本篇博客主要介绍几种加速神经网络训练的方法。
我们知道,在训练样本非常多的情况下,如果一次性把所有的样本送入神经网络,每迭代一次更新网络参数,这样的效率是很低的。为什么?因为梯度下降法参数更新的公式一般为:
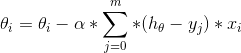
如果使用批量梯度下降法(一次性使用全部样本调整参数),那么上式中求和那项的计算会非常耗时,因为样本总量m是一个很大的数字。那么由此就有了第一种加速方法:随机梯度下降法,简称SGD。 它的思想是,将样本数据挨个送入网络,每次使用一个样本就更新一次参数,这样可以极快地收敛到最优值,但会产生较大的波动。还有一种是小批量梯度下降法,它的思想是,将数据拆分成一小批一小批的,分批送入神经网络,每送一批就更新一次网络参数。实验证明,该方法相比前两种梯度下降法,集成了两者的优点,是较好的一种加速方法。
第二类加速方法是加动量项的方法。我们知道,在更新网络参数时,如果前几次都是朝着一个方向更新,那么下一次就有很大的可能也是朝着那个方向更新,那么我们可以利用上一次的方向作为我这次更新的依据。打个比方,我想找到一座山的谷底,当我从山上往山下走,如果第一步是向下,第二步是向下,那么我第三步就可以走得快一些。从而以这种方式来加速网络训练。不仅如此,这种方法还可以从一定程度上避免网络陷入到局部极小值。

当出现以上情况时,网络走到A点,发现梯度已经为零,很可能不再继续往下走,直接以为A点就是最小值。当我们加上动量项,就可以利用前一时刻的动力,使其冲过A点,继续往下走。
第三类加速方法是AdamGrad,该方法自动地调整学习率的大小,该方法下的learning rate会根据历史的梯度值动态地改变学习率的大小。它需要计算更新到该t轮,参数的历史梯度的平方和。
第四种加速方法是RMSprop,它是一种自适应学习率算法,它与AdamGrad方法的不同之处在于,它只计算更新到该t轮,参数的历史梯度的平均值。
第五种加速方法是Adam,它也是一种自适应学习率调整算法,同时也是最广泛的一种方法。它利用的是梯度的一阶矩估计和二阶矩估计。该方法调整的学习率较为平稳,且预估结果较为准确。
当然,还有很多很多种加速神经网络训练的方法,以上只是较为常见的几种。
在PyTorch深度学习框架中,实现的优化器覆盖了Adadelta、Adagrad、Adam、Adamax、RMSprop、Rprop等等。
为了直观地比较各个优化器的性能,我借助PyTorch框架用一个神经网络来解决一个二次函数的拟合问题。
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) #设置种子,使得结果可再现
LR = 0.01 #学习率learning rate
BATCH_SIZE = 32 #一个batch的大小
EPOCH = 12 #迭代轮数
#制造数据
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1) #产生[-1,1]之间的100个值
y = x.pow(2) + 0.1*torch.normal(torch.zeros(x.size())) #y=x^2,再加上0.1倍的正态分布的扰动
plt.scatter(x.numpy(),y.numpy())
plt.show() #展示样本数据
#批训练
torch_dataset = Data.TensorDataset(data_tensor=x,target_tensor=y)
loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2,)
#shuffle=True表示随机抽取,num_workers表示线程数量
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(1,20) #隐层20个神经元
self.predict = torch.nn.Linear(20,1) #输出层1个神经元,表示预测的结果
def forward(self,x):
x = F.relu(self.hidden(x)) #隐层设置relu激活函数
x = self.predict(x) #输出层直接线性输出
return x
#为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD,net_Momentum,net_RMSprop,net_Adam] #将其放入一个列表中
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Monentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD,opt_Monentum,opt_RMSprop,opt_Adam]
#定义误差函数
loss_func = torch.nn.MSELoss()
losses_his = [[],[],[],[]]
for epoch in range(EPOCH):
print('Epoch:',epoch)
for step,(batch_x,batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net,opt,l_his in zip(nets,optimizers,losses_his):
output = net(b_x)
loss = loss_func(output,b_y)
opt.zero_grad() #为下一次计算梯度清零
loss.backward() #误差反向传播
opt.step() #运用梯度
l_his.append(loss.data[0])
labels = ['SGD','Momentum','RMSprop','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc='best') #图例放在最佳位置
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0,0.2))
plt.show()
原始的训练数据可视化:

不同Optimizer优化器性能比较的结果:

结果分析:从上图中,我们可以看出,SGD明显波动较大,Adam方法效果最优。当然每种优化器的性能还与训练数据的分布有很大的关系。