几经波折,终于把基于opencv下的svm数字识别做出来了…
需要代码的请加QQ490346270详聊
这里感谢两篇很重要的博客..
http://blog.csdn.net/ni_guang2010/article/details/53069579
http://blog.csdn.net/qq_28306361/article/details/53705227#reply
因为本人是个小白,看到网上的数字识别基本上都是mnist的,
自己看不太懂,所以想根据自己的思路写一下,看看能否识别数字出来..
这里记录一下心得.
1、基础
这个在我的前面两篇svm学习中已经讲得蛮清楚的了,
识别数字也是基本上按照这个思路去搭建框架就好了。
http://blog.csdn.net/csdn_dzh/article/details/78984222
http://blog.csdn.net/csdn_dzh/article/details/78985736
2、训练集准备
这里我有一组训练集,每个数字包含有96个样本。
原来的图片尺寸大小为560×560,于是我把它们resize 之后成为28×28的
因为如果不resize的话会出现栈空间不够或者影响训练速度的情况。
resize的具体代码见下面的网址
http://blog.csdn.net/csdn_dzh/article/details/79012644
我将这些图片统一resize到了一个文件夹mynum下面,
也就是说,这个文件夹下面一共会有9×96张尺寸大小为28×28的数字样本图片
这些图片会作为我的训练样本和测试样本。
3、实践
3.1首先定义基本的参数
#define numbers 9 //9个数字
#define datas 96 //每个数字有96个样本
#define imgsize 28 //样本的尺寸大小为28×283.2定义存放数据和标签的数组
float trainingData[datas * numbers][imgsize * imgsize] = { 0 };//用于存放训练数据的二维数组
int labels[datas * numbers] = { 0 };//用于存放标签数据的向量
float testData[imgsize * imgsize] = { 0 };//用于存放测试数据的行向量这里注意,这个地方用于存放训练数据和测试数据的数组一定要是float类型的,我调试得时候因为之前设置为int类型然后导致只有1,5,7几个数字识别的准确率在70以上,其它数字识别的准确率低得可怕,是因为什么呢。
因为在灰度化以后,每个像素值是浮点数,如果我把存放二值数组的类型设为整型.相当于我把很多数据给抹去了,只有像素为255的那些位置为1,其他都成0了,如果数字本身像素比较低的话,那几乎没法识别。所以这是个大坑。。
3.3读入数据集
//【1】读取图片,将其像素值放到Data中
int row = 0;
for (int number = 1; number <= numbers; number++) //一共1-9个数字numbers=9;
{
for (int count = 1; count <= datas; count++) //每个数字的样本数量datas=96;
{
stringstream ss; // 读取测试图片
