矩阵分解的数据利用的上篇文章的数据,协同过滤
用到的知识
python的surprise
k折交叉验证
SVD
SVDpp
NMF
算法与结果可视化
# 可以使用上面提到的各种推荐系统算法
from surprise import SVD,SVDpp,NMF
from surprise import Dataset
from surprise import print_perf
import os
from surprise import Reader, Dataset
from surprise.model_selection import cross_validate
from pandas import DataFrame
import numpy as np
import pandas as pd
##################SVD_noBiased
## 指定文件路径
file_path = os.path.expanduser('./python_data.txt')
## 指定文件格式\n",
reader = Reader(line_format='user item rating timestamp', sep=',')
## 从文件读取数据
data = Dataset.load_from_file(file_path, reader=reader)
# 在数据集上测试一下效果
#perf = evaluate(algo, data, measures=['RMSE', 'MAE'])
# Run 5-fold cross-validation and print results.
perf1 = cross_validate(SVD(n_factors=1,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf2 = cross_validate(SVD(n_factors=3,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf3 = cross_validate(SVD(n_factors=5,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf4 = cross_validate(SVD(n_factors=7,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf5 = cross_validate(SVD(n_factors=9,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf6 = cross_validate(SVD(n_factors=11,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf7 = cross_validate(SVD(n_factors=13,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf8 = cross_validate(SVD(n_factors=15,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf9 = cross_validate(SVD(n_factors=17,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf10= cross_validate(SVD(n_factors=19,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf11= cross_validate(SVD(n_factors=21,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf12= cross_validate(SVD(n_factors=23,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf13= cross_validate(SVD(n_factors=25,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf14= cross_validate(SVD(n_factors=27,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf15= cross_validate(SVD(n_factors=29,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf_result=[]
for i in range(1,16):
perf_result.append('perf'+ str(i))
MAE=[]
for perf in perf_result:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
Factors = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['Factors'])
SVD_noBaised_result = pd.concat([Factors,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
SVD_noBaised_result.to_csv('./result_data/SVD_noBaised_result.csv',header=True,encoding='utf-8')
##################SVD_biased
# Run 5-fold cross-validation and print results.
perf01 = cross_validate(SVD(n_factors=1,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf02 = cross_validate(SVD(n_factors=3,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf03 = cross_validate(SVD(n_factors=5,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf04 = cross_validate(SVD(n_factors=7,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf05 = cross_validate(SVD(n_factors=9,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf06 = cross_validate(SVD(n_factors=11,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf07 = cross_validate(SVD(n_factors=13,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf08 = cross_validate(SVD(n_factors=15,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf09 = cross_validate(SVD(n_factors=17,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf010= cross_validate(SVD(n_factors=19,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf011= cross_validate(SVD(n_factors=21,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf012= cross_validate(SVD(n_factors=23,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf013= cross_validate(SVD(n_factors=25,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf014= cross_validate(SVD(n_factors=27,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf015= cross_validate(SVD(n_factors=29,biased=True),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf_result1=[]
for i in range(1,16):
perf_result1.append('perf0'+ str(i))
MAE=[]
for perf in perf_result1:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result1:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result1:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result1:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
Factors = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['Factors'])
SVD_baised_result = pd.concat([Factors,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
SVD_baised_result.to_csv('./result_data/SVD_baised_result.csv',header=True,encoding='utf-8')
##############SVD++
# Run 5-fold cross-validation and print results.
perf001 = cross_validate(SVDpp(n_factors=1),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf002 = cross_validate(SVDpp(n_factors=3),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf003 = cross_validate(SVDpp(n_factors=5),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf004 = cross_validate(SVDpp(n_factors=7),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf005 = cross_validate(SVDpp(n_factors=9),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf006 = cross_validate(SVDpp(n_factors=11),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf007 = cross_validate(SVDpp(n_factors=13),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf008 = cross_validate(SVDpp(n_factors=15),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf009 = cross_validate(SVDpp(n_factors=17),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0010= cross_validate(SVDpp(n_factors=19),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0011= cross_validate(SVDpp(n_factors=21),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0012= cross_validate(SVDpp(n_factors=23),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0013= cross_validate(SVDpp(n_factors=25),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0014= cross_validate(SVDpp(n_factors=27),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0015= cross_validate(SVDpp(n_factors=29),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf_result2=[]
for i in range(1,16):
perf_result2.append('perf00'+ str(i))
MAE=[]
for perf in perf_result2:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result2:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result2:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result2:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
Factors = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['Factors'])
SVDpp_result = pd.concat([Factors,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
SVDpp_result.to_csv('./result_data/SVDpp_result.csv',header=True,encoding='utf-8')
