由于之前研究了一下JVM的内存划分,对里面方法区的常量池一知半解,于是想要探究一下
先看这篇 写得比较清晰
https://blog.csdn.net/tophawk/article/details/78704074(jdk1.8版本)
https://blog.csdn.net/youyou1543724847/article/details/52337257
以下内容有点儿乱,还未整理好,参考了
https://blog.csdn.net/zm13007310400/article/details/77534349
https://www.cnblogs.com/holos/p/6603379.html
https://blog.csdn.net/qq_31142587/article/details/78203382
主要问题:
String s1="abc";编译期检查字符串常量池有abc,直接返回s1,abc的引用,如果没有abc,堆中创建abc对象并在字符串常量池中增加他的引用这个过程是在编译期实现还是下文所说的经过验证,准备阶段之后才生成abc实例的??可能只要是由于Jdk版本问题?
方法区和常量池
方法区里存放着类的版本,字段,方法,接口和常量池。
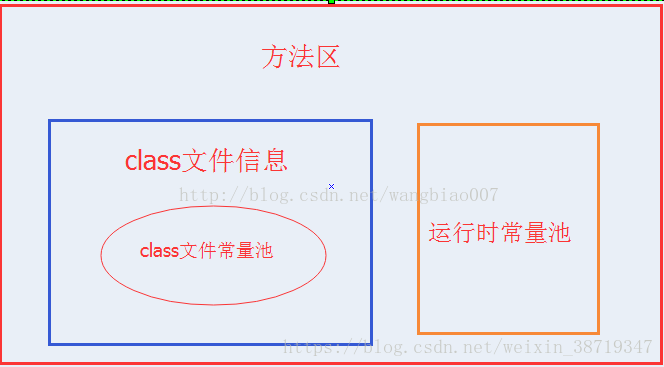
下面一张图用来表示方法区class文件信息包括哪些内容:
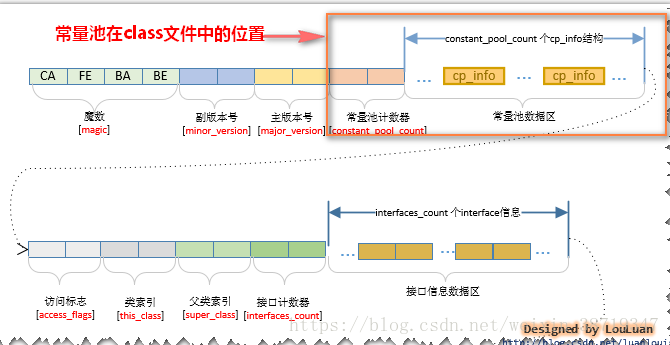
class常量池
- 我们写的每一个Java类被编译后,就会形成一份class文件;class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic References);
- 字面量包括:1.文本字符串 2.八种基本类型的值 3.被声明为final的常量等;
- 符号引用包括:1.类的全限定名,2.字段名和属性,3.方法名和属性。
- 每个class文件都有一个class常量池。
- class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量的符号引用,也就是说他们存的并不是对象的实例。
方法区中的运行时常量池
java文件被编译成class文件之后,也就是会生成我上面所说的class常量池。那么运行时常量池又是什么时候产生的呢?
jvm在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。而当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,运行时常量池存在于内存中,也就是class常量池被加载到内存之后的版本,不同之处是:它的字面量可以动态的添加(String#intern()),符号引用可以被解析为直接引用。
运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。解析的过程会去查询全局字符串池,也就是我们下面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
解析的过程会去查询字符串常量池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与字符串常量池中是一致的。
运行时常量池相对于CLass文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的intern()方法。(研究Intern())
常量池的好处
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
- 节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
- 节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
字符串常量池
- 字符串常量池在Java内存区域的哪个位置
- 在JDK6.0及之前版本,字符串常量池是放在Perm Gen区(也就是方法区)中;
- 在JDK7.0版本,字符串常量池被移到了堆中了。至于为什么移到堆内,大概是由于方法区的内存空间太小了。
- 字符串常量池放的是什么
- 在JDK6.0及之前版本中,String Pool里放的都是字符串常量
- 在JDK7.0中,由于String#intern()发生了改变,因此String Pool中也可以存放放于堆内的字符串对象的引用
需要说明的是:字符串常量池中的字符串只存在一份!
例
String s1 = "hello,world!";
String s2 = "hello,world!";即执行完第一行代码后,常量池中已存在 “hello,world!”的引用,那么 s2不会在常量池中申请新的空间,而是直接把已存在的字符串内存地址返回给s2。
全局字符串常量池(就是字符串常量池,全局我认为是强调只有一个,被所有类共享)里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的。)。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表(添加哈希学习),里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
例子
String a = "abc";
String b = "abc";
System.out.println(a == b);答案为true
String a = "abc";
System.out.println(a == "abc");答案为false
分析:首先实例化了”abc”字符串并将引用存放到JVM的常量池中。
常量池分为编译期常量池和运行时常量池
a == “abc”这段代码里的”abc”是未赋值的的,jvm会对String常量的运算进行优化,未声明的字符串不会在编译期常量池中,只有当你运行时才会实例化字符串到运行时常量池中,而声明的a在编译器常量池,所以为false。让我们回到print(a == b) //true print这段代码在JVM编译期可能会跳过,所以,在print内部定义的”abc”是运行期获取的,比较对象地址,结果输出为true。