一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,
也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,
fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。这种父子进程和链表的结构很像,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id,因为子进程没有子进程,所以其fpid为0.
来看下示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global=6;
char buf[]="a write to stdout\n";
int main()
{
int var;
pid_t pid;
pid_t pid_parent;
var=0;
if(write(STDOUT_FILENO,buf,sizeof(buf)-1) != sizeof(buf)-1)
printf("error");
if((pid=fork()) == 0){
global++;
var++;
}
else{
sleep(2);
}
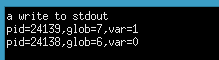
printf("pid=%ld,glob=%d,var=%d\n",(long)getpid(),global,var);
exit(0);
return 0;
}
运行结果如下:从结果中可以看到在父进程和子进程中,glob和var的值不一样。在子进程中对glob和var修改的操作并没有影响父进程中的值。这是因为虽然子进程获取了父进程的数据空间,堆和栈的副本,但是并没有获取存储空间部分。也就是说父进程和子进程并不共享这些存储空间部分。
接下来继续看下fork函数的另一个升级版本,vfork函数。vfork函数和fork函数的区别如下:
1
fork():子进程拷贝父进程的数据段,代码段
vfork():子进程与父进程共享数据段
2
fork(): 父子进程的执行顺序不确定
vfork(): 保证子进程先运行,在调用exit或者exec后父进程才有可能被调用。如果在调用exit和exec前子进程依赖于父进程的进一步动作则会导致死锁。
程序修改如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global=6;
char buf[]="a write to stdout\n";
int main()
{
int var;
pid_t pid;
pid_t pid_parent;
var=0;
if(write(STDOUT_FILENO,buf,sizeof(buf)-1) != sizeof(buf)-1)
printf("error");
if((pid=vfork()) == 0){
global++;
var++;
_exit(0);
}
printf("pid=%ld,ppid=%ld,glob=%d,var=%d\n",(long)getpid(),(long)getppid(),global,var);
exit(0);
return 0;
}
运行结果:从结果中可以发现2点:
1 子进程对变量加1的操作,结果改变了父进程中的变量值。因为子进程在父进程的地址空间中运行。
2 只有一个打印,而非两个打印,原因在于子进程退出的时候执行了_exit()操作,在exit中关闭了标注I/O流,那么表示标准输出FILE对象的相关存储区将被清0。因为子进程借用了父进程的地址空间。所以当父进程恢复运行并调用printf的时候,也就不会产生任何输出了。printf返回-1.

wait和waitpid函数:
在前面介绍的父子进程中,当进程退出时,它向父进程发送一个SIGCHLD信号,默认情况下总是忽略SIGCHLD信号,此时进程状态一直保留在内存中,直到父进程使用wait函数收集状态信息,才会清空这些信息. 用wait来等待一个子进程终止运行称为回收进程.当父进程忘了用wait()函数等待已终止的子进程时,子进程就会进入一种无父进程的状态,此时子进程就是僵尸进程. 僵尸进程不占用内存也不占用CPU,表面上可以忽略他们的存在。但是事实上linux操作系统限制了某一时刻同时存在的进程的最大数目。如果程序不能及时清理系统中的僵尸进程。最终会导致进程数过多,当再次需要新进程的时候就会出错。因此我们需要在子进程exit后在父进程中调用wait或waitpid.
进程一旦调用了wait,就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何死掉的毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样想),我们就可以设定这个参数为NULL,就象下面这样:
pid = wait(NULL);
如果成功,wait会返回被收集的子进程的进程ID,如果调用进程没有子进程,调用就会失败,此时wait返回-1,同时errno被置为ECHILD。
代码如下:
void wait_function_test(){
pid_t pr,pc;
pc=fork();
if (pc < 0){
printf("error");
}
else if(pc == 0){
printf("this is child process with pid of %d\n",getpid());
sleep(10);
}
else{
pr=wait(NULL);
printf("I catched a child process with pid of %d\n",pr);
}
exit(0);
}
执行结果如下:在第2行结果打印出来前有10 秒钟的等待时间,这就是我们设定的让子进程睡眠的时间,只有子进程从睡眠中苏醒过来,它才能正常退出,也就才能被父进程捕捉到

