计算定义和执行计算分开:方便分布式计算
第一讲:
1.TensorFlow中如果一个运算,没有指定变量的名称,tensorboard中自动给它起个名字,例如x,y。
import tensorflow as tf
a = tf.add(3,5)
writer = tf.summary.FileWriter("/path/to/log",tf.get_default_graph())
writer.close()
2.
TensorBoard error : path /[[_dataImageSrc]] not found
这是因为进错了目录,进到了log里面,要进入log的父目录。和浏览器没有半毛钱关系啊。
3.
tf.multiply()元素相乘
tf.matrix()矩阵相乘
4.sess.run()中同时运行两个计算,直接搞个列表就可以了。
import tensorflow as tf
a = tf.constant([[2,2],[1,4]],name="a")
b = tf.constant([[0,1],[2,3]],name="b")
x = tf.multiply(a,b,name="dou_product")
y = tf.matmul(a,b,name="mat_mul")
with tf.Session() as sess:
writer = tf.summary.FileWriter("E:/TensorFlow/Practice/chapter5/logg",sess.graph)
c,d = sess.run([x,y])#sess.run()中同时运行两个运算
print(c,d)
writer.close()5.下面run出现多个选项
tensorboard --logdir=logg的父目录
6.变量初始化时初始一个列表
import tensorflow as tf
a = tf.Variable(tf.constant([[1,2],[3,4]]),name="a",)#tf.Variable()是一个类
b = tf.Variable(tf.constant([[5,6],[7,8]]),name="b")
with tf.Session() as sess:
sess.run(tf.variables_initializer([a,b]))#初始化几个变量
print(sess.run(tf.global_variables()))
print(sess.run(tf.trainable_variables()))7.tf.Variable()是一个类
创建一个变量,初始化之后,在会话中a.eval()得到变量的值。
