在C++里有写好的标准模板库,我们称为STL库,它实现了集合、映射表、栈、队列等数据结构和排序、查找等算法。我们可以很方便地调用标准库来进行各类操作。
动态数组
引用库
有时候想开一个数组,但是却不知道应该开多大长度的数组合适,因为我们需要用到的数组可能会根据情况变动,是个时候就需要我们用到动态数组了。
C++中的动态数组写作 vector,它的实现被写在 vector 的头文件中,并在所有头文件之后加上一句 using namespac std。
#include <vector>
using namespace std;
int main() {
return 0;
}构建一个动态数组
现在我们来构造一个动态数组。
C++中直接构造一个vector的语句为:
vector<T>vec;这样我们定义了一个名为 vec 的储存 T 类型数据的动态数组。其中 T 是我们要储存的数据类型,可以是 int、float、double 或者其他自定义的数据类型等等。初始的时候 vec 是空的。
插入元素
C++中通过 push_back ( ) 方法在数组最后面插入一个新的元素。
#include <vector>
using namespace std;
int main() {
vector<int> vec; // []
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2, 3]
return 0;
}获取长度并且访问元素
C++ 中通过 size ( ) 方法获取 vector 的长度,通过 [ ] 操作直接访问 vector 中的元素,这一点和数组是一样的。
#include <vector>
#include <stdio.h>
using namespace std;
int main() {
vector<int> vec; // []
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2, 3]
for (int i = 0; i < vec.size(); ++i) {
printf("%d\n", vec[i]);
}
return 0;
}修改元素
C++ 中修改 vector 中某个元素很简单,只需要用 = 给它赋值就好了,比如 vec[1]=3。
#include <vector>
#include <stdio.h>
using namespace std;
int main() {
vector<int> vec; // []
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2, 3]
vec[1] = 3; // [1, 3, 3]
vec[2] = 2; // [1, 3, 2]
for (int i = 0; i < vec.size(); ++i) {
printf("%d\n", vec[i]);
}
return 0;
}清空
C++需调用 clear( ) 方法就可以清空 vector 。
C++中 vector 的 clear( ) 只是清空 vector ,并不会清空开的内存。用一种方法可以清空 vector 的内存。先定义一个空的 vector x,然后用需要清空的 vector 和 x 交换,因为 x 是局部变量,所以会被系统回收内存(注意:大括号一定不能去掉)。
vector<int> v;
{
vector<int> x;
v.swap(x);
}C++ vector 方法总结
| 方法 | 功能 |
|---|---|
| push_back | 在末尾加入一个元素 |
| pop_back | 在末尾弹出一个元素 |
| size | 获取长度 |
| clear | 清空 |
集合
集合是数学中的一个基本概念,通俗地讲,集合是由一些不重复的数据组成的。比如 { 1 , 2 , 3 } 就是一个有1,2,3的集合。C++的标准库中的集合支持高效的插入、删除合查询操作,这三个操作的时间复杂度都是 O(lgn),其中n是当前集合中元素的个数。如果用数组,虽然插入的时间复杂度是 O(1),但是删除合查询都是 O(n),此时效率太低。在C++中我们常用的集合是set。
引用库
C++中的集合实现被写在 set 的头文件中,并在所有头文件之后加上一句 using namespac std。
#include <set>
using namespace std;构造一个集合
现在我们来构造一个集合。
C++中直接构造一个 set 的语句为:
set<T> s;这样我们定义了一个名为s的、储存T类型数据的集合,其中T是集合要储存的数据类型。初始的时候s是空集合。