如果参数status的值不是NULL,wait就会把子进程退出时的状态取出并存入其中,这是一个整数值(int),指出了子进程是正常退出还是被非正常结束的,以及正常结束时的返回值,或被哪一个信号结束的等信息。由于这些信息被存放在一个整数的不同二进制位中,所以用常规的方法读取会非常麻烦,人们就设计了一套专门的宏(macro)来完成这项工作。
1、WIFEXITED(status) 这个宏用来指出子进程是否为正常退出的,如果是,它会返回一个非零值(请注意,虽然名字一样,这里的参数status并不同于wait唯一的参数---指向整数的指针status,而是那个指针所指向的整数,切记不要搞混了)
2、WEXITSTATUS(status) 当WIFEXITED返回非零值时,我们可以用这个宏来提取子进程的返回值,如果子进程调用exit(5)退出,WEXITSTATUS(status) 就会返回5;如果子进程调用exit(7),WEXITSTATUS(status)就会返回7。请注意,如果进程不是正常退出的,也就是说, WIFEXITED返回0,这个值就毫无意义。
代码修改如下:
void wait_function_test(){
pid_t pr,pc;
int status;
pc=fork();
if (pc < 0){
printf("error");
}
else if(pc == 0){
printf("this is child process with pid of %d\n",getpid());
exit(3);
}
else{
pr=wait(&status);
if(WIFEXITED(status)){
printf("the child process %d exit normally\n",pr);
printf("the return code is %d.\n",WEXITSTATUS(status));
}
else{
printf("The child process %d exit abnormally",pr);
}
}
exit(0);
}
父进程准确捕捉到了子进程的返回值3,并把它打印了出来。

下面来看一个wait函数的升级版waitpid. 前面的函数中,如果一个进程有几个子进程,那么只要一个进程终止,wait就返回。如果要等待一个指定的进程终止比如知道某个进程的PID,那么该如何做呢,我们可以调用wait然后将其返回的进程ID和我们期望的ID相比较。如果不相同,则将该进程ID保存起来继续调用wait,反复这样做直到所期望的进程终止。这样比较麻烦,而采用waitpid则可以等待特定的进程函数。
waitpid多出了两个可由用户控制的参数pid和options,从而为我们编程提供了另一种更灵活的方式。下面我们就来详细介绍一下这两个参数:
pid:从参数的名字pid和类型pid_t中就可以看出,这里需要的是一个进程ID。但当pid取不同的值时,在这里有不同的意义。
pid>0时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
pid=-1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
pid=0时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
pid<-1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
options:options提供了一些额外的选项来控制waitpid,目前在Linux中只支持WNOHANG和WUNTRACED两个选项,这是两个常数,可以用"|"运算符把它们连接起来使用,比如:
ret=waitpid(-1,NULL,WNOHANG | WUNTRACED);
如果我们不想使用它们,也可以把options设为0,如:
ret=waitpid(-1,NULL,0);
如果使用了WNOHANG参数调用waitpid,即使没有子进程退出,它也会立即返回,不会像wait那样永远等下去。
返回值和错误
waitpid的返回值比wait稍微复杂一些,一共有3种情况:
1、当正常返回的时候,waitpid返回收集到的子进程的进程ID;
2、如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
3、如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
当pid所指示的子进程不存在,或此进程存在,但不是调用进程的子进程,waitpid就会出错返回,这时errno被设置为ECHILD;
代码如下:
void wait_function_test(){
pid_t pr,pc;
pc=fork();
if (pc < 0){
printf("error");
}
else if(pc == 0){
sleep(10);
exit(3);
}
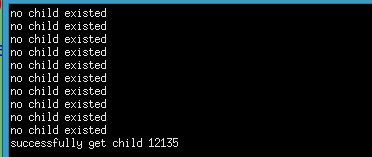
do{
pr=waitpid(pc,NULL,WNOHANG);
if(pr == 0){
printf("no child existed\n");
sleep(1);
}
}while(pr==0);
if(pr==pc){
printf("successfully get child %d\n",pr);
}
else{
printf("some error occured\n");
}
exit(0);
}
运行结果。可以看到即使没有子进程退出,设置了WNOHANG后,父进程也会立即返回,不会像wait那样永远等下去。