第二讲
线性回归
使用一元一次函数进行预测
#coding=utf-8
#线性回归
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# plt.rcParams["figure.figsize"] = (14,8)
#数据准备
#100个数据点
n = 100
xs = np.linspace(-3,3,n)#生成[-3:3]之间的n个数据,包括端点
ys = np.sin(xs)+np.random.uniform(-0.5,0.5,n)
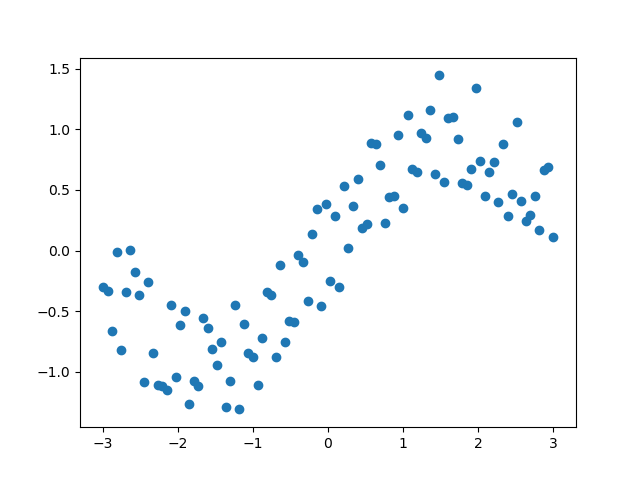
plt.scatter(xs,ys)
plt.show()
#准备好placeholder
X = tf.placeholder(tf.float32,name="X")
Y = tf.placeholder(tf.float32,name="Y")
#初始化参数/权重
W = tf.Variable(tf.random_normal([1]),name="weights")
b = tf.Variable(tf.random_normal([1]),name="bias")
#计算预测结果
Y_pred = tf.add(tf.multiply(X,W),b)
#计算损失值
loss = tf.square(Y-Y_pred,name="losss")
#初始化optimizer
learning_rate = 0.01
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
#执行
n_samples = xs.shape[0]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# writer = tf.summary.FileWriter("E:/TensorFlow/July/chapter2/log",sess.graph)
for i in range(50):
total_loss = 0
for x,y in zip(xs,ys):
_,l = sess.run([optimizer,loss],feed_dict={X:x,Y:y})#有两个结果,第一个不要,用_
total_loss += l
if i%5 == 0:
print("Epoch{0}:{1}".format(i,total_loss/n_samples))
writer = tf.summary.FileWriter("E:/TensorFlow/July/chapter2/log", sess.graph)
