Flume
*Flume OG -->Flume NG 是Cloudera 提供的一个分布式、可靠、可用的系统(两个版本不兼容);Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志手机,并支持failover和负载均衡
*Flume使用Java编写,需运行在java1.6或以上版本
*Hadoop离线计算开发流程图:
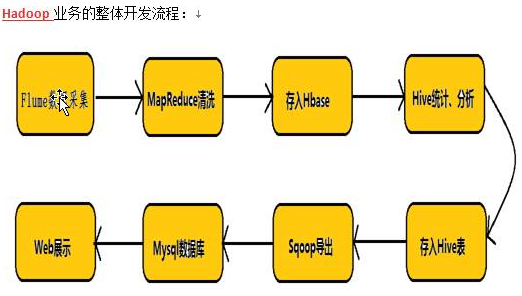
*js埋点、爬虫都可收集页面数据
*MR也可以称为ETL,数据清洗转换过程
*数据处理就是在玩字符串
*存入到哪里,由架构师根据实际情况决定
*Hive统计、分析:业务指标的分析
*利用Sqoop将Hive数据导入到Mysql
Hive是数据仓库,查询速度慢,异构数据库用Sqoop导
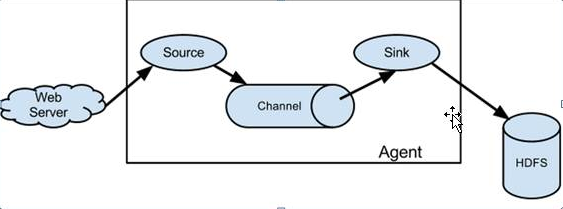
Flume架构概念图
*Flume是分布式的日志收集系统
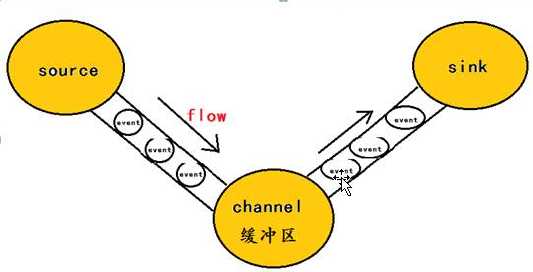
*Event


*假如监控的是文本数据,那么每一行数据就是一个Event,Event是Flume传输数据的基本单位,也是事物的基本单元,是流动的
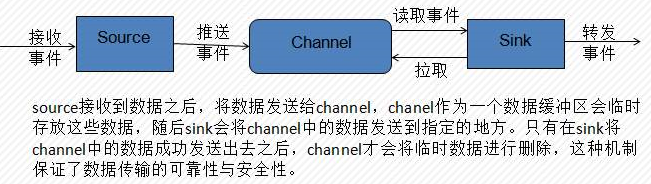
*一套source、channel、sink组成了agent,是Flume的运行的基本单元
*channer是为了保证数据传输的安全

