docker默认日志管理
docker部署完成后,运行docker info命令,如下图所示:
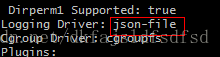
上图中红框内的"json-file",指的是当启动某个容器时,如果不特别指定容器所采用的log驱动,则使用json-file这种方式。当采用这种方式的容器在创建时,docker daemon会首先在宿主机上创建一个与这个容器相关联的文件,当容器运行时,docker daemon会转储容器在运行过程中向stdout与stderr输出的内容,并保存在刚才创建的那个文件中。当在宿主机中运行“docker logs -f 容器名”时,docker daemon就会跟踪宿主机文件的内容,并显示在终端上。
以nginx为例,首先看一下Dockerfile文件,会发现如下内容:
# forward request and error logs to docker log collector
RUN ln -sf /dev/stdout /var/log/nginx/access.log \
&& ln -sf /dev/stderr /var/log/nginx/error.log以上是docker默认管理容器日志的方式。在docker集群中,容器的数量很多,容器的生命周期及运行时进驻的node也是动态变化的,以上方式并不能满足大规模docker集群的日志管理要求。
创建docker swarm集群
参考https://blog.csdn.net/dkfajsldfsdfsd/article/details/79923218创建包含三个node的docker集群,结果如下图所示:

部署ELK集群管理
1.修改内存地址映射mmp的系统限制
elasticsearch是一个文档数据库,以mmap的方式管理索引。mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式,向操作内存一样读写文件。mmap以页为单位实现映射,操作系统对页的的数量有限制,默认的值太小,elasticsearch要求的最小值是262144,小于此值elasticsearch无法启动。分别在三个node上执行以下命令,临时扩大这种限制:
sysctl -w vm.max_map_count=2621442.创建docker compose文件/root/elk/docker-stack.yml文件,文件内容如下:
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.3.2
environment:
ES_JAVA_OPTS: '-Xms256m -Xmx256m'
xpack.security.enabled: 'false'
xpack.monitoring.enabled: 'false'
xpack.graph.enabled: 'false'
xpack.watcher.enabled: 'false'
volumes:
- esdata:/usr/share/elasticsearch/data
deploy:
replicas: 1
placement:
constraints:
- node.hostname == manager
logstash:
image: docker.elastic.co/logstash/logstash:5.3.2
volumes:
- ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
depends_on:
- elasticsearch
deploy:
replicas: 1
logspout:
image: bekt/logspout-logstash
environment:
ROUTE_URIS: 'logstash://logstash:5000'
volumes:
- /var/run/docker.sock:/var/run/docker.sock
depends_on:
- logstash
deploy:
mode: global
restart_policy:
condition: on-failure
delay: 30s
kibana:
image: docker.elastic.co/kibana/kibana:5.3.2
ports:
- '80:5601'
depends_on:
- elasticsearch
environment:
ELASTICSEARCH_URL: 'http://elasticsearch:9200'
XPACK_SECURITY_ENABLED: 'false'
XPACK_MONITORING_ENABLED: 'false'
deploy:
replicas: 1
volumes:
esdata:
driver: local总共包含四个服务,解释如下:
elasticsearch:文档数据库,用来存储收集到的日志。数据库是有状态的,需要使用宿主机的文件系统存储数据,因此设置了"node.hostname == manager"的约束条件,只能部署在manager节点上,不能迁移到其它node上,避免数据丢失,只部署一个实例。
