grep工具是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep的语法:

在使用grep的时候需要注意以下几点:
- grep不加引号直接过滤字符串
- grep在进行模式匹配的时候必须加引号,单引和双引号都可以
- grep在引用变量的时候必须加双引号
来看看grep的选项:
- -a:不要忽略二进制数据
- -A #:除了显示符合条件的那一行之外,还显示该行之后#行的内容
- -B #:除了显示符合条件的那一行之外,还显示该行之前#行的内容
- -c:计算符合条件的列数
- -C #:除了显示符合条件的那一行之外,还显示该行前#行和该行后#行的内容
- -d:要指定查找的是目录而非文件,必须使用这项参数
- -e:指定字符串为查找文件内容的条件
- -E:使用扩展的正则表达式
- -f 文件:要匹配的模式来源于文件,类似于在别的文件中搜索该文件中的内容
- -F:将条件视为固定字符串的列表
- -G:使用基准模式来匹配
- -h:在显示符合条件的那一列之前不标示该列所属的文件名称
- -H:在显示符合条件的那一列之前标示该列所属的文件名称
- -i:忽略大小写
- -l:列出文件内容符合指定条件的文件名称
- -L:列出文件内容不符合指定条件的文件名称
- -n:在显示符合条件的那一列之前标示出该列的编号
- -q:安静模式匹配,不显示任何信息
- -R/-r:递归模式进行匹配
- -s:不显示错误信息
- -v:选择不匹配的行
- -w:只显示全字符合的列
- -x:只显示全列符合的列
- -y:和选项 -i 类似
- -o:只输出文件中匹配到的部分
接下来给其中比较常用的选项举几个例子:
在举例子之前再说一个选项 - -color 是为了将匹配到的结果高亮显示
1. 先来看看最常见的匹配:
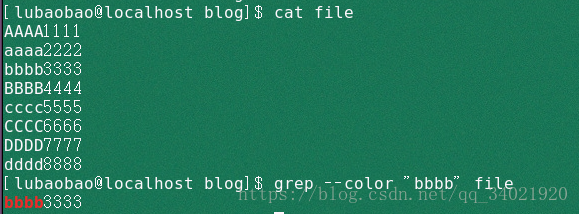
2. grep -o --color "bbbb" file 只显示匹配到的部分

3. grep -i --color "bbbb" file 忽略大小写

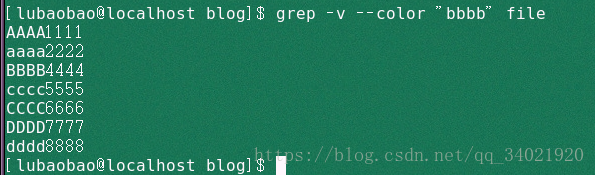
4. grep -v --color "bbbb" file 输出不匹配的行
5. grep -A 2 --color "bbbb" file 输出匹配的行及该行的后两行
grep -B 2 --color "bbbb" file 输出匹配的行及该行的前两行
grep -C 2 --color "bbbb" file 输出匹配的行及该行的前后两行

6. grep -E --color [2-4]+ file 使用正则表达式匹配

这个例子中的模式是一个正则表达式,接下来谈谈什么是正则表达式
正则表达式
1. 概念
正则表达式是对字符串(包括普通字符)和特殊字符操作的一种逻辑公式,就是用事先定义好的一些特殊字符及这些特殊字符的组合,组成一个“规则字符串”,这个规则字符串用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串
2. 正则表达式的基本要素
- 字符类
- 数量限定符
- 位置限定符
-特殊符号
3. 字符类
| 字符 | 含义 |
|---|---|
| . 点 | 匹配任意一个字符,除过”\n” “\r” |
| [ ] | 匹配中括号中的任意一个字符 |
| - | 可以在[ ]中表示字符范围 |
| ^ | 位于[ ]的开头,匹配除了括号中字符之外的任意一个字符 |
| [[:xxx:]] | xxx表示grep工具预定义的一些命名字符 |
(1) echo "this is string" | grep -E --color 'is.' 匹配is后面跟了任意一个字符的字符串

可以看到好像是匹配了 is空格is空格,这是因为grep匹配是贪心匹配,它会将后面符合条件的都匹配,利用-o选项就可以看出来

(2)echo "1234abcd" | grep -E --color '[ac]' 匹配括号中的任意一个字符

(3)echo "1234abcd" | grep -E --color '[a-c]' 匹配 a-c中的任意一个字符
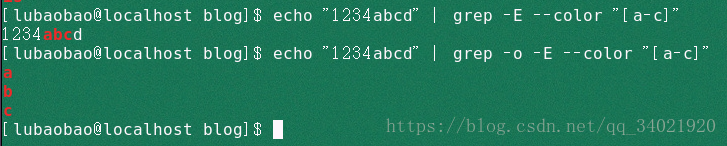
(4)echo "1234abcd" | grep -E --color '[^a-d]' 匹配除了括号中字符的任意一个字符
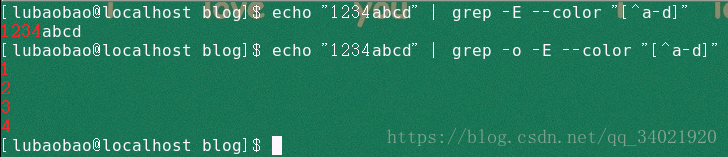
(5)echo "1234abcd" | grep -E --color '[[:digit:]]' 匹配任意一个数字字符
echo "1234abcd" | grep -E --color '[[:alpha:]]' 匹配任意一个字母字符