ss << "C:\\Users\\Administrator\\Desktop\\SVM学习\\mynum\\" << number << "_" << count << ".png";
Mat srcImage = imread(ss.str(), 0);
//cvtColor(srcImage, srcImage, CV_BGR2GRAY);
if (!srcImage.data)
{
cout << "读取失败..请重试..." << endl;
exit(0);
}
else
{
//cout << ss.str() << "\t读取成功!" << endl;
get_trainingData(srcImage, row);//获取训练数据
labels[row] = number;//贴标签
row++;
}
}
}这里,我存放训练样本的形式是在mynum文件夹下存放着9*96张样本,
文件名为 数字i_样本号n
所以这里的路径为”C:\Users\Administrator\Desktop\SVM学习\mynum\” << number << “_” << count << “.png”;
由于没有数字0的样本,这里我用一个row来控制trainingData的行号和labels的行号统一,用number来给数字的每一个样本贴上相同的标签。
3.4数据处理
void get_trainingData(Mat &srcImage, int row)
{
int k = 0;
for (int j = 0; j < srcImage.rows; j++)
{
for (int i = 0; i < srcImage.cols; i++)
{
trainingData[row][k] = srcImage.at<uchar>(j, i) / 255 + 0.5; //四舍五入
k++;
}
}
}这里将样本的像素值做这样的处理,放入trainingData数组中。
3.5初始化训练参数,开始训练
//【3】训练参数初始化
Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::C_SVC);// SVM类型为C_SVM,可以进行2类以上的分类
svm->setKernel(cv::ml::SVM::LINEAR);// 核函数径向基函数,线性的不可分没法用
svm->setC(0.01); //松弛因子的惩罚系数C
svm->setGamma(3);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER, 100, 1e-6));
//【4】开始训练
svm->train(trainingDataMat, cv::ml::SampleTypes::ROW_SAMPLE, labelsMat);3.6读入测试数据,得到识别正确率
根据上面的思路,将数据集全部读入作为测试数据,
与样本集一样做相同的处理,每一张图片的像素值化为一个行向量作为测试数据
Mat testMat(1, imgsize * imgsize, CV_32FC1, testData);
int response = (int)svm->predict(testMat);
//cout << "预测结果为:" << response;
if (response == truth_num)
{
sum++;
}这里得到每一张的预测结果存入response这个变量中