插入元素
C++中用 insert( ) 方法向集合中插入一个新的元素。注意如果集合中已经存在了某个元素,再次插入不会产生任何效果,集合中是不会出现重复元素的。
#include <set>
#include <string>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
return 0;
}删除元素
C++中通过 erase( ) 方法删除集合中的一个元素,如果集合中不存在这个元素,不进行任何操作。
#include <set>
#include <string>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
country.erase("America"); // {"China", "France"}
country.erase("England"); // {"China", "France"}
return 0;
}查找元素
C++中如果你想知道某个元素是否在集合中出现,你可以直接用 count( ) 方法。如果集合中存在我们要查找的元素,返回 1 ,否则返回 0 。
#include <set>
#include <string>
#include <stdio.h>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
if (country.count("China")) {
printf("China belong to country");
}
return 0;
}遍历元素
C++ 通过迭代器可以访问集合中的每个元素,迭代器就好比只想集合中的元素的指针。如果你不了解迭代器,你只需要先记住。
#include <set>
#include <string>
#include <iostream>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
for (set<string>::iterator it = country.begin(); it != country.end(); ++it) {
cout << (*it) << endl;
}
return 0;
}注意:在C++中遍历set是从小到大进行的。
清空
C++中只需要调用 clear( ) 方法就可以清空 set 。
C++ set方法总结
| 方法 | 功能 |
|---|---|
| insert | 插入一个元素 |
| erase | 删除一个元素 |
| count | 判断元素是否在set中 |
| size | 获取元素的个数 |
| clear | 清空 |
映射
映射是指两个集合之间的元素的相互对应关系。通俗地说,就是一个元素对应另外一个元素。比如一个姓名的集合 {“Tom”, “Jone”, “Marry”},班级集合{1, 2}。姓名与班级之间可以有如下的映射关系:
class(“Tom”) = 1 , class(“Jone”) = 2 , class(“Marry”) = 1
我们称其中的姓名集合为 关键字集合(key) , 班级集合为 值集合(value) 。
在 C++ 中我们常用的映射是 map。
引用库
C++中的map实现被写在 set 的头文件中,并在所有头文件之后加上一句 using namespac std。
#include <map>
using namespace std;构造一个映射
现在我们来构造一个映射。
在C++中,我们构造一个 map 的语句为:
map<T1,T2> m;这样我们定义了一个名为 m 的从 T1 类型到 T2 类型的映射。初始的时候 m 是空映射。
插入映射
在 C++ 中通过 insert( ) 方法向集合中插入一个新的映射,参数是一个 pair 类型的结构。这里需要用到另外一个 STL 模板 —— 元组(pair)。
pair<int,char>(1,'a');定义了一个整数 1 合字符 a 的 pair。我们向映射中加入了新映射对的时候就是通过加入 pair 来实现的。如果插入的 key 之前已经有了 value,不会用插入的新的 value 替代原来的 value,也就是此次插入是无效的。
#include <map>
#include <string>
using namespace std;
int main() {
map<string, int> dict; // {}
dict.insert(pair<string, int>("Tom", 1)); // {"Tom"->1}
