数据结构基础概念
不论是哪所大学,数据结构和算法这门课都被贯上无趣、犯困、困难的标签,我们从最基础最通俗的语言去说起,保证通俗易懂。
数据结构到底是什么呢?我们先来谈谈什么叫数据。
数据:数据是描述客观事物的数值、字符以及能输入给计算机且能被计算机处理的各种符号集合。
简单的来说,数据就是计算机化的信息。
数据元素:是组成数据的基本单位,在计算机中通常被作为一个整体进行考虑和处理。也被称为记录。
数据项:数据项是数据不可分割的最小单位。一个数据元素可由多个数据项组成。
比如我们的人类世界中,人、狗都能被称为数据元素,作为整体进行考虑。而眼、鼻、手等就是数据项。
数据对象:数据对象是性质相同的数据元素的集合,是数据的子集。
例如学籍表,每个人(数据元素)都有姓名、年龄等数据项,都属于同一个数据对象。
接下来就是我们最重要的数据结构。
数据结构:我们现实世界中,不同的数据元素之间不是独立的,而是存在某些关系,这些关系就是结构。数据结构是指相互之间存在一种或多种特定关系的数据元素集合。
例如图书馆中的每本图书都是数据元素,但是图书馆并不是简单的所有图书都堆积在一起,而是按照某种结构组织图书。
数据之间的结构
我们前面讲,数据结构是相互之间存在一种或多种特定关系的数据元素集合。那么具体是什么特定关系呢?
按照观察角度的不同,分为逻辑结构和物理结构。
逻辑结构
逻辑结构是指元素之间的逻辑关系描述。逻辑结构分为四种。
-
集合结构:结构中的数据除了同属于一个集合的关系外,无任何其他关系。
-
线性结构:结构中的数据元素之间存在着一对一的线性关系。

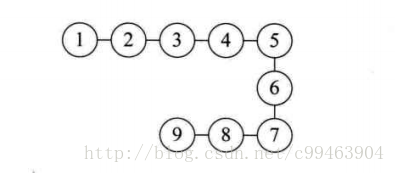
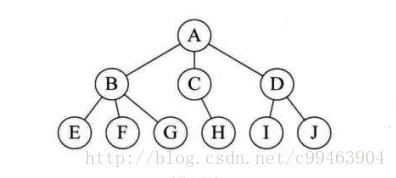
- 树状结构:结构中的数据元素之间存在着一对多的关系。
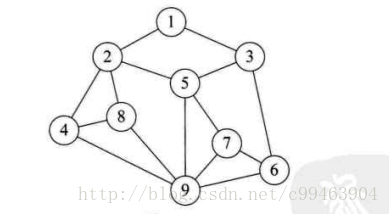
- 图状结构(网状结构):结构中的数据元素之间存在着多对多的任意关系。
物理结构
物理结构:是指逻辑结构在计算机中真正的存储结构。
-
顺序存储结构:把数据元素存放在地址连续的存储单元里。类似于排队,每个人都按顺序站好。我们学习的高级程序语言中的数组就是顺序存储结构,计算机会帮你的数组在内存中找片连续的空间。
-
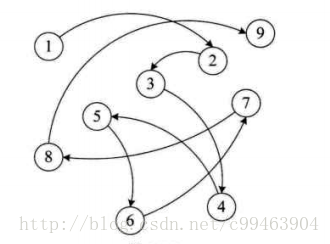
链式存储结构:把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以不连续。只需要前一个元素记住下一个元素的内存地址,这样就像链条链在一起,如下图。
抽象数据类型
数据类型:是一组性质相同的值的集合以及定义在此集合上的一组操作的总称。
例如,java中的数据类型就是已经实现的数据结构的实例。例如int和double,各有各的范围以及该类型允许使用的一组运算等。
抽象数据类型:是指一个数据对象、数据对象中各元素之间的结构关系和一组操作。
简单的说,就是一个模型,我拥有这个关系和这些操作,你想怎么实现是你的事。