4. 数量限定符
| 字符 | 含义 |
|---|---|
| ? | 紧跟在前面的子表达式匹配零次或一次 |
| + | 紧跟在前面的子表达式匹配一次或多次 |
| * | 紧跟在前面的子表达式匹配零次或一次 |
| {N} | N是一个非负整数,紧跟在它前面的子表达式匹配确定的N次 |
| {N,} | 紧跟在它前面的子表达式匹配至少N次 |
| {,M} | 紧跟在它前面的子表达式匹配最多N次 |
| {N,M} | 紧跟在它前面的子表达式匹配最少N次,最多M次 |
(1)echo "bcd" | grep -E --color 'a?'
echo "aabacada" | grep -E --color 'a?' 匹配a一次或零次

(2) echo "ab12cdef" | grep -E --color '[0-9][a-z]+' 匹配第一个字符为0-9的数字,后面是a-z的字母出现一次或多次
echo "ab12abcdef" | grep -E --color 'a+' 匹配a出现一次或多次
echo "b12bcdef" | grep -E --color 'a+' 匹配a出现一次或多次

(3)echo "b12bcdef" | grep -E --color 'a*' 匹配a出现零次或多次
echo "b12abacadef" | grep -E --color 'a*' 匹配a出现零次或多次

(4)echo "b12abcdef" | grep -E --color 'a{3}'
echo "b12abacadef" | grep -E --color 'a{3}'
echo "b12aaaabcdef" | grep -E --color 'a{3}'
匹配a精确出现3次,注意这个3次必须是连续出现

(5)echo "b12aaabcdef" | grep -E --color 'a{3,}'
echo "b12aaaabcdef" | grep -E --color 'a{3,}'
echo "b12aabcdef" | grep -E --color 'a{3,}' 匹配a出现至少三次

(6)测试环境不支持 {,N} 这种方式,在此不做演示
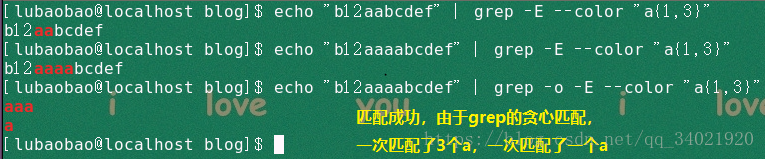
(7)echo "b12aaaabcdef" | grep -E --color "a{1,3}" 匹配a出现至少一次至多三次
5. 位置限定符
| 字符 | 含义 |
|---|---|
| ^ | 匹配行首的位置 |
| $ | 匹配行末的位置 |
| \< | 匹配单词开头的位置 |
| \> | 匹配单词结尾的位置 |
| \b | 匹配单词开头或结尾的位置 |
| \B | 匹配非单词开头或结尾的位置 |
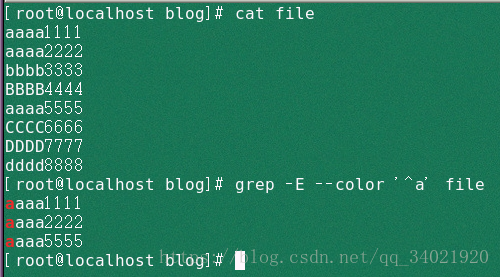
(1)grep -E --color '^a' file 匹配行首是a的
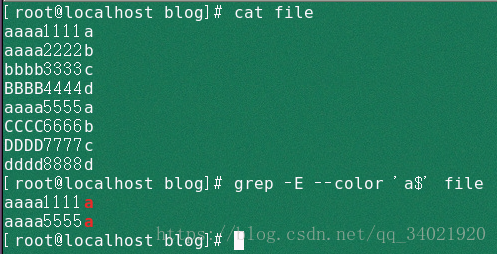
(2)grep -E --color 'a$' file 匹配行尾是a的
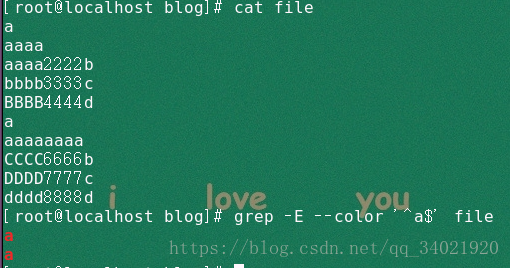
(3)grep -E --color '^a$' file 匹配行首行尾都是a,意思就是精确匹配a这个单词
(4)echo "this is isspace" | grep -E --color '\<is' 匹配以is开头的
echo "this is isspace" | grep -E --color 'is\>' 匹配以is结尾的
echo "this is isspace" | grep -E --color '\<is\>'匹配以is开头以is结尾的

(5)echo "this isis isspace" | grep -E --color '\bis' 匹配is在开头的
echo "this isis isspace" | grep -E --color 'is\b' 匹配is在结尾的
echo "this isis isspace" | grep -E --color '\bis\b'匹配is即在开头也在结尾的,即匹配is

(6) echo "ttishh is isspace" | grep -E --color '\Bis' 匹配is不在开头的,即is在中间或结尾
echo "ttishh is isspace" | grep -E --color 'is\B' 匹配is不在结尾的,即is在开头或中间
echo "ttishh is isspace" | grep -E --color '\Bis\B'匹配is不在开头也不在结尾的,及is在中间

6. 特殊字符
| 字符 | 含义 |
|---|---|
| \ | 转义字符,将普通字符转为特殊字符,特殊字符转为普通字符 |
| ( ) | 将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定符 |
| | | 连接两个子表达式,表示或的关系 |
7. 正则表达式的分类
- 基本的正则表达式 BREs
- 扩展的正则表达式 EREs
- Perl的正则表达式 PREs
grep 指令后不跟任何参数,则表示要使用 ”BREs“
grep 指令后跟 ”-E” 参数,则表示要使用 “EREs“
grep 指令后跟 “-P” 参数,则表示要使用 “PREs”