一. 什么是数据库
简单来说,就是数据存储的仓库,本质上其实是一个文件系统,文件是他的组成部分,主要功能就是通过SQL对文件的CRUD操作.
常用的数据库:MYSQL,ORACLE, SQL Server
二. 数据库设计的四个阶段:以ERP项目为例
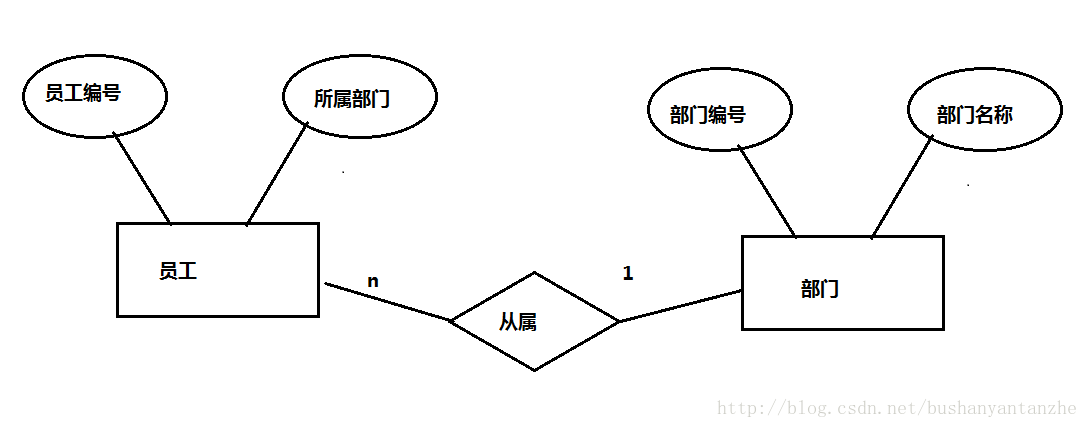
- 需求分析:分析需求,将项目中所需要的事务抽取成对象.比如:①员工:员工编号,姓名,年龄,所属部门…②部门:部门编号,部门名称,成立时间..
- 逻辑设计阶段:用E-R图画出对象模型,以及对象之间的关系
- 物理设计阶段: 为所设计的数据库选择合适的存储结构和存取路径;实际上就是将前面几步分析好的对象转化成实例化的数据库和表.范式就是规范,就是关系型数据库设计表时遵循的三个规范.要满足第二范式,必须先满足第一范式,要满足第三范式,必须先满足第二范式
- 第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。列数据的不可分割.
- 第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识.(主键)
- 第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。(外键)
反三范式:有时候为了效率,可以设置重复或者可推导出的字段.比如:订单(总价),订单项(单价)
CREATE TABLE `tb_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`money`double DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;- 运维优化阶段:代码在进行压力测试时,如果有问题,再对数据库进行优化
三. 悲观锁和乐观锁
悲观锁: 对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度(悲观),因此,在整个数据处理过程中,将数据处于锁定状态。说简单点,就是数据库将能够对数据造成安全问题的所有条件全部阻挡在门外.
读锁/共享锁:(准备一把大家都有钥匙的锁)大家都能查询数据库,但是只有持有锁的人才能修改数据.
START TRANSACTION
SELECT NAME FROM tb_user LOCK IN SHARE MODE
UPDATE tb_user SET NAME="张三丰"
COMMIT;写锁/排他锁:保证只有一个人能访问,安全.