例如整数类型,不论是手机、电脑、mp3里面都有整数类型,只要你符合整数类型的特性和该有的加减乘除等操作即可,不管你是怎么实现的。
算法
科学家们曾给出一个著名公式:算法+数据结构=程序。足以见证算法的重要性,否则你就根本没法写程序。算法其实也没有那么神秘,就是我们解决问题的方法。
算法:算法是规则的有限集合,为解决特定问题而规定的一系列操作。
算法的特性
- 有穷性:有限步骤内正常结束,不能无限循环。
- 确定性:每个步骤都必须有确定的含义,无歧义。
- 可行性:原则上能精确进行,操作能通过有限次完成。
- 输入:有0或多个输入。
- 输出:至少有一个输出。
设计算法的要求
-
算法的正确性:对于一切的合法输入都能产生正确的满足要求的结果。
-
可读性:一个好的算法应该便于人们理解和相互交流。
-
健壮性:即使用户输入了非法数据,算法也应该识别并做出处理。
-
高效率和低存储量:即运行速度最快,需要的存储空间最少。
算法的时间性能分析
评价一个算法的性能主要是从算法执行时间与占用存储空间两部分考虑的。
算法的时间性能分析
一个 程序运行时消耗的时间主要是取决于以下因素。
- 采用哪种算法
- 编译产生的代码质量
- 问题的输入规模:即输入量的多少
- 计算机执行指令的速度
第二个由编译器软件来决定,第四个由硬件来决定,抛开这些因素,软件的运行时间由算法的好坏和问题的输入规模决定。
一个算法的执行时间是算法中所有语句执行时间的总和,每条语句的执行时间为该语句的执行次数乘以执行一次的时间。
语句频度是指该语句在一个算法中重复执行的次数。
我们来看一个从1加到100的例子
第一种算法:
int i,sum=0,n=100; //执行一次
for(i=1;i<=n;i++) //执行n+1次
{
sum=sum+i; //执行n次
}
System.out.println(sum); //执行一次
第二种算法:
int sum=0,n=100; //执行一次
sum=(1+n)*n/2; //执行一次
System.out.println(sum); //执行一次
第一种算法执行了2n+3次,第二种算法执行了3次,最后一条语句都一样,如果我们的n很大,这两个算法可以抽象的看作是n和1的区别,算法好坏显而易见。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们再来看一个例子
int i,j,x=0,sum=0,n=100; //执行一次
for(i=1;i<=n;i++){ //执行n+1次
for(j=1;j<=n;j++){ //执行n*(n+1)次
x++; //执行n*n次
sum=sum+x;
}
}
System.out.println(sum); //执行一次
这段代码执行了2n^2+2n+3次,随着这段代码重复被执行的次数增多,随着n值增大,时间效率会爆炸式增长。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
函数的渐进增长
我们来判断一下两个算法哪个更好。A算法做了2n+3次操作,B算法做了3n+1次操作。谁更好呢?