判断response是否等于读入的数字,如果等于,则累计相等的次数
最后用这个sum/96即可得到正确率了。
怎么样,是不是很简单。
总结
这里总结一下思路。
1把训练样本(每个数字的每个实例)转化为行向量
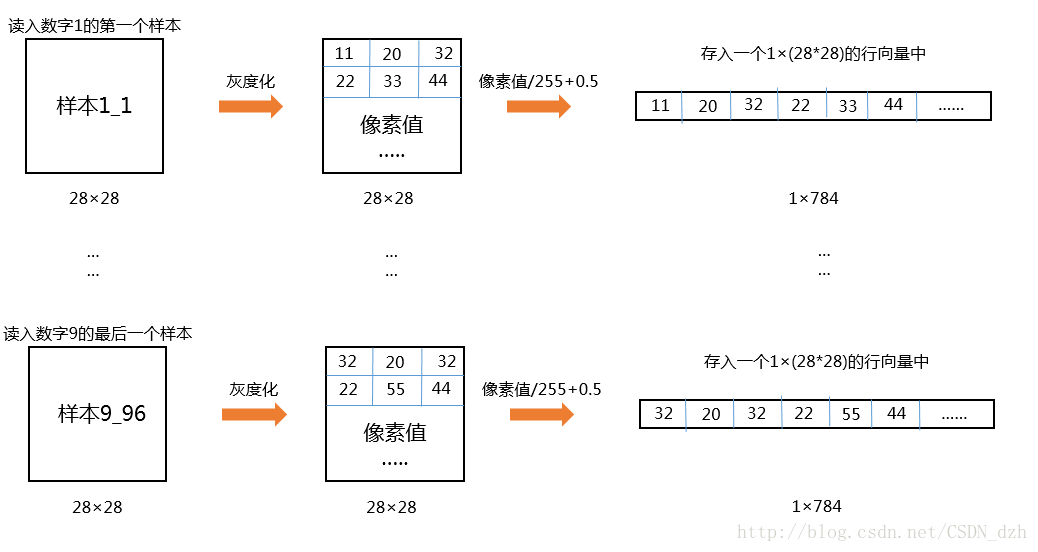
2将这些向量里的像素内容合成为一个超大矩阵作为训练数据
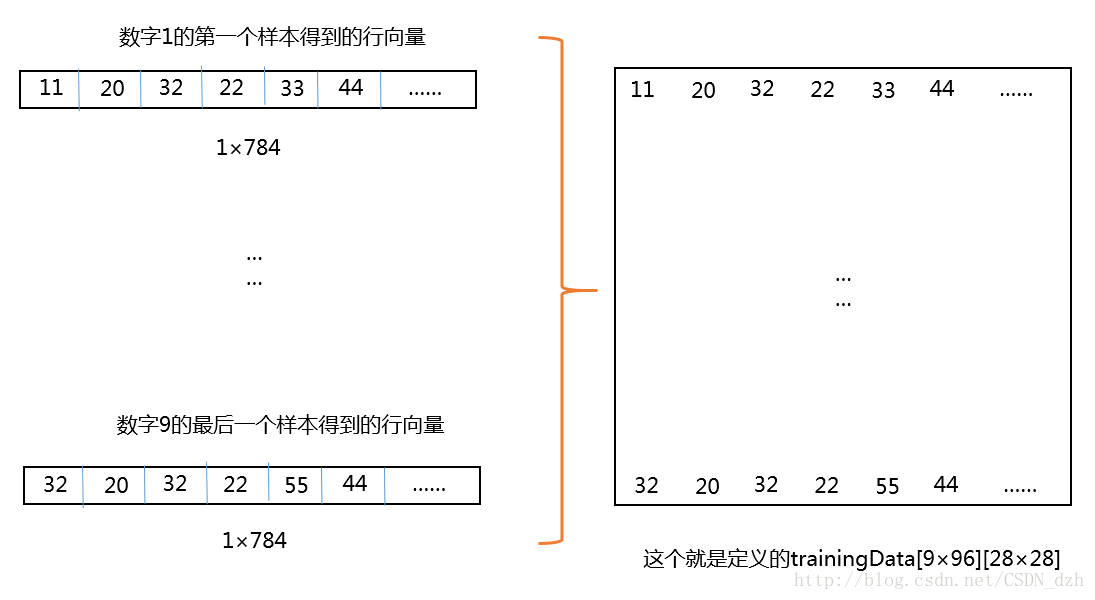
将这个数组里的内容转化为Mat类对象trainingDataMat
Mat trainingDataMat(datas * numbers, imgsize * imgsize, CV_32FC1, trainingData);3给每个向量贴上标签
对应数字1的训练数据生成的行向量就贴上1
对应数字2的训练数据生成的行向量就贴上2
。。。。。。。。。。。。。。。。。。。。
。。。。9。。。。。。。。。。。。。。9
将这个labels数组中的内容转化为Mat类对象labelsMat
Mat labelsMat(datas * numbers, 1, CV_32SC1, labels);4SVM训练
这里引用http://blog.csdn.net/ni_guang2010/article/details/53069579的描述
SVM既可以用来处理分类问题,也可以用来作回归任务。SVM不修改的话,只能用来进行处理二分类问题。
手写数字字体识别,显然是个多类别分类问题。对于多分类问题,解决的基本思路是“拆分法”,即将多个二分类问题拆分为若干个十分类任务进行求解。具体来讲,先对问题进行拆分,然后为拆出的每个十分类任务训练一个分类器,在测试时,对这些二分类器的结果进行集成以获得最终的多分类结果。拆分的策略主要有以下几种:
OvO(one-vs-one)
这种解决方法的思路是:对于有N个类别的分类任任务,将这N个类别两两配对,从而产生N(N-1)/2个二分类任务。在测试阶段,新样本同时提交给所有分类器,这样可以得到N(N-1)/2个分类结果,最终的结果可以通过投票产生:即把预测的最多的类别作为最终的分类结果。
OvR(one-vs-rest)
这种解决方法的思路是:每次将一个类的样例作为正例,所有其他类的样例作为负例来训练N个分类器。在测试时,若仅有一个分类器预测为正类,则对应的类别标记为最终分类结果。
两种策略对比:
明显看出,OvR只需要训练N个分类器,而OvO需要训练N(N-1)/2个分类器,因此OvO的存储开销和测试时间开销通常比OvR更大。但在训练时,OvR的每个分类器均使用全部训练样例,而OvO的每个分类器仅用到两个类的样例。因此,在类别很多的时候,OvO的训练时间开销通常比OvR更小。至于性能,取决于具体的数据分布,多数情况下两者差不多。
而opencv的SVM函数中,只要通过svm->setType(cv::ml::SVM::C_SVC);
设置SVM类型为C_SVM,就可以进行2类以上的分类了
5得到训练模型后,读入测试数据进行预测
其原理与训练样本是一样的,只要将每个数字的每个样本变成一个行向量即可,如下图
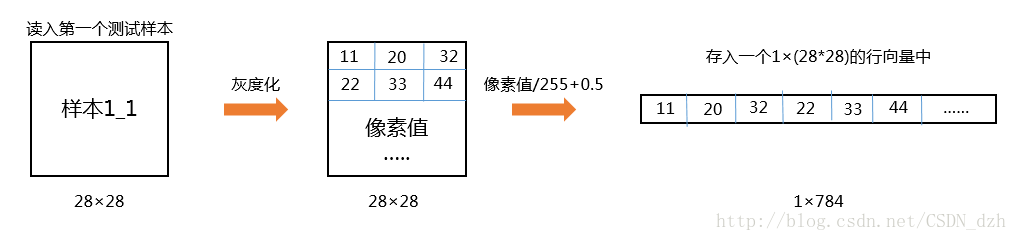
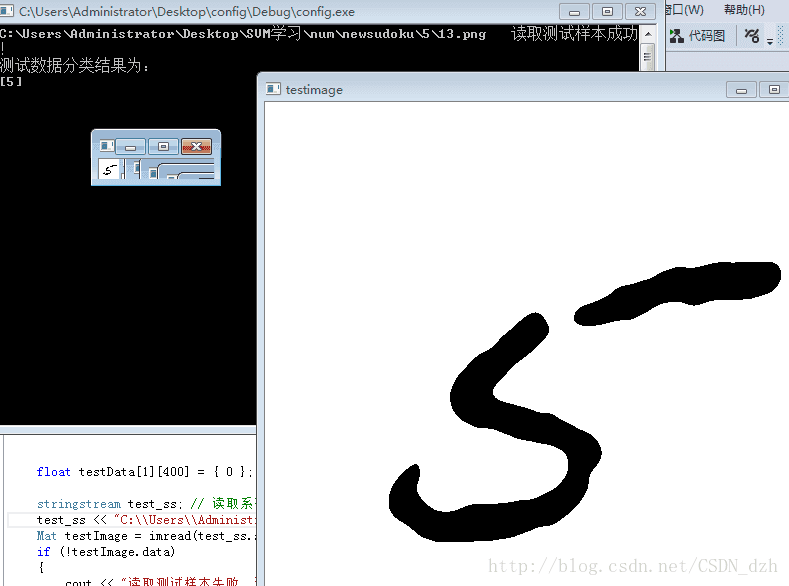
然后就看正确率就行了,结果如下,效果还不错

需要代码的请加QQ490346270详聊