理解参考:https://blog.csdn.net/hduxiejun/article/details/71107285
原文参考:
1.U-Net: Convolutional Networks for Biomedical Image Segmentation (MICCAI2016)
2.Image Deformation Using Moving Least Squares
主要学习两点:
1.网络框架:用于图像分割以及特征提取
2.数据增强:学习平移不变性、学习形变deformation不变性
1.U-net框架

在深度学习应用到计算机视觉领域之前,人们使用 TextonForest 和 随机森林分类器进行语义分割。卷积神经网络(CNN)不仅对图像识别有所帮助,也对语义分割领域的发展起到巨大的促进作用。
语义分割任务最初流行的深度学习方法是图像块分类(patch classification),即利用像素周围的图像块对每一个像素进行独立的分类。使用图像块分类的主要原因是分类网络通常是全连接层(full connected layer),且要求固定尺寸的图像。
2014 年,加州大学伯克利分校的 Long 等人提出全卷积网络(FCN),这使得卷积神经网络无需全连接层即可进行密集的像素预测,CNN 从而得到普及。使用这种方法可生成任意大小的图像分割图,且该方法比图像块分类法要快上许多。之后,语义分割领域几乎所有先进方法都采用了该模型。
除了全连接层,使用卷积神经网络进行语义分割存在的另一个大问题是池化层。池化层不仅扩大感受野、聚合语境从而造成了位置信息的丢失。但是,语义分割要求类别图完全贴合,因此需要保留位置信息。本文介绍一种编码器-解码器结构。编码器逐渐减少空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节。U-Net 是这种方法中最常用的结构。
卷积层的数量大约在20个左右,4次下采样,4次上采样。输入图像大于输出图像,因为在本论文中对输入图像做了镜像操作。
结果:

如上图所示,对输入图像的四周做了镜像操作,其输入图像的大小为572*572,整个网络越有20个卷积层,输出图像的大小小于输入图像的大小。
2.U-net使用的数据增强技术
- 作者采用“滑动最小二乘法”进行deformation变化,从而使得网络学习到deformation不变性
- 作者采用高斯权重的距离偏移设置,从而使得网络学习到translation不变性
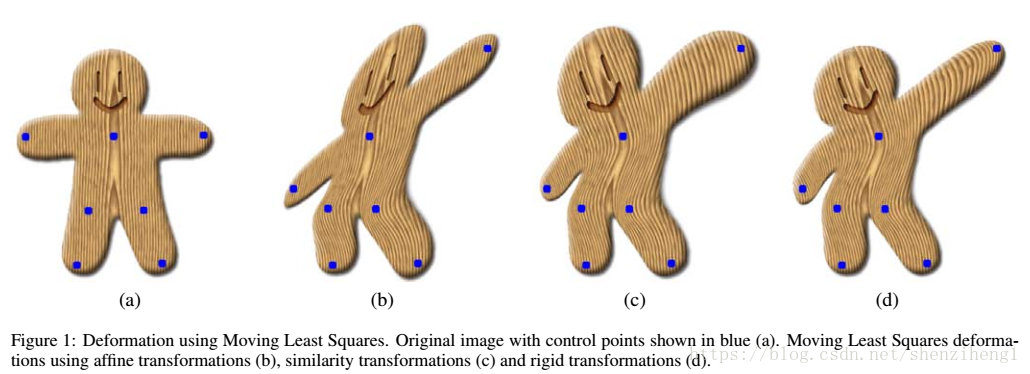
3.U-net在标签数据处理的特异之处
为了最大限度的使用GPU显存,比起输入一个大的batch size,作者更倾向于输入整张图像。此外作者使用了很高的momentum(0.99)。最后一层使用交叉熵函数与softmax(交叉熵函数如下所示):

为了使某些像素点更加重要,我们在公式中引入了w(x)。我们对每一张标注图像预计算了一个权重图,来补偿训练集中每类像素的不同频率,使网络更注重学习相互接触的细胞之间的小的分割边界。我们使用形态学操作计算分割边界。权重图计算公式如下:
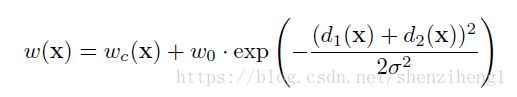
wc是用于平衡类别频率的权重图,d1代表到最近细胞的边界的距离,d2代表到第二近的细胞的边界的距离。基于经验我们设定w0=10,σ≈5像素。网络中权重的初始化:我们的网络的权重由高斯分布初始化,分布的标准差为(N/2)^0.5,N为每个神经元的输入节点数量。例如,对于一个上一层是64通道的3*3卷积核来说,N=9*64