1、BeautifulSoup4基础介绍
- 使用pip安装BeautifulSoup4
pip install BeautifulSoup4- 导入BeautifulSoup4模块
import bs4- 创建BeautifulSoup.bs4对象
import urllib.request
html = urllib.request.urlopen("http://pythonscraping.com/pages/page1.html" )
soup=bs4.BeautifulSoup(html.read(),"html.parser" )- 查找bs4对象
print(soup.h1)
print(soup.html.h1)
print(soup.html.body.h1)
name=soup.find("span" ,{"class" :"red" })
print(name)
print(type(name))
print(name.get_text())
nameList = soup.findAll("span" , {"class" :"green" })
print(type(nameList))
for name in nameList:
print(type(name))
print(name.get_text())2、BeautifulSoup4处理标签方法
- 处理子标签与后代标签
for child in soup.find("table" ,{"id" :"giftList" }).children:
print(child)
for child in soup.find("table" ,{"id" :"giftList" }).descendants:
print(child)- 处理兄弟标签
for child in soup.find("table" ,{"id" :"giftList" }).tr.next_sibling:
print(child)
for child in soup.find("table" ,{"id" :"giftList" }).tr.next_siblings:
print(child)
for child in soup.find("table" ,{"id" :"giftList" }).tr.previous_sibling:
print(child)
for child in soup.find("table" ,{"id" :"giftList" }).tr.previous_siblings:
print(child)- 处理父标签
print(soup.find("img" ,{"src" :"../img/gifts/img1.jpg" }).parent.previous_sibling.get_text())3、正则表达式
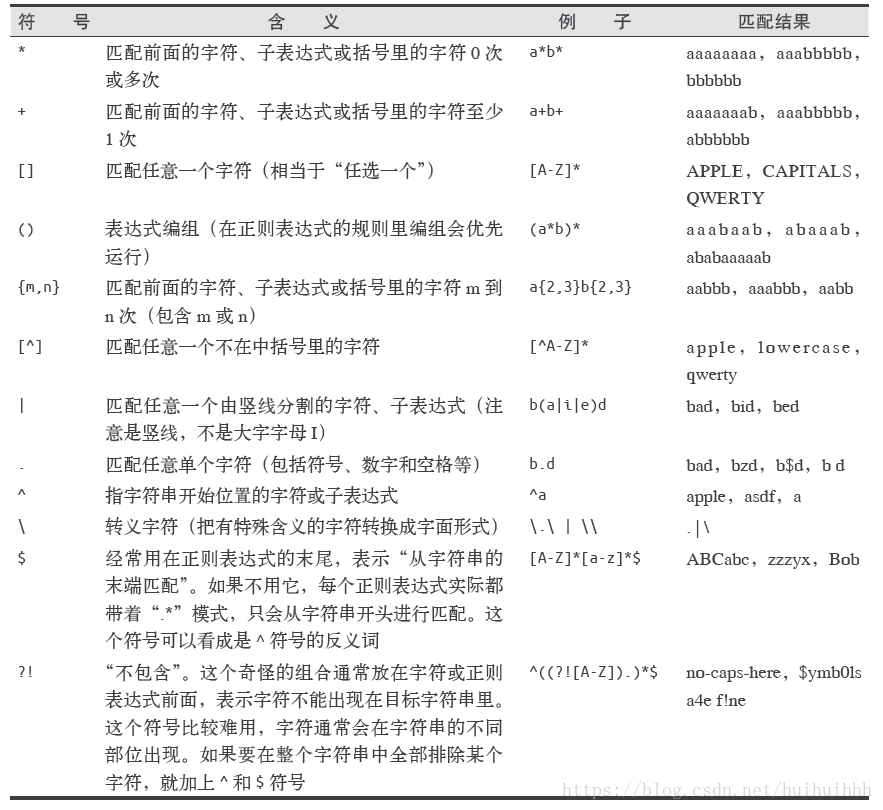
- 正则表达式常用符号
- 用正则表达式找图片
images=soup.findAll("img" ,{"src" :re.compile("\.\./img/gifts/img.*\.jpg" )})
for image in images:
print(image)4、其它
- 获取属性字典
images=soup.findAll("img" ,{"src" :re.compile("\.\./img/gifts/img.*\.jpg" )})
for image in images:
print(type(image))
print(type(image.attrs))
print(image["src" ])
print(image.attrs["src" ])- Lambda表达式
print(soup.findAll(lambda tag: len(tag.attrs) == 2 ))