writer.close()
W,b = sess.run([W,b])
print(W)
print(b)
plt.plot(xs,ys,'bo',label="Real data")
plt.plot(xs,xs*W+b,'r',label="Predicted data")
plt.legend()
plt.show()
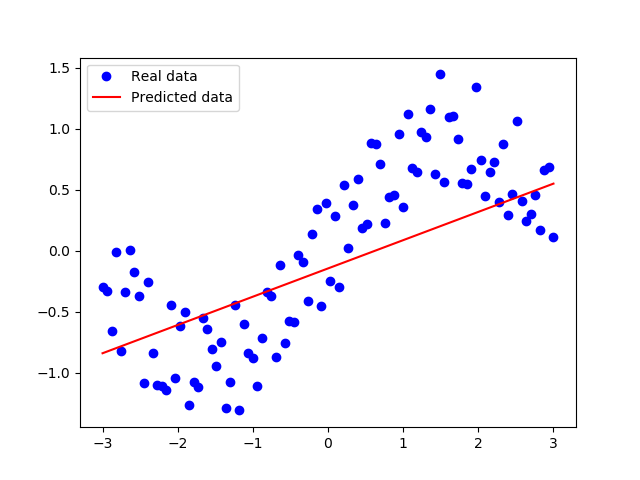
可以看出来拟合的效果很差。
多项式拟合
#coding=utf-8
#线性回归
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
#plt.rcParams["figure.figsize"] = (10,6)
#数据准备
#100个数据点
n = 100
xs = np.linspace(-3,3,n)#生成[-3:3]之间的n个数据,包括端点
xss = xs.reshape(1,100)
ys = np.sin(xs)+np.random.uniform(-0.5,0.5,n)
yss = ys.reshape(1,100)
#准备好placeholder
X = tf.placeholder(tf.float32,name="X",shape=[1,None])
Y = tf.placeholder(tf.float32,name="Y",shape=[1,None])
#初始化参数/权重
W = tf.Variable(tf.random_normal([1]),name="weights")
W_2 = tf.Variable(tf.random_normal([1]),name="weights2")
W_3 = tf.Variable(tf.random_normal([1]),name="weights3")
b = tf.Variable(tf.random_normal([1]),name="bias")
#计算预测结果
Y_pred = tf.multiply(X,W)+ b + tf.multiply(tf.pow(X,2),W_2)+ tf.multiply(tf.pow(X,3),W_3)
#计算损失值
loss = tf.reduce_mean(tf.pow(Y_pred-Y,2))
#初始化optimizer
learning_rate = 0.01
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
#执行