dict.insert(pair<string, int>("Jone", 2)); // {"Tom"->1, "Jone"->2}
dict.insert(pair<string, int>("Mary", 1)); // {"Tom"->1, "Jone"->2, "Mary"->1}
dict.insert(pair<string, int>("Tom", 2)); // {"Tom"->1, "Jone"->2, "Mary"->1}
return 0;
}访问映射
在 C++ 中访问映射合数组一样,直接用 [] 就能访问。比如 dict[“Tom”] 就可以获取 “Tom” 的班级了。而这里有一个比较神奇的地方,如果没有对 “Tom” 做过映射的话,此时你访问 dict[“Tom”] ,系统将会自动为 “Tom” 生成一个映射,其 value 为对应类型的默认值。并且我们可以之后再给映射赋予新的值,比如 dict[“Tom”] = 3 ,这样为我们提供了另一种方便的插入手段。当然有些时候,我们不希望系统自动为我们生成映射,这时候我们需要检测 “Tom” 是否已经有映射了,如果已经有映射再继续访问。这时候就需要用 count( ) 函数进行判断。
#include <map>
#include <string>
#include <stdio.h>
using namespace std;
int main() {
map<string, int> dict; // {}
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
printf("Mary is in class %d\n", dict["Mary"]);
printf("Tom is in class %d\n", dict["Tom"]);
return 0;
}查找关键字
在 C++ 中,如果你想知道某个关键字是否被映射过,你可以直接用 count( ) 方法。如果被映射过,返回 1 ,否则返回 0 。
#include <map>
#include <string>
#include <stdio.h>
using namespace std;
int main() {
map<string, int> dict; // {}
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
if (dict.count("Mary")) {
printf("Mary is in class %d\n", dict["Mary"]);
} else {
printf("Mary has no class");
}
return 0;
}遍历映射
在 C++ 中,通过迭代器可以访问映射中的每个映射,每个迭代器的 first 值对应 key,second 值对应 value。
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main() {
map<string, int> dict; // {}
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
for (map<string, int>::iterator it = dict.begin(); it != dict.end(); ++it) {
cout << it->first << " is in class " << it->second << endl;
}
return 0;
}清空
C++ 中只需要调用 Clear( ) 即可清空 map。
C++中map常用方法总结
| 方法 | 功能 |
|---|---|
| insert | 插入一对映射 |
| count | 查找关键字 |
| erase | 删除关键字 |
| size | 获取映射对个数 |
| clear | 清空 |
栈
栈(stack),又名堆栈,是一种运算受限制的线性表类型的数据结构。其限制是只允许在栈的一段进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
可以想像往子弹夹中装子弹的情形,正常情况下只能往子弹夹入口那端装入子弹,这一步就好比向栈中压入元素,称为 push,射击的时候,弹夹会从顶端弹出子弹,这一步就好比从栈顶弹出元素,称为 pop,可以发现,从栈顶弹出的子弹是最后一个压进去的子弹,这也是栈的一个重要性质,先进后出(FILO——first in last out)。另外,用一个 top 指针表示当前栈顶的位置。
下图演示栈的 push 和 pop 的过程。