######## NMF
# Run 5-fold cross-validation and print results.
perf0001 = cross_validate(NMF(n_factors=1,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0002 = cross_validate(NMF(n_factors=3,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0003 = cross_validate(NMF(n_factors=5,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0004 = cross_validate(NMF(n_factors=7,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0005 = cross_validate(NMF(n_factors=9,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0006 = cross_validate(NMF(n_factors=11,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0007 = cross_validate(NMF(n_factors=13,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0008 = cross_validate(NMF(n_factors=15,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf0009 = cross_validate(NMF(n_factors=17,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf00010= cross_validate(NMF(n_factors=19,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf00011= cross_validate(NMF(n_factors=21,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf00012= cross_validate(NMF(n_factors=23,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf00013= cross_validate(NMF(n_factors=25,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf00014= cross_validate(NMF(n_factors=27,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf00015= cross_validate(NMF(n_factors=29,biased=False),data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
perf_result3=[]
for i in range(1,16):
perf_result3.append('perf000'+ str(i))
MAE=[]
for perf in perf_result3:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result3:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result3:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result3:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
Factors = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['Factors'])
NMF_result = pd.concat([Factors,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
NMF_result.to_csv('./result_data/NMF_result.csv',header=True,encoding='utf-8')
#########################################################################################################################
####################################对SVD的可视化
SVD_noBaised_result <- read.csv('SVD_noBaised_result1.csv',encoding = 'utf-8')
SVD_baised_result <- read.csv('SVD_baised_result1.csv',encoding = 'utf-8')