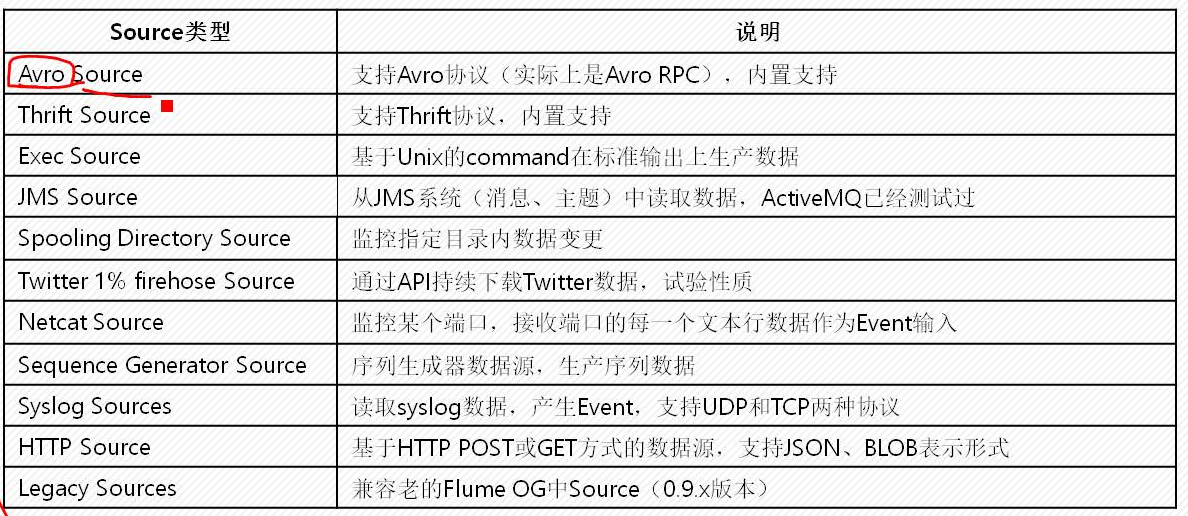
*avro:两个Agent交互的时候才会用
*Exec Source:监控一个文件内部的变化,利用底层的Linux命令
*Spooling Dircetory Source:检测指定目录内数据变化,只能监控到添加删除
*NetCat Source:监控一个端口数据的变化
*HTTP Source:能检测到post,get等变化
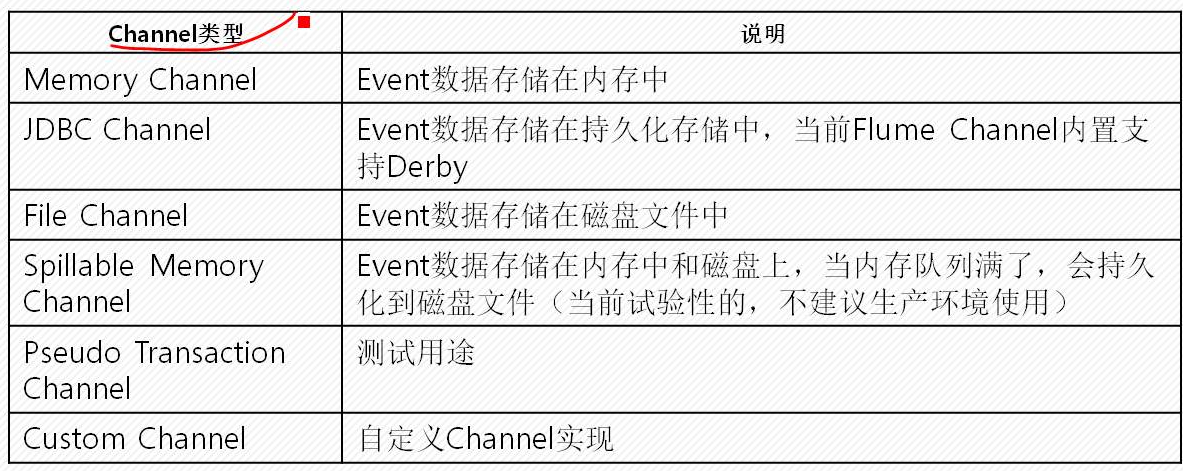
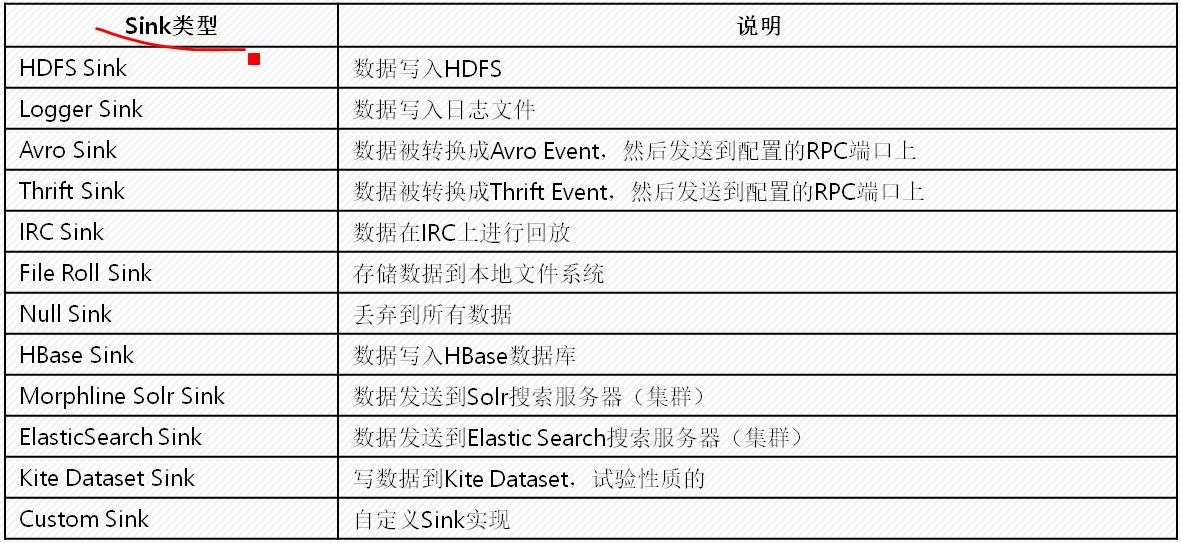
*内存溢出:堆内存(大块内存)、栈内存(小块内存) 一般情况下是堆内存溢出
例:

先定义agent的名称、三个子配置
进入sources配置,为a1这个agent的配置类型为netcat,监控某个端口号,配置端口号IP地址,
然后进入sink 定义sink的类型为logger,
然后定义channel类型为memory,设置最大存储的channels为1000,收集100条的时候再传出,
最后定义a1的sources指定的存放channels=c1 下一步将sinks指定取出的地点c1