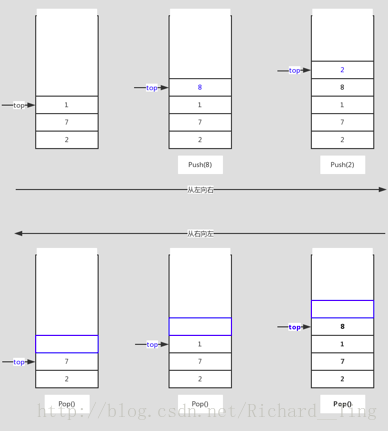
栈的实现
关于栈的实现,一种方法是利用数组手动实现,需要固定缓存大小,也就是数组的大小。
int stack[maxsize], top = 0;
void push(int x) {
stack[top++] = x;
}
void pop() {
--top;
}
int topval() {
return stack[top - 1];
}
int empty() {
return top > 0;
}用 stack 表示存储栈的空间,top 表示当栈顶的指针位置,方法 push( ) 压入一个数 x 到栈顶,方法 pop( ) 从栈顶弹出一个元素,方法 topval( ) 获取栈顶元素。
然而 C++ 中已经有写好的栈的对象,可以直接用。
#include <stack>
#include <iostream>
using namespace std;
stack<int> S;
int main() {
S.push(1);
S.push(10);
S.push(7);
while (!S.empty()) {
cout << S.top() << endl;
S.pop();
}
return 0;
}上面是 C++ 里的 stack 的用法。push,pop 分别是压栈和出栈,top 是栈顶元素,empty 判断栈是否为空。
栈的两个经典的应用
- 火车车厢入站和出站顺序确定。火车进展的时候车厢编号为从前到后一次 1,2,3,4,5,然后确定一个出站顺序是否合法。这里站台就是一个栈的结构。需要遵循先进后出的顺序。用一个栈模拟就可以得到出站顺序是否合理。
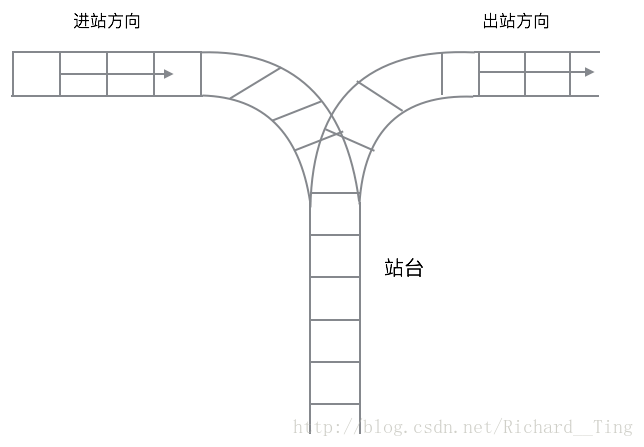
2.用来判断括号是否匹配,经常遇到表达式里面的括号很多的情况,有很多方法来判断,其中最简单的一个方法就是用栈来判断。扫描一遍字符串,当遇到 ‘(’ ,压入栈;当遇到 ‘)’ 的时候,从栈中弹出一个 ‘(’ ,如果栈为空无法弹出元素,说明不合法。最后,如果栈中还有 ‘(’ 也不合法。
队列
队列(queue)是一种线性的数据结构,和栈一样是一种运算受限制的线性表。其限制只允许从表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。一般允许进行插入的一端我们称为队尾,允许删除的一端称为队首。队列的插入操作又叫入队,队列的删除操作又叫出队。
可以把队列想像成购物时排队结账的时候的队伍,先排队的人会先结账,后排队的人会后结账,并且不允许有插队的行为,只能在队伍的末尾进行排队。这就是队列的特点,具有先进先出(FIFO——First in First out)的性质。
队列的结构如图示:

队列的主要操作包括:
+ 入队(push)
+ 出队(pop)
+ 判断队列是否为空(empty)
+ 统计队列元素的个数(size)
+ 访问队头元素(front)
+ 访问队尾元素(back)
队列的实现与使用
由于队列和栈都是线性表,所以队列也同样可以用数组模拟来手动实现。但是由于队列的出队和入队在不同的两端,所以我们要引入一个循环队列的概念。
如果单纯地用数组进行模拟,那么当有元素出队的时候,我们有两种方法处理剩余的元素:第一种是保持队首(front)位置不变,其余所有的元素顺序往前移动一位;第二种是让队首(front)向后移动一位,其余每个元素的位置不变,也就是使现在的位置称为新的队首位置。
第一种方法需要移动队列的所有元素,时间效率非常低,第二种只需要移动队头则变得非常简单,但第二种会导致之前队头所在的位置以后不会再被用到,造成空间的浪费。循环队列就解决了这个问题。
在实际使用队列中,为了使队列的空间能重复使用,一旦队列的头(front)或者尾(rear)超出了所分配的队列空间,则让它指向队列的起始位置,从 MaxSize -1 增加 1 变成 0 。
例如,下图是一个循环队列,由于之前的出队操作,导致 front 已经移动倒了 4 的位置,如果继续添加元素那么 rear 就会移动到 0 的位置。
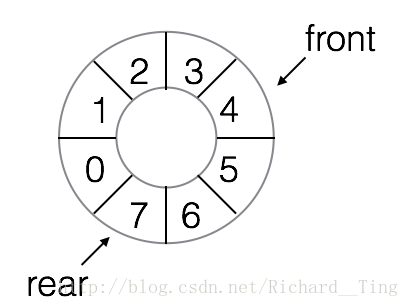
当元素装满整个队列之后就会造成溢出,所以如果要动手实现队列的话,最好提前预估队列的最大容量。
手动实现:
#define maxsize 10000
class queue {
int q[maxsize];
int front, rear, count;
queue() {
front = 0;
rear = 0;
count = 0;
}
void push(int x) {
count++;
if (count == maxsize) {