START TRANSACTION
SELECT NAME FROM tb_user FOR UPDATE
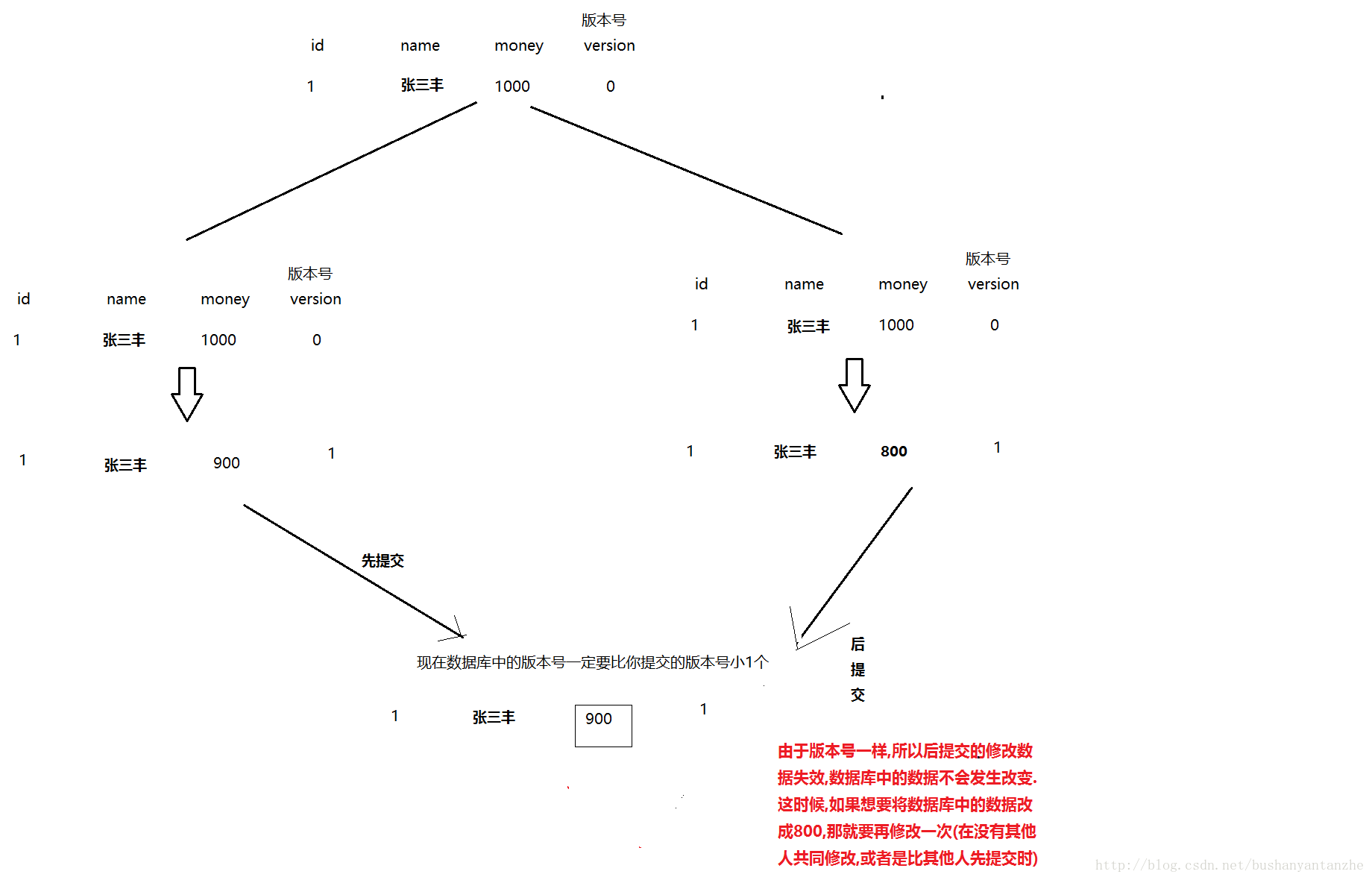
COMMIT;乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。简单来说,就像是老美对危险武器不管不问,只有发生事件时才会去过问一样.