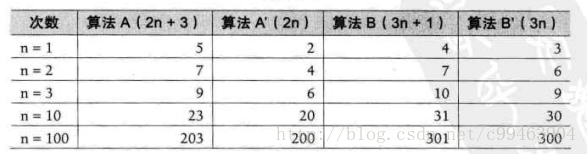
当n=1时,A的效率不如B,n=2时,两者效率相同,当n>2时,A的效率大于B,随着n的增加,A的算法越来越优于B。由此可看,算法A总体上要好于B。
此时我们给出这样的定义:输入规模n在没有限制的情况下,只要超过一个数值N,这个函数就总是大于另一个函数,我们称函数是渐进增长的。
函数的渐进增长:给定两个函数f(n)和g(n), 如果存在一个整数N,使得所有的n>N的时候,f(n)总是比g(n)大,我们说f(n)的渐进增长快于g(n).。
并且我们发现随着n的增大,算法表达式后面的+3、+1并不影响函数的变化,所以我们会在以后忽略这些加法常量。
我们再来看一个例子二,帮我们更好的去理解。
算法C是4n+8,算法D是2n^2+1。
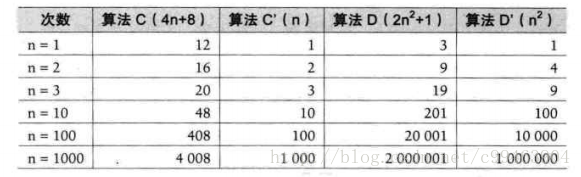
当n<=3时,算法C要差于D,n>3后,算法C的优势越来越大,到后来远远超过算法D。随着n的增大,我们发现忽略常数,对结果完全没任何影响。甚至说去掉与n相乘的常数,也没有影响,C还是远远比D好。也就是说,与最高次项相乘的常数不重要。
OK,OK,我们再来一个例子
算法E是2n^2+3n+1,算法F是2n^3+3n+1
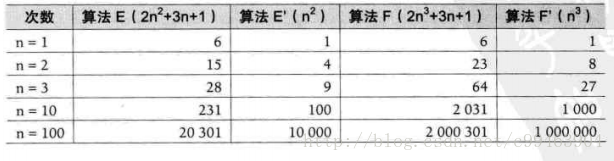
当n=1时,算法E和F的效率相同。当n>1时,算法E的效率就开始比F好。并且随着n的增大,算法E的优势越来越明显。通过观察发现,最高此项的指数大的,随着n的增长,结果也会增长的非常快。
我们再来看最后一次例子,然后得出我们的结论。
算法G是2n^2,算法H是3n+1.
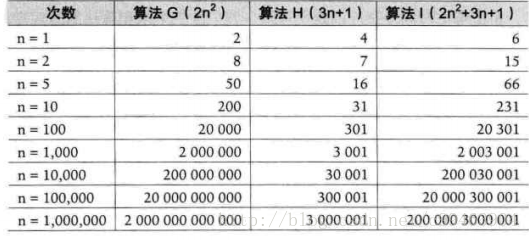
这时现象已经非常明显了,当n越来越大时,算法H就完全无法和算法G相比,最后几乎可以忽略不计,也就是n非常大时,算法H可以看作很趋向于1.
于是,我们可以得出非常重要的一个结论,判断一个算法的效率时,函数中的常数和其他次要项常常可以忽略,而应该关注最高阶项(主项)的阶数。
算法的时间复杂度
定义:在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况并确定T(n)的数量级。算法的时间复杂度,记作T(n)=O(f(n)),它表示随着问题规模n的增大,算法时间的增长率和f(n)的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度。f(n)是问题规模n的某个函数。
在计算渐近时间复杂度时,可以只考虑对算法运行时间贡献大的语句,而忽略那些运算次数少的语句,循环语句中处在循环内层的语句往往运行次数最多,即为对运行时间贡献最大的语句。
这样用大写O来体现时间复杂度的的记法,我们称为大O表示法。
一般情况下,随着n的增大,T(n)增长最慢的算法我们称之为最优算法。
因此我们上面的三个求和算法,按顺序时间复杂度为O(n),O(1),O(n^2),分别称为线性阶,常数阶和平方阶。
-
O(1)常数阶:每条语句的频度都是1,算法的执行时间不随着问题规模n增大而增长,即使有上千条语句,其执行时间也不过是一个比较大的常数。
-
O(n)线性阶:有一个n次循环的循环语句。随着n增长执行时间线性增长。
-
O(n^2)平方阶:循环中嵌套一个循环的情况。
当然还有很多种其他阶,我们后面会慢慢学习。
推导大O阶
我们如何获得一个算法的时间复杂度呢? 即如何推导大O阶呢?我们只需要把前面的内容整理一下即可。
1.用常数1替代所有的加法常数
2.运行次数函数中只保留最高项,如果最高项不是1并且有与之相乘的常数,去掉常数。得到的结果就是大O阶。- 1
- 2
看起来好像很轻松,其实算法的时间复杂度是个蛮复杂的东西,我们来多看几个例子。
前面已经说过了常数阶、线性阶和平方阶。
- 对数阶
int count=1;
while(count<n){
count=count*2;
}
