一、目的
想要实现的功能:帮助我们在泵中扫描燃油,并在应用程序中输入燃油信息。
所需技术:①python程序对于拍摄的汽油泵的图像,尝试从中读取数字。——opencv实现。②先使用python对其进行原型设计,然后将代码转换成C++以在ios应用程序上运行。
但是我不会部署在移动端,对第二个不做研究。
目标:需要考虑两个问题:
- 可以从图像中分离出数字吗?——用opencv图像阈值法来查找数字,进行裁剪轮廓
- 可以确定图像代表哪个数字吗?——KNN进行分类训练。
二、图像中分离出数字
思路:利用简单的图像阈值法来查找数字。
图像阈值法:将图像转换为灰度,然后说灰度值小于某个常数的任何像素,则该像素为一个值,否则为另一个。最后,得到的二进制图像只有两种颜色,在大多数情况下只是黑白图像。一幅图通常包含目标物体还有各种背景和噪声,想要得到目标物体,就要设置一个阈值,用阈值将图像的像素分割成两部分。
但是阈值的值如何确定呢?——五、自动化可以解决阈值的选择
这个概念在OCR应用中非常有效,但是主要问题是决定对该阈值使用什么。我们可以选择一些常量,也可以使用OpenCV选择其他一些选项。我们可以使用自适应阈值而不是使用常数,这将使用图像的较小部分并确定要使用的不同阈值。这在具有不同照明情况的应用中特别有用,特别是在扫描气泵中。
设置好阈值后,使用opencv中的findcontours方法查找图像中连接了白色像素部分的区域。绘制轮廓后,便可以裁剪出这些区域并确定它们是否可能是数字以及是什么数字。
2.1 图像处理流程
这是我在测试图像处理中使用的原始图像。它有一些眩光点,但是图像相当干净。让我们逐步完成获取此源图像的过程,并尝试将其分解为单个数字。
在代码中主要对应于playground.py函数,这个相当于完整的代码,会输出最后的预测结果,其中图像分割部分主要调用的是frameProcessor.py文件中的函数。


原始图片
2.1.1 图像准备
在开始图像处理流程之前,我们决定先调整一些图像属性,然后再继续。这有点试验和错误,但注意到,当我们调整图像的曝光度时,可以获得更好的结果。下面是使用Python调整后的图像,相当于曝光(阿尔法)的图像cv::Mat::convertTo这是刚刚在图像点乘法操作cv2.multiply(some_img, np.array([some_alpha]),

调整曝光
2.1.2 灰阶
将图像转换为灰度。

转换为灰度
2.1.3 模糊
模糊图像以减少噪点。我们尝试了许多不同的模糊选项,但仅用轻微的模糊就找到了最佳结果。

稍微模糊
2.1.4 阈值化
图像转换为黑白图像
在下图中,使用cv2.adaptiveThreshold带有cv2.ADAPTIVE_THRES_GAUSSIAN_C选项的方法。此方法采用两个参数,块大小和要调整的常数。确定这两者需要一些试验和错误,更多有关优化部分的内容。
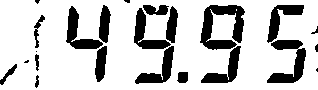
阈值为黑/白
2.1.5 填补空白
由于大多数燃油泵都使用某种7段LCD显示屏,因此数字中存在一些细微的间隙,无法使用轮廓绘制方法,因此我们需要使这些段看起来相连。在这种情况下,我们将转到erode(黑多白少)图像来弥补这些差距。由于大家可能希望使用,所以这似乎向后看,dilate但是这些方法通常适用于图像的白色部分。在我们的案例中,我们正在“侵蚀erode”白色背景以使数字看起来更大。
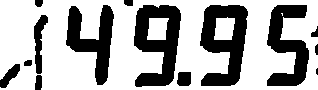
侵蚀出来的数字
2.1.6 反转图像
在尝试在图像中查找轮廓之前,我们需要反转颜色,因为该findContours方法将找到白色的连接部分,而当前的数字是黑色。

颜色反转
2.1.7 在图像上找到轮廓
下图显示了我们的原始图像,该图像在上图的每个轮廓上都有包围框。大家可以看到它找到了数字,但也找到了一堆不是数字的东西,因此我们需要将它们过滤掉。