SVDpp_result <- read.csv('SVDpp_result1.csv',encoding = 'utf-8')
NMF_result <- read.csv('NMF_result1.csv',encoding = 'utf-8')
SVD_noBiased_result <- as.data.table(SVD_noBaised_result)
SVD_biased_result <- as.data.table(SVD_baised_result)
SVDpp_result <- as.data.table(SVDpp_result)
NMF_result <- as.data.table(NMF_result)
SVD_noBiased_result <- SVD_noBiased_result[,SVD_class:='SVD_noBiased']
SVD_biased_result <- SVD_biased_result[,SVD_class:='SVD_biased']
SVDpp_result <- SVDpp_result[,SVD_class:='SVD++']
NMF_result <- NMF_result[,SVD_class:='NMF']
merge_SVD_result <- rbind(SVD_noBiased_result,SVD_biased_result,SVDpp_result,NMF_result)
merge_SVD_result <- merge_SVD_result[,-1]
# plot result
colour <- c('#34495e','#3498db','#2ecc71','#f1c40f','#e74c3c','#9b59b6','#1abc9c')
mycol <- define_palette(swatch = colour,gradient = c(lower=colour[1L],upper=colour[2L]))
ggthemr(mycol)
p01 <- ggplot(data= merge_SVD_result, aes(x=Factors, y= MAE,group=SVD_class, shape=SVD_class, color=SVD_class)) +
geom_line()+
geom_point()+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
p02 <- ggplot(data= merge_SVD_result, aes(x=Factors, y= RMSE,group=SVD_class, shape=SVD_class, color=SVD_class)) +
geom_line()+
geom_point()+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
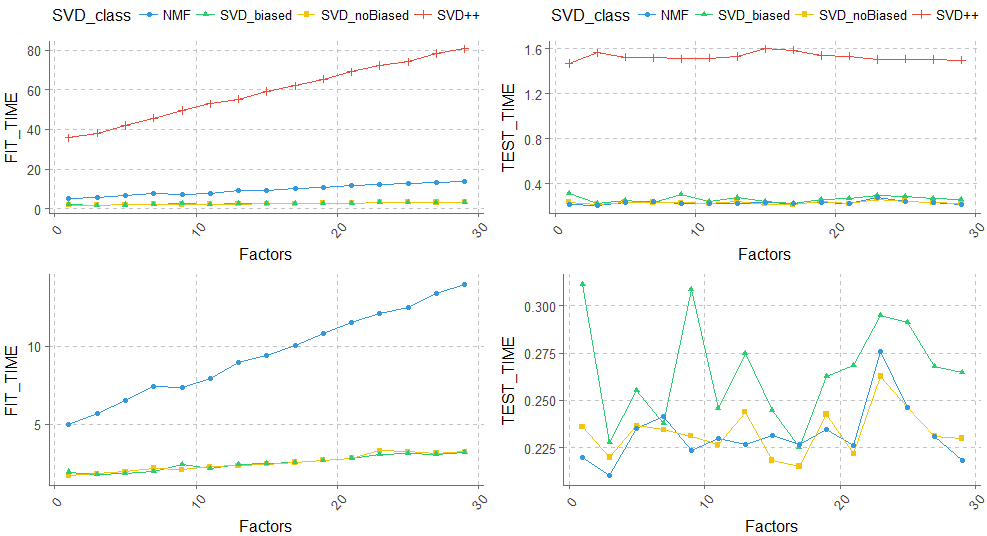
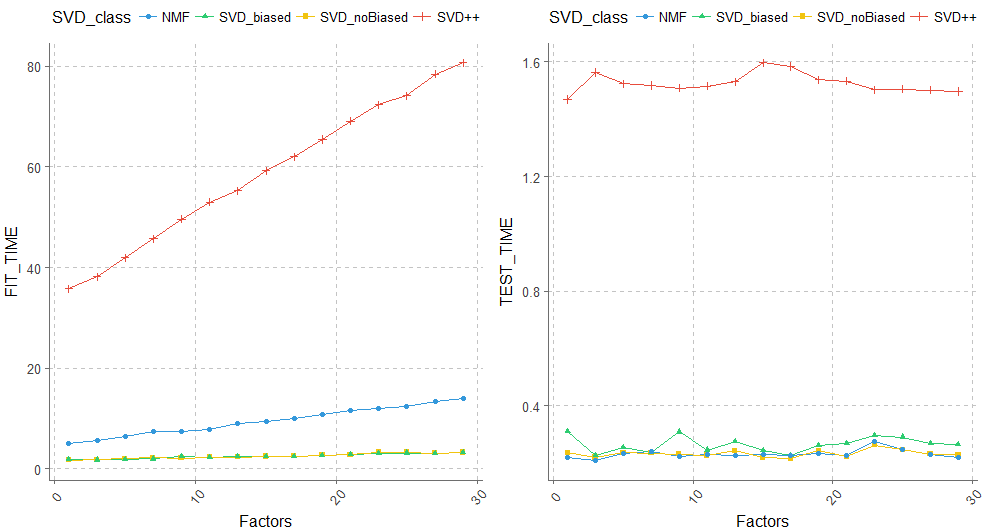
p1 <- ggplot(data= merge_SVD_result, aes(x=Factors, y= FIT_TIME,group=SVD_class, shape=SVD_class, color=SVD_class)) +
geom_line()+
geom_point()+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
p2 <- ggplot(data= merge_SVD_result, aes(x=Factors, y= TEST_TIME,group=SVD_class, shape=SVD_class, color=SVD_class)) +
geom_line()+
geom_point()+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
p3 <- ggplot(data= filter(merge_SVD_result,SVD_class!='SVD++'), aes(x=Factors, y= FIT_TIME,group=SVD_class, shape=SVD_class, color=SVD_class)) +
geom_line()+
geom_point()+
theme(legend.position="none",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
p4 <- ggplot(data= filter(merge_SVD_result,SVD_class!='SVD++'), aes(x=Factors, y= TEST_TIME,group=SVD_class, shape=SVD_class, color=SVD_class)) +
geom_line()+
geom_point()+
theme(legend.position="none",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
x11()
ggplot2.multiplot(p01,p02,cols = 2)
x11()
ggplot2.multiplot(p1,p2,p3,p4,cols = 2)