问题引入
对于给定的任意一个网址,爬取这个网页上的所有文本信息,并抽取出文本的中文和英文关键词
搭建环境
首先需要具备eclipse开发环境。然后导入jsoup包,用来爬取网页,再到这个网址http://hanlp.linrunsoft.com/services.html下载并按步骤导入HanLP的包,用来抽取关键词
项目文件架构
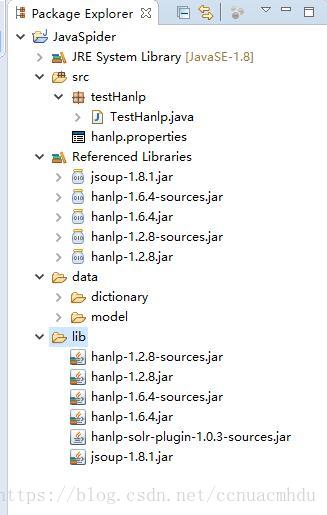
源代码及说明
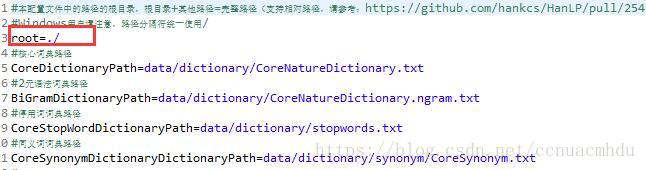
1、配置文件hanlp.properties出现中文乱码问题,可以调gbk为utf-8,注意这里面的路径问题如下:
2、笔者分别抽取了一个网页上文本信息中的中文和英文的关键词,一同输出。抽取英文的时候,笔者用了一个小小的巧妙的技巧——把空格统计到英文里去(具体见代码,这样直接就实现了英文的分割)
package testHanlp;
import java.io.IOException;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.hankcs.hanlp.HanLP;
public class TestHanlp {
public static void Get_Url(String url) {
StringBuffer English=new StringBuffer();
StringBuffer Chinese=new StringBuffer();
try {
Document doc = Jsoup.connect(url) .get();
Elements body = doc.getElementsByTag("body");
for (Element Text : body) {
String text = Text.text();
for(int i=0;i<text.length();i++) {
char c=text.charAt(i);
if(c >= 0x4E00 && c <= 0x9FA5) {
Chinese.append(c);
}
else if ((c>='a' && c<='z') || (c>='A' && c<='Z') || c==' ') {
English.append(c);
}
}
}
}
catch (IOException e) {
e.printStackTrace();
}
String EnglishText=new String(English);
String ChineseText=new String(Chinese);
List<String> EnglishKeywordList = HanLP.extractKeyword(EnglishText, 5);
List<String> ChinesekeywordList = HanLP.extractKeyword(ChineseText, 5);
System.out.println(EnglishKeywordList);
System.out.println(ChinesekeywordList);
}
public static void main(String[] args) {
String url ="https://github.com/";
Get_Url(url);
}
}效果展示
下面我对人民日报官网的一个网页人民日报的一个网页进行爬取,并抽取关键词如下:

下面我对GitHub主页进行爬取如下:

笔者未解决问题
如何导出可以执行的jar包,这个问题没有解决,笔者参考很多教程,始终没有导出一个可以执行的jar包!导出的jar包在命令行下运行总是出错