红色框显示所有找到的轮廓
轮廓过滤
- 现在我们有了许多轮廓,我们需要找出我们关心的轮廓。浏览了一堆气泵的显示和场景后,使用一套适用于轮廓的快速规则。
- 收集所有我们将分类为潜在小数的正方形轮廓。
- 扔掉任何不是正方形或高矩形的东西。
- 使轮廓与某些长宽比匹配。LCD显示屏中的十个数字中有九个数字的长宽比类似于下面的蓝色框高光之一。该规则的例外是数字“ 1”,其长宽比略有不同。通过使用一些样本轮廓,我将0–9!1方面确定为0.6,将1方面确定为0.3。它将使用这些比率和+/-缓冲区来确定轮廓是否是我们想要的东西,并收集这些轮廓。
- 对潜在数字应用一组附加规则,在这里我们将确定轮廓边界是否偏离所有其他潜在数字的平均高度或垂直位置。由于数字的大小应相同,并且在相同的Y上对齐,因此我们可以丢弃它认为是数字的任何轮廓,但不能像其他轮廓那样将其对齐和调整大小。

蓝色矩形显示我们的数字/十进制,红色被忽略
2.1.8 查找小数点
在图像中查找小数点是要解决的另一个问题。由于它很小,有时会连接到它旁边的手指,因此使用我们在手指上使用的方法来确定它似乎有问题。当我们过滤轮廓时,我们收集了可能是十进制的正方形轮廓。从上一步获得经过验证的数字轮廓之后,我们将找到数字的最左x位置和最右x位置,以确定我们期望的小数位数。然后,我们将遍历那些潜在的小数,确定它是否在该空间以及该空间的下半部分,并将其分类为小数。找到小数点后,我们可以将其插入到我们上面预测的数字字符串中。

只在黄色部分中查找小数
2.1.9 将识别的数字裁剪
cropped = eroded[y:y + h, x: x + w]
直接选用img[h, w, c]进行切割。
三、 对切割的数字进行预测
3.1 数字训练
在机器学习的世界中,解决OCR问题是一个分类问题。我们建立了一组训练有素的数据,例如图像处理中的数字,将它们分类为某种东西,然后使用该数据来匹配任何新图像。一旦基本的图像隔离功能开始工作,我就创建了一个脚本,generate_distorted_images.py,该脚本可以遍历图像文件夹,运行数字隔离代码,然后将裁剪的数字保存到新文件夹中供我查看。运行完之后,我会有一个未经训练的数字文件夹,然后可以用来训练系统。(其实感觉是对裁剪好的数字图像进行腐蚀或者膨胀操作,然后增加数字图像的,类似于数据增强的操作一样)

由于OpenCV已经包含了k近邻(k-NN)实现,因此无需引入任何其他库。为了进行训练,我们浏览了数字图像的文件夹,然后将其放入标有0–9的新文件夹中,因此每个文件夹中都有一个数字的不同版本的集合。我们没有大量的这些图像,但是有足够的证据来证明这是可行的。由于这些数字是相当标准的,我认为我不需要大量训练有素的图像就可以相当准确。
k-NN工作原理的基础是,我们将以黑白方式加载每个图像,将该图像存储在每个像素处于打开或关闭状态的数组中,然后将这些打开/关闭像素与特定的数字相关联。然后,当我们要预测一个新图像时,它将找出哪个训练图像与这些像素最匹配,然后向我们返回最接近的值。frameProcessor.py
# 调用cv2.ml.KNearest_create()创建一个KNN分类器, # 然后调用train方法进行训练, # 调用findNearest方法进行测试, # findNearest的返回值result表示根据knn算法得到的测试图像对应的标签,neighbours表示测试图像的k个最近邻,dist表示相应最近邻的距离
整理好数字后,将创建一个新的脚本,该脚本将遍历这些文件夹,获取每个图像并将该图像与数字关联。到目前为止,在大多数代码中,一般的图像处理概念在Python和C ++中都应用相同,但是在这里会有细微的差别。train_model.py文件写分类结果
在大多数此类应用程序的Python示例中,分类被写入两个文件,一个包含分类,另一个包含该分类的图像内容。通常使用NumPy和标准文本文件完成此操作。但是,由于我想在iOS应用程序上重用该系统,因此我需要想出一种可以拥有跨平台分类文件的方式。当时,我什么都找不到,因此最终编写了一个快速实用程序,该实用程序将从Python中获取分类数据并将其序列化为JSON文件,我可以在OpenCV的FileStorage系统的C ++端使用它。这不漂亮,但是我写了一个简单的MatPython中的序列化方法,它将为OpenCV创建合适的结构以在iOS端读取。现在,当我训练数字时,我将获得NumPy文件供我的Python测试使用,然后获取一个JSON文档,我可以将其拖到我的iOS应用程序中。您可以在此处看到该代码。
3.2 预测
有两个等高线轮廓,一个带潜在位数,一个带潜在小数位,我们可以使用这些轮廓边界裁剪图像,并将其输入经过训练的系统中以预测其值。有关此过程的更多信息,请参见“3.1 数字训练”部分。