// 溢出
}
q[rear] = x;
rear = (rear + 1) % maxsize;
}
int pop() {
count--;
front = (front + 1) % maxsize;
return q[front];
}
int front_val() {
return q[front];
}
bool empty() {
if (count == 0) {
return true;
}
return false;
}
};基本操作
| 操作 | C++ |
|---|---|
| 入队 | push |
| 出队 | pop |
| 访问队首元素 | front |
| 大小 | size |
| 是否为空 | empty |
#include <queue>
#include <iostream>
using namespace std;
int main() {
queue<int> q; // 声明一个装 int 类型数据的队列
q.push(1); // 入队
q.push(2);
q.push(3);
cout << q.size() << endl; // 输出队列元素个数
while (!q.empty()) { // 判断队列是否为空
cout << q.front() << endl; // 访问队首元素
q.pop(); // 出队
}
return 0;
}优先队列
原因:一些问题不能按照传统模式先进先出,要优先访问级别高的元素,这时,就产生了对优先队列的思考。
在队列中,元素从队尾进入,从队首删除。相比队列,优先队列里的元素增加了优先级的属性,优先级高的元素先被删除。
C++代码:
#include <queue>
#include <iostream>
using namespace std;
int main() {
priority_queue<int> q; // 声明一个装 int 类型数据的优先队列
q.push(1); // 入队
q.push(2);
q.push(3);
while (!q.empty()) { // 判断队列是否为空
cout << q.top() << endl; // 访问队列首元素
q.pop(); // 出队
}
return 0;
}
/*
输出为
3
2
1
*/例题讲解
给出两个包含 n 个整数的数组 A,B。在 A、B 中任意取出一个数并将这两个数相加,可以得到 n^2 个和。求这些和中最小的 n 个。
解析:如果按照朴素算法,依次在 A 和 B 中分别取出一个数,然后生成和值,最后排序以后取前面的 n 个和。这样的时间复杂度是 n^2lgn。效率不高。
我们可以借助优先队列来解决这题。首先把 A,B按照从小到大的顺序排序。观察下面这个表格。
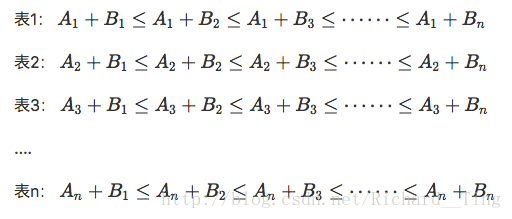
我们用一个结构 (sum,a,b) 来表示一个和值。
我们建立一个优先队列q,队列中 sum 越小优先级越高。初始的时候,将(A[i]+B[1], i, 1)入队。然后在队中取出一个结构(sum, a, b),然后把结构(A[a]+B[b+1], a, b+1)重新入队。这样重复 n 次。取出的一次就是最小的 n 个和。任何时候,优先队列中最多只会有 n 个元素。所以这样的复杂度是 nlgn。整个过程中,我们发现同一个表中,下标 a 其实不会变,所以可以不用记录下标 a,这样结构就可以简化成(sum,b)。
推广:
上面是只有两个数组的。如果是 n 个数组,每个数组取出一个元素,也可以用这个方法,每次合并两个,合并 n 次就可以了。
优先队列的优先级重载
优先队列,可以存放数值,也可以存放其他数据类型(包括自定义数据类型)。该容器支持查询优先级最高的这一操作,而优先级的高低是可以自行定义的。
在C++中我们可以通过重载小于运算符 bool operator < 来实现。
比如整数,程序默认是数值较大的元素优先级较高,我们一可以定义数值较小的元素优先级较高。又比如下面的例子,定义距离值较小的 node 优先值较高。
struct node {
int dist, loc;
node() { }
bool operator < (const node & a) const {
return dist > a.dist;
}
};
priority_queue <node> Q;上述代码起到优先级重载的作用,我们仍然可以进行 top,pop等操作。
并查集
并查集是一种树型的数据结构,用于处理一些不相加集合的合并和查询问题。在使用中常常以森林来表示。