四. 事务特性ACID:
1.原子性(Atomicity):表示事务内不可分割,要么都成功,要么都失败
2.一致性(Consistency):要么都成功,要么都失败.失败了,要对前面的操作进行回滚
3.隔离性(Isolation):一个事务开启了,不能受其它事务的影响
4.持久性(Durability):持续性,表示事务开始了,就不能终止.事务提交后,将数据序列化到数据库
五. 存储引擎
Myisam:不支持事务,表锁。适合于更改少,查询多的表,比如说商品分类表 Innodb:支持事务,行锁,是mysql 5.5之后官方推荐及默认,适合经常更改数据的表,比如说订单表
| 功 能 | MYISAM | Memory | InnoDB | Archive |
| 存储限制 | 256TB | RAM | 64TB | None |
| 支持事物 | No | No | Yes | No |
| 支持全文索引 | Yes | No | No | No |
| 支持数索引 | Yes | Yes | Yes | No |
| 支持哈希索引 | No | Yes | No | No |
| 支持数据缓存 | No | N/A | Yes | No |
| 支持外键 | No | No | Yes | No |
六. 索引
关于索引的东西太多,我在这里不做详谈,只是简单说一下
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
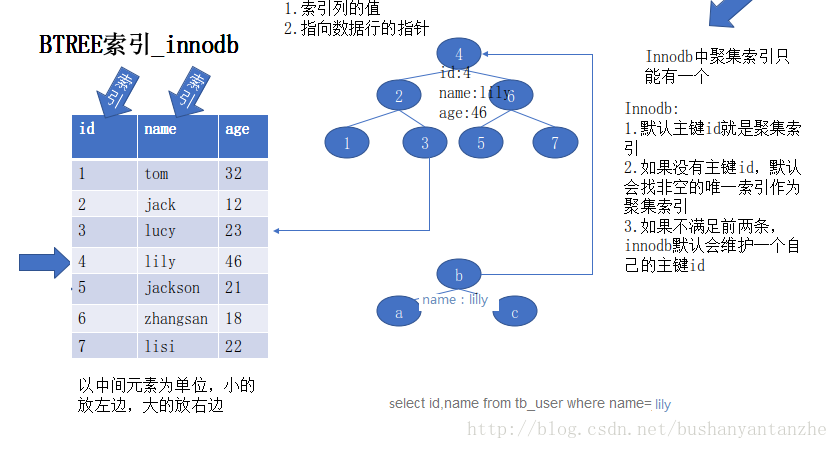
• 非聚集索引:data与index是分开的,比如字典中的目录与内容。Myisam下的B+Tree就是非聚集索引。
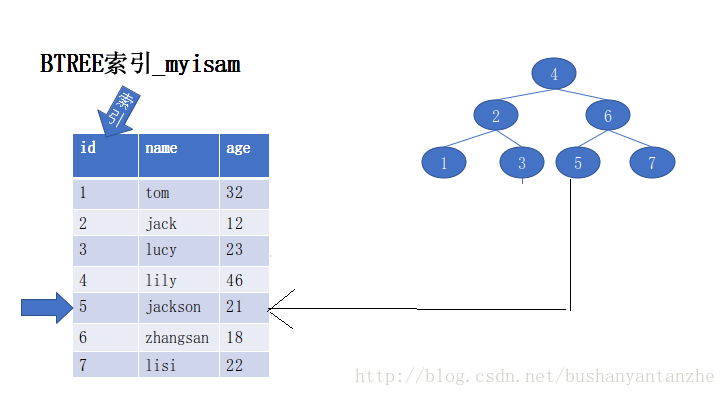
• 聚集索引:data与index是一起的,比如字典中的页码。InnoDB下的B+Tree就是聚集索引。
索引失效简单例子:
• -- index(age)
• select * from user order by age;索引生效
-- 最左匹配
• --index(name,age)
• select * from user order by age;索引失效
• select * from user where age = 18 and name = ‘Lily’;索引失效
•
• -- index(age,name)
• select * from user where age > 18 and name = ‘Lily’;索引生效一半七. 数据库优化
大家可以自行去查看一下相应的API文档