n_samples = xs.shape[0]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# writer = tf.summary.FileWriter("E:/TensorFlow/July/chapter2/log",sess.graph)
# for i in range(1000):
# total_loss = 0
# for x,y in zip(xs,ys):
# _,l = sess.run([optimizer,loss],feed_dict={X:x,Y:y})#有两个结果,第一个不要,用_
# total_loss += l
# if i%20 == 0:
# print("Epoch{0}:{1}".format(i,total_loss/n_samples))
for i in range(1000):
_, total_loss= sess.run([optimizer, loss], feed_dict={X: xss, Y: yss}) # 有两个结果,第一个不要,用_
if i % 20 == 0:
print("Epoch{0}:{1}".format(i, total_loss))
writer = tf.summary.FileWriter("E:/TensorFlow/July/chapter2/log", sess.graph)
writer.close()
W,W_2,W_3,b = sess.run([W,W_2,W_3,b])
print(W)
print(W_2)
print(W_3)
print(b)
plt.figure(1)
plt.plot(xs,ys,'bo',label="Real data")
plt.plot(xs,np.power(xs,3)*W_3+np.power(xs,2)*W_2+xs*W+b,'r',label="Predicted data")
plt.legend()
plt.show()
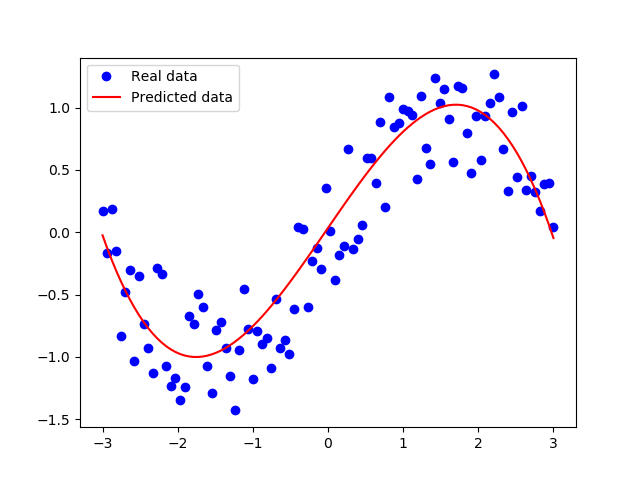
可以看出来拟合效果很好。其实就是sin函数的泰勒展开。
有一个问题,在做的过程中发现,
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)换成
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)程序运行会出问题,不知道为什么。
逻辑回归
https://www.cnblogs.com/Belter/p/6128644.html