四、优化
playground.py
一旦确定了数字隔离和预测的两个目标,就需要对算法进行优化,以预测泵的新图像上的数字。
在优化的初始阶段,创建了一个简单的Playground应用程序,其中使用了OpenCV提供的一些简单的UI组件。使用这些组件,可以创建一些简单的轨迹栏,以左右滑动并更改不同的值并重新处理图像。围绕该cv2.imshow方法创建了一个小包装程序,该方法可以平铺显示的窗口,因为我讨厌总是重新放置它们,

尝试不同的变量
我们可以加载不同的图像,并在图像处理中尝试变量的不同变化,并确定最佳的组合。
五、自动化
test_processing.py中的bulk_run方法
在每个图像上测试不同的变量是上手的好方法,但是我们想要一种更好的方法来验证是否更改了一个图像的变量是否会对其他任何图像产生影响。为此,我们想出了针对这些图像进行一些自动化测试的系统。
我拍摄了每个测试图像,并将它们放在文件夹中。然后,我用图像中期望的数字来命名每个文件,并用小数点“ A”表示。应用程序可以加载该目录中的每个图像并预测数字,然后将其与文件名中的数字进行比较以确定是否匹配。这使我们可以针对所有不同的图像快速尝试更改。
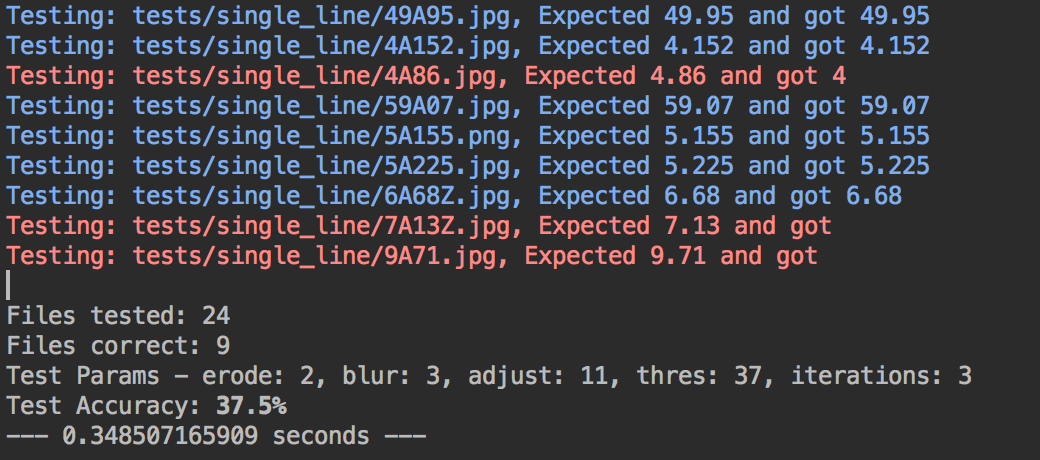
自动测试输出
更进一步,我创建了此脚本的不同版本,该脚本将尝试对这组图像进行模糊,阈值等变量的几乎每种组合,并找出最优化的变量集将具有最佳的性能。准确性。该脚本在计算机上花费了相当长的时间才能运行,大约需要7个小时,但是最后提出了一组不同的变量,这些变量在我们手动测试时找不到。
六、结论
这是否是任何人实际上都会使用的功能尚待确定,但这在实现某些机器学习概念和使用OpenCV方面是一个有趣的练习。到目前为止,在我们的测试中,应用程序最大的问题是泵显示屏上的眩光。根据泵上的照明和手机的角度,可能会导致某些扫描失效。
代码链接: https://download.csdn.net/download/weixin_45823221/87364739