我们会想当然的说,这个一看就是n,因为有一个n的循环。但仔细思考一下,n是因为一次增长一步,n次后执行完了这条语句,所以为O(n).但count和n的关系是这样么?显然不是,count一次增长2倍,也就是说,超过n需要执行多少次语句,即为时间复杂度。通过计算2^x=n,得到x=logn.所以时间复杂度为对数阶O(logn).- 1
- 2
- 3
- 4
- 5
- 6
其实我们也发现了,其实大O的推导并不是很难,关键是数学的基础要好。
我们来总结一下常见的时间复杂度。
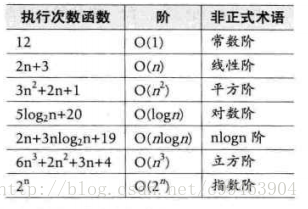
常用的时间复杂度所耗费的时间从小到大是
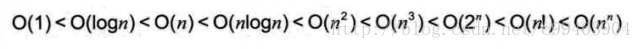
最坏情况和平均情况
当我们需要查找一个数字从长度为n的数组时,最好的情况是第一个数字就是,这时候时间复杂度为O(1),也有可能在最后一次才找到,这时候时间复杂度就是O(n),这是最坏的情况。
最坏情况运行时间是一种保证,那就是运行时间不会再慢了。应用中,这是一种很重要的需求。除非特别指定,我们提到的运行时间都是最坏情况。
平均情况运行时间是所有情况中最有意义的,因为他是期望的运行时间。现实中,平均运行时间很难通过运算得到,一般是运行一定数量的数据后估算出来的。
算法的空间性能分析
算法的空间复杂度通过计算算法所需的存储空间实现,算法空间复杂度的公式是S(n)=O(f(n)),n是问题规模,f(n)是关于n的存储空间的函数。
一般情况下,一个程序在机器上执行时,除了存储本身需要的指令、常量、变量和输入数据以外,还需要一些对数据进行操作的辅助存储空间。其中,对于输入数据所占用的具体存储量取决于问题本身,与算法无关,这样只需要分析该算法在实现时所需要的辅助空间单元个数即可。
算法1:
for(i=0;i<n;i++){
b[i]=a[n-i-1];
}
for(i=0;i<n;i++){
a[i]=b[i]
}
算法2:
for(i=0;i<n/2;i++){
t=a[i];
a[i]=a[n-i-1];
a[n-i-1]=t;
}
算法1的空间复杂度为O(n),需要一个大小为n的辅助数组b。
算法2的空间复杂度为O(1),需要一个变量t,与问题规模无关。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
想使一个算法既占用存储空间少,又运行时间短,在现实中是很难做到的,要节约算法的执行时间往往要牺牲更多空间作为代价,而为了节省空间可能要消耗更多的计算时间,因此,具体的情况要看具体的需求来分析。
时间复杂度是算法中很抽象的一块内容,分析算法的时间复杂度时需要有比较扎实的一些数学基础,但只要一步一步来,多思考,完全可以学会。
数据结构基础概念
不论是哪所大学,数据结构和算法这门课都被贯上无趣、犯困、困难的标签,我们从最基础最通俗的语言去说起,保证通俗易懂。
数据结构到底是什么呢?我们先来谈谈什么叫数据。
数据:数据是描述客观事物的数值、字符以及能输入给计算机且能被计算机处理的各种符号集合。
简单的来说,数据就是计算机化的信息。
数据元素:是组成数据的基本单位,在计算机中通常被作为一个整体进行考虑和处理。也被称为记录。
数据项:数据项是数据不可分割的最小单位。一个数据元素可由多个数据项组成。
比如我们的人类世界中,人、狗都能被称为数据元素,作为整体进行考虑。而眼、鼻、手等就是数据项。
数据对象:数据对象是性质相同的数据元素的集合,是数据的子集。
例如学籍表,每个人(数据元素)都有姓名、年龄等数据项,都属于同一个数据对象。
接下来就是我们最重要的数据结构。
数据结构:我们现实世界中,不同的数据元素之间不是独立的,而是存在某些关系,这些关系就是结构。数据结构是指相互之间存在一种或多种特定关系的数据元素集合。
例如图书馆中的每本图书都是数据元素,但是图书馆并不是简单的所有图书都堆积在一起,而是按照某种结构组织图书。
数据之间的结构
我们前面讲,数据结构是相互之间存在一种或多种特定关系的数据元素集合。那么具体是什么特定关系呢?
