1. 整体把握
一般都可以想到 的暴力算法,KMP改进暴力算法使其算法复杂度为O(m+n)。本文参考:维基百科。
2.算法学习
2.1 使用局部匹配表
- To illustrate the algorithm’s details, consider a (relatively artificial) run of the algorithm, where W = “ABCDABD” and S = “ABC ABCDAB ABCDABCDABDE”. At any given time, the algorithm is in a state determined by two integers:
- m, denoting the position within S where the prospective match for W begins,
i, denoting the index of the currently considered character in W.
通过例子学习KMP,先从以上定义确定W、S、m、i分别代表的意义,然后看几个规则:
- For the moment, we assume the existence of a “partial match” table T, described below, which indicates where we need to look for the start of a new match in the event that the current one ends in a mismatch.
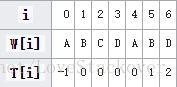
局部匹配表的意义- The entries of T are constructed so that if we have a match starting at S[m] that fails when comparing S[m + i] to W[i], then the next possible match will start at index m + i - T[i] in S (that is, T[i] is the amount of “backtracking” we need to do after a mismatch).
局部匹配表如何使用
- This has two implications: first, T[0] = -1, which indicates that if W[0] is a mismatch, we cannot backtrack and must simply check the next character;
- and second, although the next possible match will begin at index m + i - T[i], as in the example above, we need not actually check any of the T[i] characters after that, so that we continue searching from W[T[i]].
假设我们有一个partial match table(如下图所示),重复上面查表的规则和方法,我们可以手动复现下面的KMP算法过程:
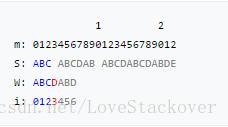
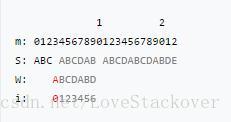
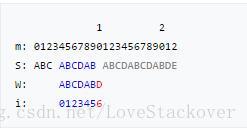
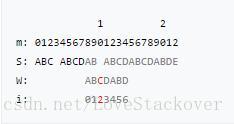
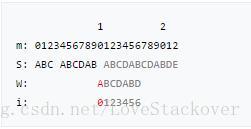
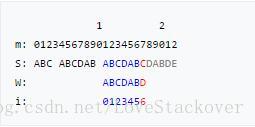
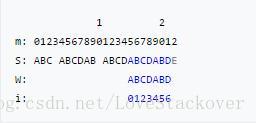
特别强调:每次当前母串中 位置失配时,查表中对应的i的值,然后将下一次匹配的位置设置为 ,但是只需要从T[i]处开始匹配就可以了。
2.2 构造局部匹配表
没有优化的构造方法
由”ABCDABD”构造其局部匹配表如上图所示,过程如下:
- We consider the example of W = “ABCDABD” first. We will see that it follows much the same pattern as the main search, and is efficient for similar reasons. We set T[0] = -1.
T[0]默认为-1,注意当前是i位置发生了失配- To find T[1], we must discover a proper suffix of “A” which is also a prefix of pattern W. But there are no proper suffixes of “A”, so we set T[1] = 0.
这里需要了解前缀和后缀的定义- To find T[2], we see that the substring W[0] - W[1] (“AB”) has a proper suffix “B”. However “B” is not a prefix of the pattern W. Therefore, we set T[2] = 0.
不同于说是AB子串的前缀,而强调了是W的前缀,这里为下面的简易判断方式做了铺垫。- 3Continuing to T[3], we first check the proper suffix of length 1, and as in the previous case it fails. Should we also check longer suffixes?
- No, we now note that there is a shortcut to checking all suffixes: let us say that we discovered a proper suffix which is a proper prefix (A proper prefix of a string is not equal to the string itself) and ending at W[2] with length 2 (the maximum possible); then its first character is also a proper prefix of W, hence a proper prefix itself, and it ends at W[1], which we already determined did not occur as T[2] = 0 and not T[2] = 1. Hence at each stage, the shortcut rule is that one needs to consider checking suffixes of a given size m+1 only if a valid suffix of size m was found at the previous stage (i.e. T[x] = m) and should not bother to check m+2, m+3, etc.