并查集也是用来维护集合的,和 set 不同之处在于,并查集能很方便地同时维护很多集合。如果用 set 来维护会非常麻烦。并查集的核心思想是记录每个结点的父亲结点是哪个结点。
1)初始化:初始化的时候每个结点各自为一个集合,father[i]表示结点 i 的父亲结点,如果father[i] = i,我们认为这个结点是当前集合的根节点。
void init() {
for (int i = 1; i <= n; ++i) {
father[i] = i;
}
}2)查找:查找结点所在集合的根节点,结点 x 的根节点必然也是其父亲结点的根节点。
int get(int x) {
if (father[x] == x) { // x 结点就是根结点
return x;
}
return get(father[x]); // 返回父结点的根结点
}3)合并:将两个元素所在的集合合并在一起,通常来说,合并之前先判断两个元素是否属于同一集合。
void merge(int x, int y) {
x = get(x);
y = get(y);
if (x != y) { // 不在同一个集合
father[y] = x;
}
}路径压缩
前面的并查集的复杂度实际上在有些极端情况会很慢。比如树的结构正好是一条链,那么最坏情况下,每次查询的复杂度达到了O(n)。这并不是我们期望的结果。
路径压缩的思想是,我们只关心每个结点的父结点,而并不太关心树的真正的结构。这样我们在一次查询的时候,可以把查询路径上的所有结点的 father[i] 都赋值成为根节点。只需要做出如下改变:
int get(int x) {
if (father[x] == x) { // x 结点就是根结点
return x;
}
return father[x] = get(father[x]); // 返回父结点的根结点,并令当前结点父结点直接为根结点
//注意,这里一次性将所有非根结点的结点都通过递归直接与根节点相连,成扁平状。
}下图是路径压缩前后的对比。
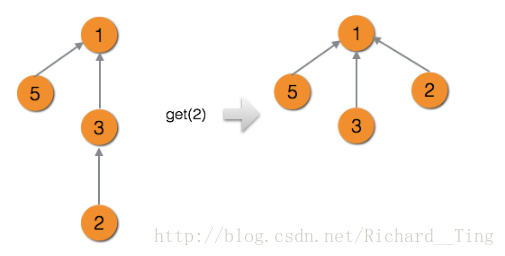
路径压缩在实际应用中效率很高,其依次查询复杂度平摊下来可以认为是一个常数。并且在实际应用中,我们基本都用带路径压缩的并查集。
带权并查集
所谓带权并查集,是指结点存有权值信息的并查集。并查集以森林的形式存在,而结点的权值,大多是记录该结点与祖先关系的信息。比如权值可以记录该结点到根节点的距离。
例题
在排队过程中,初始时,一人一列。一共有如下两种操作。
- 合并:令其中的两个队列 A,B 合并,也就是将队列 A 排在队列 B 的后面。
- 查询:询问某个人在其所在队列中排在第几位。
例题解析
我们不妨设 size[]为集合中的元素个数,dist[]为元素到队首的距离,合并时,dist[A.root]需要加上size[B.root] (每个元素到队首的距离应该是到根路径上所有点的dist[]求和),size[B.root]需要加上size[A.root] (每个元素所在集合的元素个数只需查询该集合中根的size[x.root])。
1)初始化:
void init() {
for(int i = 1; i <= n; i++) {
father[i] = i, dist[i] = 0, size[i] = 1;//初始化
}
}2)查找:查找元素所在的集合,即根节点。
int get(int x) {
if(father[x] == x) {
return x;
}
//下面1、2步为路径压缩,每个点都指向自己的根结点了。
//这里一次性将所有非根结点的结点都通过递归直接与根节点相连,成扁平状。
}
int y = father[x];//1 --得到x的父亲节点
father[x] = get(y);//2 --将x直接指向根节点get(y)
dist[x] += dist[y]; // (x到根结点的距离) 等于 (x到之前父亲结点距离) 加上 (之前父亲结点到根结点的距离)
return father[x];
}路径压缩的时候,不需要考虑 size[],但 dist[] 需要更新成到整个集合根的距离。
3)合并
将两个元素所在的集合合并为一个集合。
通常来说,合并之前,应先判断两个元素是否属于同一个集合,这可用上面的“查找”操作实现。
void merge(int a, int b) {
a = get(a);
b = get(b);
if(a != b) { // 判断两个元素是否属于同一集合
father[a] = b;
dist[a] += size[b];//原因是A队伍跑到B队伍后面去了,注意这是针对例题的
size[b] += size[a];
}
}通过小小的改动,我们就可以查询并查集这一森林中,每个元素到祖先的相关信息。