按照观察角度的不同,分为逻辑结构和物理结构。
逻辑结构
逻辑结构是指元素之间的逻辑关系描述。逻辑结构分为四种。
-
集合结构:结构中的数据除了同属于一个集合的关系外,无任何其他关系。
-
线性结构:结构中的数据元素之间存在着一对一的线性关系。
- 树状结构:结构中的数据元素之间存在着一对多的关系。
- 图状结构(网状结构):结构中的数据元素之间存在着多对多的任意关系。
物理结构
物理结构:是指逻辑结构在计算机中真正的存储结构。
-
顺序存储结构:把数据元素存放在地址连续的存储单元里。类似于排队,每个人都按顺序站好。我们学习的高级程序语言中的数组就是顺序存储结构,计算机会帮你的数组在内存中找片连续的空间。
-
链式存储结构:把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以不连续。只需要前一个元素记住下一个元素的内存地址,这样就像链条链在一起,如下图。
抽象数据类型
数据类型:是一组性质相同的值的集合以及定义在此集合上的一组操作的总称。
例如,java中的数据类型就是已经实现的数据结构的实例。例如int和double,各有各的范围以及该类型允许使用的一组运算等。
抽象数据类型:是指一个数据对象、数据对象中各元素之间的结构关系和一组操作。
简单的说,就是一个模型,我拥有这个关系和这些操作,你想怎么实现是你的事。
例如整数类型,不论是手机、电脑、mp3里面都有整数类型,只要你符合整数类型的特性和该有的加减乘除等操作即可,不管你是怎么实现的。
算法
科学家们曾给出一个著名公式:算法+数据结构=程序。足以见证算法的重要性,否则你就根本没法写程序。算法其实也没有那么神秘,就是我们解决问题的方法。
算法:算法是规则的有限集合,为解决特定问题而规定的一系列操作。
算法的特性
- 有穷性:有限步骤内正常结束,不能无限循环。
- 确定性:每个步骤都必须有确定的含义,无歧义。
- 可行性:原则上能精确进行,操作能通过有限次完成。
- 输入:有0或多个输入。
- 输出:至少有一个输出。
设计算法的要求
-
算法的正确性:对于一切的合法输入都能产生正确的满足要求的结果。
-
可读性:一个好的算法应该便于人们理解和相互交流。
-
健壮性:即使用户输入了非法数据,算法也应该识别并做出处理。
-
高效率和低存储量:即运行速度最快,需要的存储空间最少。
算法的时间性能分析
评价一个算法的性能主要是从算法执行时间与占用存储空间两部分考虑的。
算法的时间性能分析
一个 程序运行时消耗的时间主要是取决于以下因素。
- 采用哪种算法
- 编译产生的代码质量
- 问题的输入规模:即输入量的多少
- 计算机执行指令的速度
第二个由编译器软件来决定,第四个由硬件来决定,抛开这些因素,软件的运行时间由算法的好坏和问题的输入规模决定。
一个算法的执行时间是算法中所有语句执行时间的总和,每条语句的执行时间为该语句的执行次数乘以执行一次的时间。
语句频度是指该语句在一个算法中重复执行的次数。
我们来看一个从1加到100的例子
第一种算法:
int i,sum=0,n=100; //执行一次