通过反证法,证明了T[i]与T[i-1]的一些关系
理解最为困难的就是第二点,在T[3]上我们本应该检查前后缀长度为1和2,但是由于T[2]等于0,所以我们只需要检查长度为1的前后缀。用DP的思想很容易理解,因为T[i]的最长前后缀应该是T[i-1]的基础上再拓展一个字符。当然,并不一定T[3]的最长前后缀长度一定为T[i-1]+1,只是说我们需要检查的长度范围为0到T[i-1]+1。
优化的构造方法
有人称之为优化的KMP算法,实际上维基百科直接给的就是优化后的版本,而没有提及上面的优化前的版本,这种优化通过观察在构建局部匹配表上做了改进。维基上的内容不是很好理解,根据这篇,很快理解了优化的本质。如下公式所示:

在编程上的实现比思想上更加简单,只要在没有优化的版本增加判断条件,进行优化就可以了。
3. 伪代码
学习伪代码,然后尝试自己去实现,在某些字符串的题目中,KMP给我们提供了
的备用函数,结合深度搜索可以解决很多复杂的问题。
algorithm kmp_search:
input:
an array of characters, S (the text to be searched)
an array of characters, W (the word sought)
output:
an array of integers, P (positions in S at which W is found)
an integer, nP (number of positions)
define variables:
an integer, j ← 0 (the position of the current character in S)
an integer, k ← 0 (the position of the current character in W)
an array of integers, T (the table, computed elsewhere)
let nP ← 0
while j < length(S) do
if W[k] = S[j] then
let j ← j + 1
let k ← k + 1
//如果k=length w 那么代表一个完整的匹配完成
if k = length(W) then
(occurrence found, if only first occurrence is needed, m may be returned here)
//记录这个匹配信息 模式串开始位置位j-k(模式串长度) np+1,括号里面的话的意思,如果只要找到第一个匹配完成的位置,则这里直接return就可以了。
let P[nP] ← j - k, nP ← nP + 1
//重新开始,这里和失配的处理一样,因为即使这个匹配完成了,也存在前面的字符后面匹配的一部分,所以必须trackback
let k ← T[k] //(T[length(W)] can't be -1)
else
//失配发生的时候,直接trackback
let k ← T[k]
//如果k<0的时候,直接跳到下一个字符
if k < 0 then
let j ← j + 1
let k ← k + 1 仔细观察发现没有
了,在上面的算法学习部分是有个
标志模式串起始位置的,这里基于两个思考:
注意上面的j是先增加了1,所以这里为
j-k。上面的伪代码实现起来应该很容易,然后看局部匹配表的伪代码如下:
//未优化的版本,伪代码:
algorithm kmp_table:
input:
an array of characters, W (the word to be analyzed)
an array of integers, T (the table to be filled)
output:
nothing (but during operation, it populates the table)
define variables:
an integer, pos ← 2 (the current position we are computing in T)
an integer, cnd ← 0 (the zero-based index in W of the next
character of the current candidate substring)
(the first few values are fixed but different from what the algorithm
might suggest)
let T[0] ← -1, T[1] ← 0
//pos从3开始,所以刚开始的判断为w[1],w[0],cnd=0 注意cnd代表了当前substring的最长前缀的下一个值。
while pos < length(W) do
(first case: the substring continues)
if W[pos - 1] = W[cnd] then
let cnd ← cnd + 1, T[pos] ← cnd, pos ← pos + 1
//如果没有拓展这个最长前缀,按照上面的算法我们应该以--cnd>=0的方式检查
//但是这样会判断多余的长度,采用cnd=T[cnd]避免检查没有必要的最长前缀长度
(second case: it does not, but we can fall back)
else if cnd > 0 then
let cnd ← T[cnd]
//第三种情况,从T[pos-1]的cnd值直到0都检查过了,没有符合要求的前后缀,则此时设置T[pos]=0;
(third case: we have run out of candidates. Note cnd = 0)
else
let T[pos] ← 0, pos ← pos + 1 对于cnd=T[cnd],其实网上很多人都困惑,但它并不是KMP算法的原理部分,而是编程者的技巧,这种编程技巧源自一种观察:

观察i=10,此时因为p[pos-1] != p[cnd](此时pos=10 cnd=2),执行cnd=T[cnd]。我们知道了p[pos-1] != p[cnd]的事实,从KMP原理上此时cnd应该为2,去检查PA == AT?,不过可以多思考一步,如果AT能成为pos=10的W的最长前缀,那么A一定PA的最长前缀。按照这种逻推广到一般情形,遇到上面p[pos-1] != p[cnd]的情况时,下一步应该检查的最长前缀的长度为T[cnd],而不是cnd-1。这里需要多想想,再次强调这是编程方式的一种优化。再看看优化后的KMP算法的局部匹配表的构造算法:
//经过优化的局部匹配表构造算法
algorithm kmp_table:
input:
an array of characters, W (the word to be analyzed)
an array of integers, T (the table to be filled)
output:
nothing (but during operation, it populates the table)
define variables:
an integer, pos ← 2 (the current position we are computing in T)
an integer, cnd ← 0 (the zero-based index in W of the next
character of the current candidate substring)
(the first few values are fixed but different from what the algorithm
might suggest)
let T[0] ← -1, T[1] ← 0
while pos < length(W) do
(first case: the substring continues)
if W[pos - 1] = W[cnd] then
let cnd ← cnd + 1, T[pos] ← cnd, pos ← pos + 1
(second case: it does not, but we can fall back)
else if cnd > 0 then
let cnd ← T[cnd]
//注意这里的continue,不能省略
continue;
(third case: we have run out of candidates. Note cnd = 0)
else
let T[pos] ← 0, pos ← pos + 1
//源自上面的原理,很容易得到修改上面的伪代码。
if p[T[pos-1]] == p[pos-1]
T[pos-1]=T[T[pos-1]]4. 总结
KMP算法记录篇远没有结束,还需要自己转化成C++代码,并且实战一个算法题。对于字符串的算法题目,使用回溯加KMP能解决一些难度较大的算法题。