输出只有两个值,0,1。多个输出节点,解决分类问题,例如mnist分类。
第三讲
常用数据集
CIFAR-10
10类,50000张训练图片,10000张测试图片,32*32*3图像
官网http://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-100
100类,50000张训练图片,10000张测试图片,32*32*3图像
官网http://www.cs.toronto.edu/~kriz/cifar.html
SVHN:
斯坦福大学,http://ufldl.stanford.edu/housenumbers/
10类,73257张训练图片,26032张测试图片,32*32*3

Caltech101:李飞飞构建
101类,~5050张图片,300*200*3
Imagenet:
1000类,1.4M图片,归一化为256*256*3
卷积层
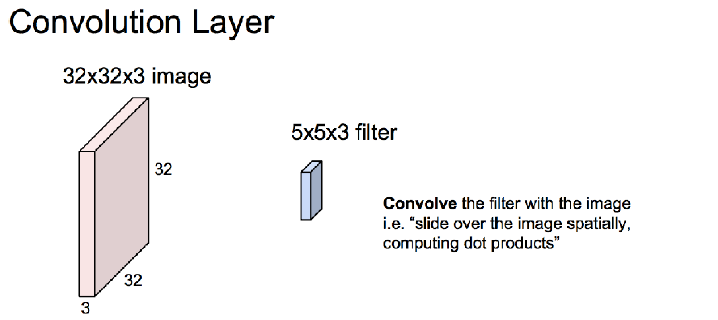

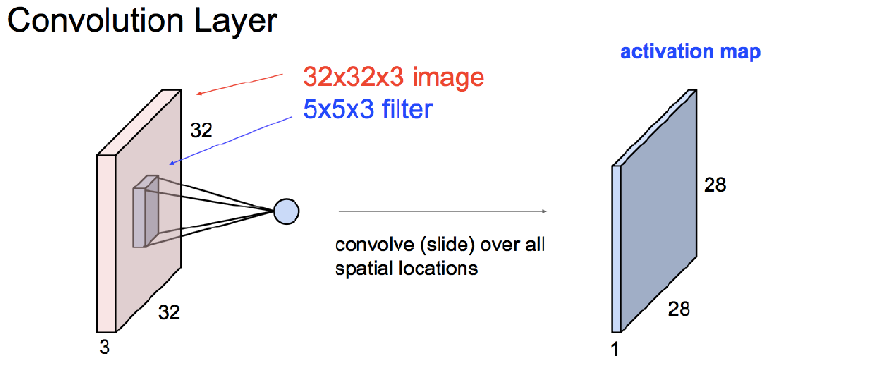
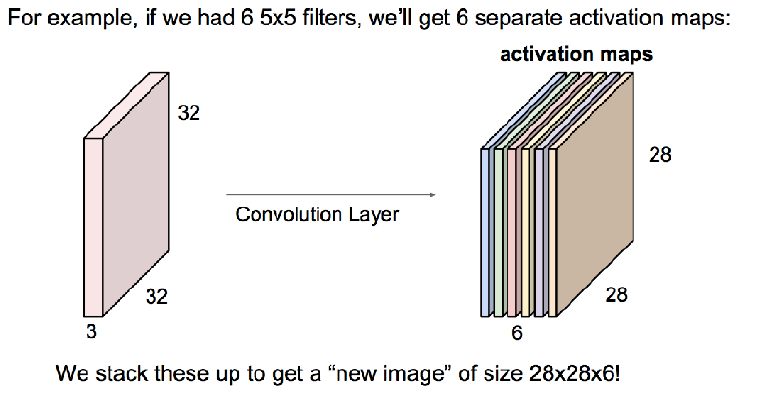




注意:一个卷积核对彩色图像卷积后,得到的是一张图像,只有两个维度。比如原图32*32*3,卷积核5*5*3,得到的是28*28,不是28*28*3,这里相当于把彩色图像转化为黑白图像了。
每次做完卷积都要做非线性变换。
卷积时不应该先转置再求点积(内积)么?(正常卷积是要选旋转180度)
如果存在一个卷积核,它的值满足要求。因为对称的关系,一定存在另外一个卷积核,使得另外一个卷积核做转置后,再做内积,它的效果是一样的。所以就没有必要转置了。
输出图片大小
不使用0填充时候

使用0填充时
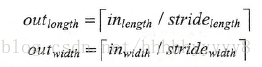
卷积层的步长一般为1,但是在有些模型中也会使用2,或者3作为步长
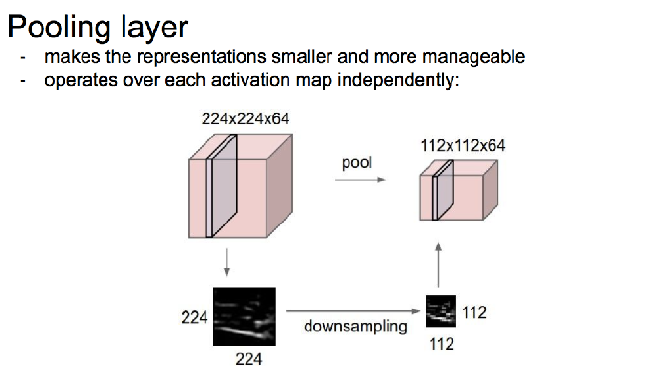
池化层
使用最多的是最大池化层,边长一般为2或者3,步长也一般为2或者3。
会丢失图像信息。得出结果也会更鲁棒一些。
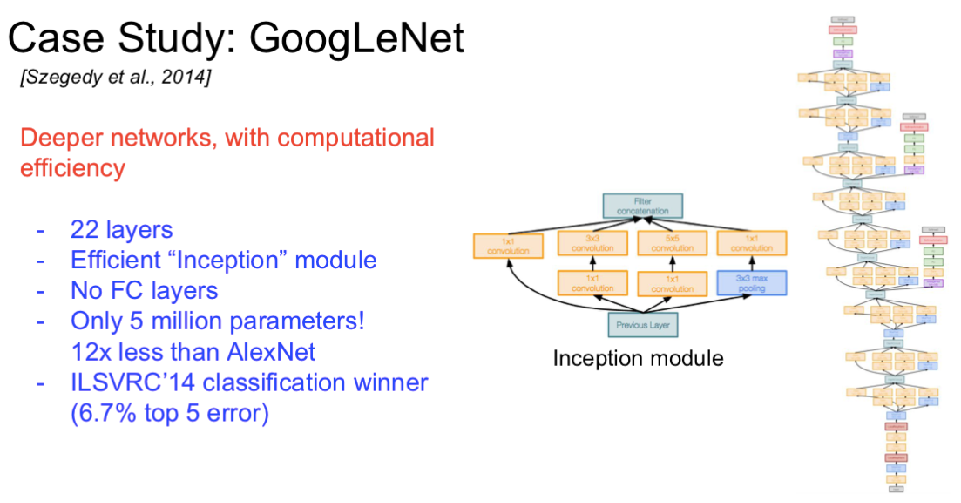
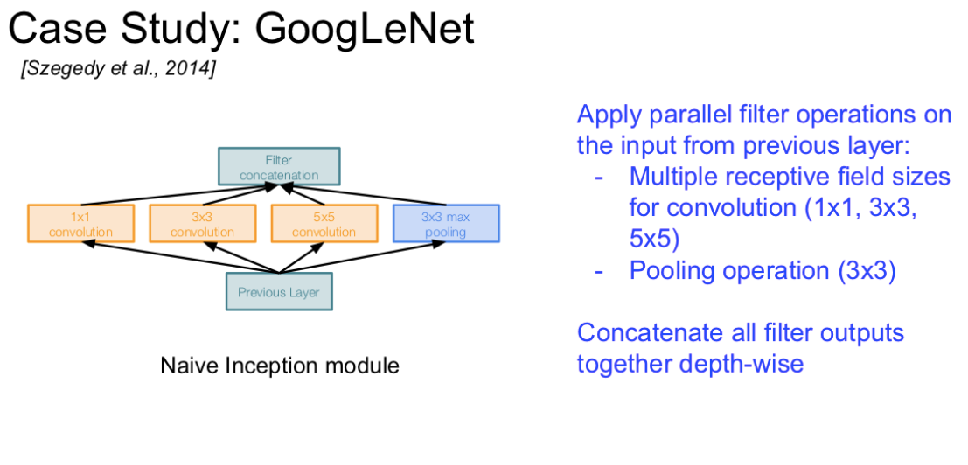
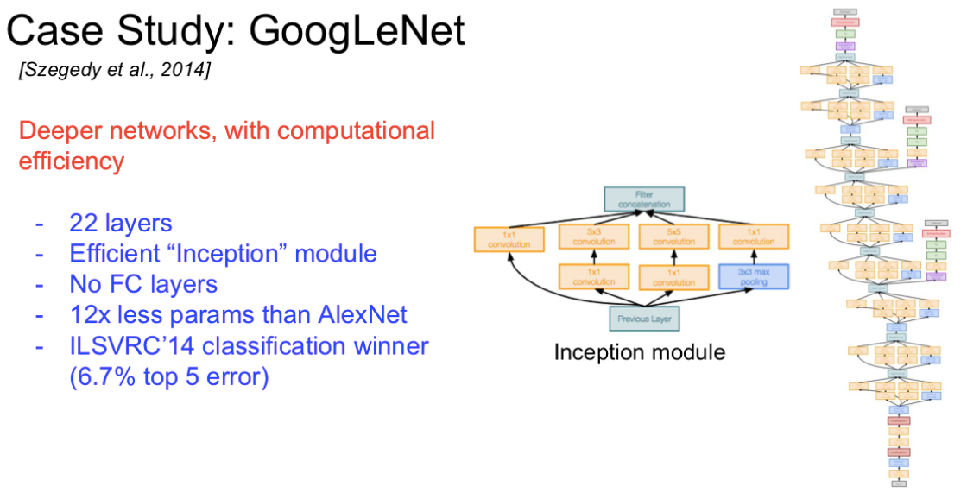
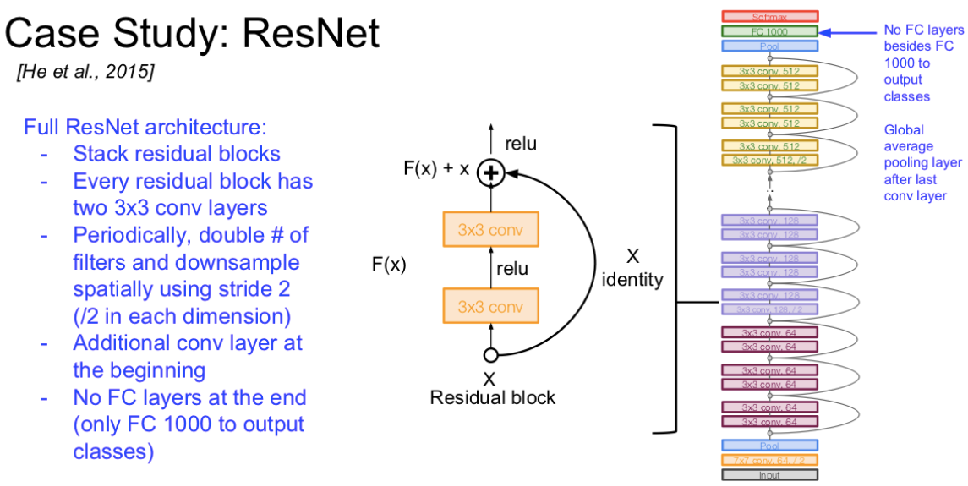
经典神经网络架构