for(i=1;i<=n;i++) //执行n+1次
{
sum=sum+i; //执行n次
}
System.out.println(sum); //执行一次
第二种算法:
int sum=0,n=100; //执行一次
sum=(1+n)*n/2; //执行一次
System.out.println(sum); //执行一次
第一种算法执行了2n+3次,第二种算法执行了3次,最后一条语句都一样,如果我们的n很大,这两个算法可以抽象的看作是n和1的区别,算法好坏显而易见。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们再来看一个例子
int i,j,x=0,sum=0,n=100; //执行一次
for(i=1;i<=n;i++){ //执行n+1次
for(j=1;j<=n;j++){ //执行n*(n+1)次
x++; //执行n*n次
sum=sum+x;
}
}
System.out.println(sum); //执行一次
这段代码执行了2n^2+2n+3次,随着这段代码重复被执行的次数增多,随着n值增大,时间效率会爆炸式增长。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
函数的渐进增长
我们来判断一下两个算法哪个更好。A算法做了2n+3次操作,B算法做了3n+1次操作。谁更好呢?
当n=1时,A的效率不如B,n=2时,两者效率相同,当n>2时,A的效率大于B,随着n的增加,A的算法越来越优于B。由此可看,算法A总体上要好于B。
此时我们给出这样的定义:输入规模n在没有限制的情况下,只要超过一个数值N,这个函数就总是大于另一个函数,我们称函数是渐进增长的。
函数的渐进增长:给定两个函数f(n)和g(n), 如果存在一个整数N,使得所有的n>N的时候,f(n)总是比g(n)大,我们说f(n)的渐进增长快于g(n).。
并且我们发现随着n的增大,算法表达式后面的+3、+1并不影响函数的变化,所以我们会在以后忽略这些加法常量。
我们再来看一个例子二,帮我们更好的去理解。
算法C是4n+8,算法D是2n^2+1。
当n<=3时,算法C要差于D,n>3后,算法C的优势越来越大,到后来远远超过算法D。随着n的增大,我们发现忽略常数,对结果完全没任何影响。甚至说去掉与n相乘的常数,也没有影响,C还是远远比D好。也就是说,与最高次项相乘的常数不重要。
OK,OK,我们再来一个例子
算法E是2n^2+3n+1,算法F是2n^3+3n+1
当n=1时,算法E和F的效率相同。当n>1时,算法E的效率就开始比F好。并且随着n的增大,算法E的优势越来越明显。通过观察发现,最高此项的指数大的,随着n的增长,结果也会增长的非常快。
我们再来看最后一次例子,然后得出我们的结论。
算法G是2n^2,算法H是3n+1.
这时现象已经非常明显了,当n越来越大时,算法H就完全无法和算法G相比,最后几乎可以忽略不计,也就是n非常大时,算法H可以看作很趋向于1.
