JAVA服务端,顾名思义就是23体验网为用户提供服务的。停工时间,就是不能向用户提供服务的时间。高可用,就是系统具有高度可用性,尽量减少停工时间。如何用最简单的方法来搭建一个高效率可用的服务端JAVA呢?
停工的原因一般有:
服务器故障。例如服务器宕机,服务器网络出现问题,机房或者机架出现问题等;访问量急剧上升,导致服务器压力过大导致访问量急剧上升的原因;时间和访问量都可以预见的,例如23体验网的秒杀活动,售票系统;时间和访问量都不可以预见的,例如特发性新闻(马航失联的事件)。
停工的原因,可以理解为灾难,所以系统的高可用性就是容灾,即应对灾难的能力,系统有较好的容灾能力,也就是即使灾难出现,系统依然可以正常工作。
二、怎么用JAVA提升系统的高可用性
1、机器层面的灾难
机房故障(机房被水淹了);网络异常(电信的某条光纤被挖断了)
从范围了说,有可能是一台机器,也有可能是多台机器(机房或者某个区域,例如广东),甚至全部机器(那就没救了..)。思路就是在多台机器上部署服务,即使一台机器出现问题,其他机器依然可以提供服务。当然,比较可靠的是,多台机器最好在不同的机房,不同的地域,但是对应的成本也会上升。这就是构建一个高可用服务端的ngix配置
upstream gunicorn_pool
{
#server 地址:端口号 weight表示权值,权值越大,被分配的几率越大;max_fails表示在fail_timeout中失败的最大次数,如果达到该次数,就不再导流量到该server
server 192.168.137.130:9098 weight=4 max_fails=2 fail_timeout=30s;
server 192.168.137.133:9098 weight=4 max_fails=2 fail_timeout=30s;
}
server {
listen 80;
server_name 127.0.0.1 www.23tiyan.com;
access_log /data/logs/nginx_access.log;
error_log /data/logs/nginx_error.log;
location @gunicorn_proxy {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_pass http://gunicorn_pool;
}
}主服务负责提供服务,从服务负责监测主服务器的心跳。当主服务出现问题,立刻转换为从服务器提供服务。例如Mysql的的的主从架构。
2、多机多工方式
在Ñ台机器上面,运行Ñ个服务,通过负载均衡,把请求分发到不同的机器。当其中一台机器出现问题。系统会自动的切换流量,也就是把请求都导流到其他正常的机器上。程序出错误,访问量急剧上升(预计QPS是1K,突然去到1W)的。
本机的主机配置中,可以设置一个域名对应多个IP,设置方法:
192.168.137.130 www.23tiyan.com
192.168.137.133 www.23tiyan.com
主机的解析策略是,先访问第一个IP,如果失败,才会访问第二个IP
所以没有负载均衡的功能,但是有自动流量切换的功能。3、提升系统可用性的优化思路:
大系统小做。一个大系统,必然会有许多模块,把这些模块切分为多个小服务。例如用户系统,是一个独立的服务,消费系统,是一个独立的服务。每个服务都提供访问的API,给其他服务访问缺点是服务与服务之间的通讯成本增加,开发成本也会增加,必要的时候,这些API可以提供给外部符合高内聚低耦合的原则。
当某个服务压力上升时,或者服务出现错误时,其他不依赖于问题服务的服务,依然可以正常工作。例如消费服务出现问题,但是聊天服务可以依然可以正常工作。有损服务。让服务延迟执行,以保证核心需求得到很好的处理。例如微信抢红包,核心需求是立刻知道抢红包的结果,所以服务端先返回抢红包的结果,而用户对是否即时入账并不关心,所以,把入账这个过程,放在异步队列里面做。也可以TCP Server提供一个http接口,返回自身的状态,供得到-IP接口那边调用。
快速拒绝(过载保护)。检查当前系统的负载请求,如果负载过高,立刻返回等待提示,例如:系统繁忙,请稍后再试。否则,用户会不断重试,让已经负载很高的系统雪上加霜。重试的频率,例如30秒后才能重试,或者没有收到服务端的返回前,不能再次提交请求。也可以在Nginx的层加入限制,同一IP1秒内不能发送多于ñ个请求,多于的就快速拒绝,防止被攻击。
当我们采用了各种措施来提升系统的容灾能力后,怎么测试我们的措施是否有用呢?
三、搭建高可用服务端后面的应用
应用一般都是针对上面的机器问题导致的机器层面的灾难,因为业务层面的,一般是在代码开发阶段考虑的。
高可用可以分为两个关键点:多节点;自动切换流量。
多节点,也就是要部署多个节点,无论其他节点是挂起状态(主从),还是工作昨天(多机多工)。
当有了多节点后,还是不够的,因为当灾难来临的话,如果要人工去切换流量,必然要花费较长时间,所以需要有自动切换流量的机制。
自动切换流量的另一个功能就是,当损坏的节点恢复后,流量又会自动得切回去。
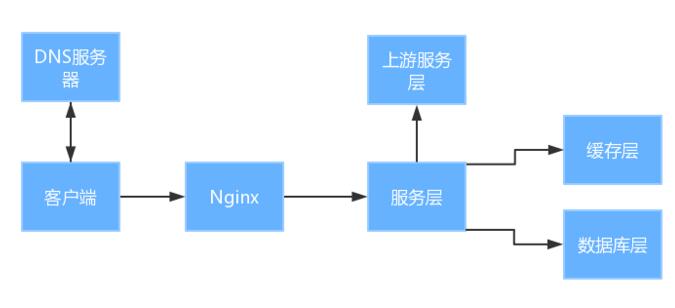
四、HTTP的应用
常用的服务端架构,客户端从DNS服务器获取服务器的IP;客户端发起请求,请求先到Nginx的层;Nginx的层分发请求到服务层。