logstash:从所有的数据源收集数据并对数据做预处理,然后再提交给elasticsearch,只部署一个实例,无状态,对node无要求。
logspout:从各个node收集数据,然后交给logstash预处理,全局部署。
kibana:UI界面,负责展示数据,只部署一个实例,无状态,对node无要求。
3.创建logstash配置文件/root/elk/logstash/logstash.conf,内容如下:
input {
udp {
port => 5000
codec => json
}
}
filter {
if [docker][image] =~ /logstash/ {
drop { }
}
}
output {
elasticsearch { hosts => ["elasticsearch:9200"] }
stdout { codec => rubydebug }
}包含三部分,解释如下:
input:表示logstash监听在udp的5000端口收集数据。
fileter:过滤器,表示过滤掉image为logstash的容器实例上报上来的数据。
output:表示如何上报过滤后的数据,这里是通过9200端口上报到elasticsearch数据库。
4.创建elk容器栈
在/root/elk目录下执行如下指令:
docker stack deploy -c docker-stack.yml elk命令返回以后,并不代表容器栈创建成功,需要花一点时间,运行docker stack ps elk,并显示如下结果时,表示创建完成:
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
jqr1m6ts21p3 logging_logspout.pt27y28y0t5zzph3oi72tmy58 bekt/logspout-logstash:latest agent2 Running Running about a minute ago
4zwvtt3momu3 logging_logspout.9m6jopba7lr0o40hw9nwe7zfb bekt/logspout-logstash:latest agent1 Running Running about a minute ago
mgpsi68gcvd9 logging_logspout.ub1sl7d5fy9dbnlx8um67a03t bekt/logspout-logstash:latest manager Running Running about a minute ago
unz9qrfit8li logging_logstash.1 logstash:alpine agent1 Running Running 2 minutes ago
jjin64lsw2dr logging_kibana.1 docker.elastic.co/kibana/kibana:5.3.0 agent2 Running Running 2 minutes ago
orzfd05rzq8e logging_elasticsearch.1 docker.elastic.co/elasticsearch/elasticsearch:5.3.0 agent1 Running Running 3 minutes ago5.创建默认索引模式
在浏览器中打开"http://manager ip"访问kibana,首次访问的会要求创建默认索引模式,如下图所示:
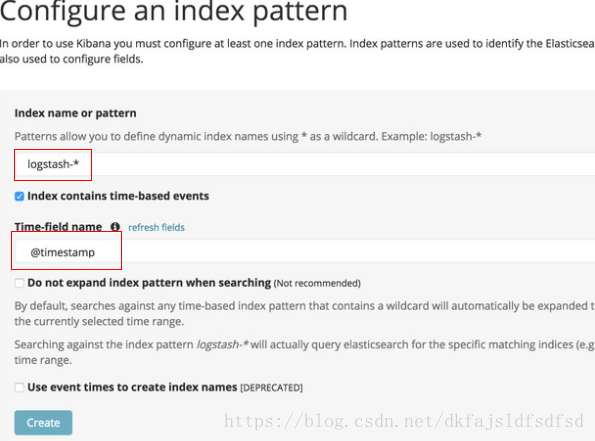
填入上图中红框内所示内容并点击"Create"按钮,完成创建。接下来就可以在"Discover"表中浏览收集到的所有log,并且会在右会显示log中包含的所有field,如docker.name、docker.image,如果field是数字的话,点击这个field还会显示截止目前的最大值、最小值等。
6.部署nginx服务确认效果
编辑如下nginx服务编排文件:
version: '3'
services:
nginx:
image: hanzel/nginx-html
ports:
- "8000:80"
deploy:
replicas: 3运行如下命令完成部署:
docker stack deploy -c nginx.yml nginx完成部署以后,在浏览器中访问nginx以产生一些log。然后刷新kibana,如下图所示:
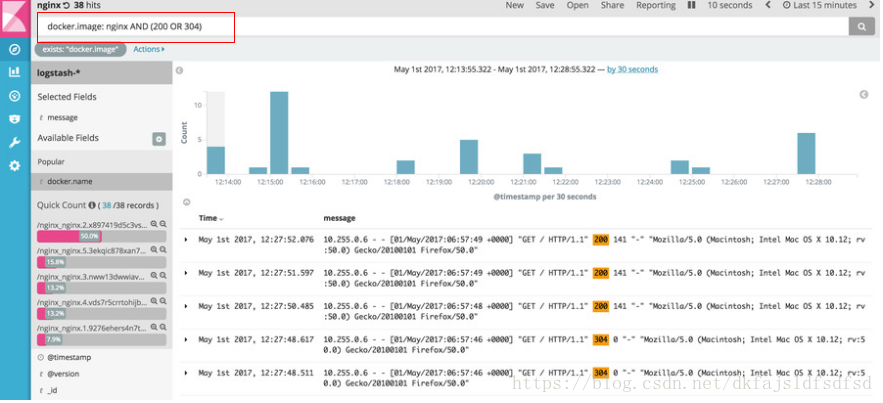
按上图红框输入过滤条件,就能查询出所有image是nginx,包含"200"与"304"关键字的log条目。
7.清理elk
实验结束后,执行以下命令清理elk:
docker stack rm elk
docker stack rm nginx特别声明:本文参考自https://botleg.com/stories/log-management-of-docker-swarm-with-elk-stack/,以上每一步都经过验证无误。因为使用的是日常的笔记本,部署完成以后,笔记本资源基本耗尽,不方便截图,文中所使用图片均引自https://botleg.com/stories/log-management-of-docker-swarm-with-elk-stack/。