于是,我们可以得出非常重要的一个结论,判断一个算法的效率时,函数中的常数和其他次要项常常可以忽略,而应该关注最高阶项(主项)的阶数。
算法的时间复杂度
定义:在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况并确定T(n)的数量级。算法的时间复杂度,记作T(n)=O(f(n)),它表示随着问题规模n的增大,算法时间的增长率和f(n)的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度。f(n)是问题规模n的某个函数。
在计算渐近时间复杂度时,可以只考虑对算法运行时间贡献大的语句,而忽略那些运算次数少的语句,循环语句中处在循环内层的语句往往运行次数最多,即为对运行时间贡献最大的语句。
这样用大写O来体现时间复杂度的的记法,我们称为大O表示法。
一般情况下,随着n的增大,T(n)增长最慢的算法我们称之为最优算法。
因此我们上面的三个求和算法,按顺序时间复杂度为O(n),O(1),O(n^2),分别称为线性阶,常数阶和平方阶。
-
O(1)常数阶:每条语句的频度都是1,算法的执行时间不随着问题规模n增大而增长,即使有上千条语句,其执行时间也不过是一个比较大的常数。
-
O(n)线性阶:有一个n次循环的循环语句。随着n增长执行时间线性增长。
-
O(n^2)平方阶:循环中嵌套一个循环的情况。
当然还有很多种其他阶,我们后面会慢慢学习。
推导大O阶
我们如何获得一个算法的时间复杂度呢? 即如何推导大O阶呢?我们只需要把前面的内容整理一下即可。
1.用常数1替代所有的加法常数
2.运行次数函数中只保留最高项,如果最高项不是1并且有与之相乘的常数,去掉常数。得到的结果就是大O阶。- 1
- 2
看起来好像很轻松,其实算法的时间复杂度是个蛮复杂的东西,我们来多看几个例子。
前面已经说过了常数阶、线性阶和平方阶。
- 对数阶
int count=1;
while(count<n){
count=count*2;
}
我们会想当然的说,这个一看就是n,因为有一个n的循环。但仔细思考一下,n是因为一次增长一步,n次后执行完了这条语句,所以为O(n).但count和n的关系是这样么?显然不是,count一次增长2倍,也就是说,超过n需要执行多少次语句,即为时间复杂度。通过计算2^x=n,得到x=logn.所以时间复杂度为对数阶O(logn).- 1
- 2
- 3
- 4
- 5
- 6
其实我们也发现了,其实大O的推导并不是很难,关键是数学的基础要好。
我们来总结一下常见的时间复杂度。
常用的时间复杂度所耗费的时间从小到大是
最坏情况和平均情况
当我们需要查找一个数字从长度为n的数组时,最好的情况是第一个数字就是,这时候时间复杂度为O(1),也有可能在最后一次才找到,这时候时间复杂度就是O(n),这是最坏的情况。
最坏情况运行时间是一种保证,那就是运行时间不会再慢了。应用中,这是一种很重要的需求。除非特别指定,我们提到的运行时间都是最坏情况。
平均情况运行时间是所有情况中最有意义的,因为他是期望的运行时间。现实中,平均运行时间很难通过运算得到,一般是运行一定数量的数据后估算出来的。
算法的空间性能分析
算法的空间复杂度通过计算算法所需的存储空间实现,算法空间复杂度的公式是S(n)=O(f(n)),n是问题规模,f(n)是关于n的存储空间的函数。
一般情况下,一个程序在机器上执行时,除了存储本身需要的指令、常量、变量和输入数据以外,还需要一些对数据进行操作的辅助存储空间。其中,对于输入数据所占用的具体存储量取决于问题本身,与算法无关,这样只需要分析该算法在实现时所需要的辅助空间单元个数即可。
算法1:
for(i=0;i<n;i++){
b[i]=a[n-i-1];
}
for(i=0;i<n;i++){
a[i]=b[i]
}
算法2:
for(i=0;i<n/2;i++){
t=a[i];
a[i]=a[n-i-1];
a[n-i-1]=t;
}
算法1的空间复杂度为O(n),需要一个大小为n的辅助数组b。
算法2的空间复杂度为O(1),需要一个变量t,与问题规模无关。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
想使一个算法既占用存储空间少,又运行时间短,在现实中是很难做到的,要节约算法的执行时间往往要牺牲更多空间作为代价,而为了节省空间可能要消耗更多的计算时间,因此,具体的情况要看具体的需求来分析。
时间复杂度是算法中很抽象的一块内容,分析算法的时间复杂度时需要有比较扎实的一些数学基础,但只要一步一步来,多思考,完全可以学会。