1.1Well-posed learning problems
什么是机器学习?
一个程序在任务T中的表现P随着之前的经验E而提高。
简单来说,就是程序先从经验E中学习,学习的越多,在后面的任务T中表现P就越好。
例如一个下棋软件,可以通过和自己大量的下棋(经验E),在下棋这一方面(任务T)提高下棋的胜率(表现P)。
下面将用E代表经验,T代表任务,P代表表现。
为了认清楚学习的适应问题,必须像上面的例子一样识别出三个特点:经验E,任务T,表现P
下面是更多的例子:
识别手写字的学习系统:
T:识别图像中的手写字并分类

P:识别的正确率
E:从一个已给出对应分类的手写字数据库中读取数据
机器人驾驶系统:
T:通过视觉感应器在高速路上行驶
P:在出错前行驶的距离
E:一系列的图片以及对应的人类四级驾驶操作
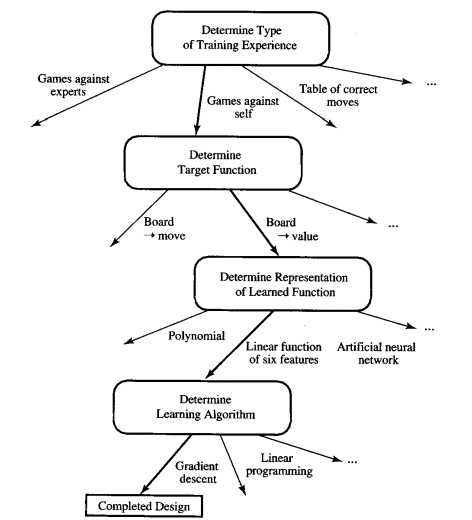
1.2设计学习系统
下面将以一个将进入世界下棋锦标赛的下棋软件为例,具体介绍设计学习系统的细节。表现P为在世界锦标赛中的胜率。
1.2.1经验E的选择
在设计学习系统面临的第一个选择就是经验E种类的选择。下面将从三个属性分别论述E的选择
1.程序或者系统做的选择是由E提供的直接的还是间接的反馈
直接的反馈是给出大量已有棋局和每个棋局正确的下法。
间接的反馈是给出双方每一步下的棋,和最终的胜负。这样每一步下棋的选择必须间接的从最终是否胜利来判断。对于这种情况,学习程序将会面临一个评分系统的设计问题,需要合理的给每步棋在不同的棋局中评分,而这是很难做到的。比如,最终胜利的一方他的每步棋分数更高,失败的一方会更低。但是失败方有可能前期下的都是最优解,但是在后期没下好导致失败。如果评分制度无法识别这一点,容易导致对于失败方前期下的棋评分的偏低。
所以,一般从直接的反馈中学习是更容易的。
2.学习程序对于训练样本的掌控程度
可能有下面几种情况:
1.依赖于老师(人类)提供的棋局和提供的正确走法
2.提出不理解的棋局并要求提供正确走法
3.完全掌控棋局,只和自己下。
在第三种情况下,程序有可能会实验到从来没有遇到过的棋局,或者修改某几步的走法来磨炼技术。接下来几章将详细介绍学习的设置,包括通过随机过程提供训练经验,向’老师‘(人类)提问,和自由的探索环境以收集训练素材的设置。
3.E和最终用来测试P的T的关联度。
一般而言,E和T的关联度,或者分布越接近,E就越可靠。在例子中,P是计算在世界锦标赛(与人对抗)中胜率。如果程序只是和自己下棋,他的E(只和自己训练产生的棋谱)可能并不能完全覆盖接下来测试时的各种情况。某些人类棋手下的常见棋局有可能程序从来没遇到过。由于E和测试棋谱的分布不一样,在E中的良好表现不一定能带来在测试棋谱中的良好表现(例如像星际这类的moba类游戏,有可能ai自己打就是打运营,和人类打轻松被rush干掉)。现在机器学习的理论都是建立在E和测试例子的分布是一样的假设上。即便我们通过这个假设获得理论结果,但是仍应该记住这个假设在实际中有可能是不成立的。
为了继续我们的设计,现在将系统设定为和自己下,这样就不需要外来训练者(人类陪练),也能在短时间内获得大量训练数据。
现在这个程序的学习任务就算是设定好了:
下棋学习系统:
T:下棋
P:世界锦标赛的胜率
E:和自己下
为了完成设计,接下来会讨论下列问题:
1.学习什么类型的知识?
2.如何表示这个知识?
3.学习的机制是什么?怎样学习?
1.2.2选择目标函数
chooseMove:B->M:
B:可能出现的局面的集合
M:不犯规的移动(棋子)的集合
简单来说,就是input为B中的一个局面时,会返回M中的最优解。很明显,如果程序是依赖于老师(人类)提供的棋局和提供的正确走法,chooseMove是很容易实现的,因为已知棋局的最优解已经给出来了。然而,因为是和自己下,E是间接的训练经验,通过学习E判断下一步是否为最优解将会非常困难。(例如之前提到的前期不错后期糟糕的情况,容易因为最终输了而给出前期走法偏低的分数。)
改动:
V:B-> R:
给所有的局面一个分数,分数越高优势越大。如果学习成功的话,可以用当前棋局找出所有可能的下一步,得出相应的新的局面,然后在新的局面中找到分数最高的,从而选择出最优的下一步。
我们现在进一步定义V:
假设现在的局面是b,b⊂B,那么
1.b是一局棋的最后局面,结果是赢,那么V(b)=100
2.b是一局棋的最后局面,结果是输,那么V(b)=-100
3.b是一局棋的最后局面,结果是平,那么V(b)=0
4.b不是一局棋的最后局面,V(b)=V(b')。b'代表在b之后所有可能的最后局面中分数最高的。
这样的话,任何局面的下一步都将是最优解。问题是,在第四种的情况中(1-3的情况里棋局已经结束了),V(b)相当于一个迭代函数,程序需要找出每一步的最优解直到游戏结束。如果b是前期的局面而不是残局的话,那么得出最优解将需要极大的运算量(类似于brutal force)。像这种运算效率低的V我们称之为nonoperational definition(不可行的定义),而我们需要做的就是让程序通过学习找到一个更加可行的V,能在一个比较实际的时间内分析棋局,选择最优解(或者比较好的下法)(discovering an operational description of the ideal target function V)。实际上,学习算法只需要做到和目标函数类似。接下来,我们将以W来表示接下来实际中使用的学习函数,以区分理想中的目标函数。
1.2.3选择目标函数(W,如前面提到的,不再用V为目标函数(因为V不可行))的表现方式
目标函数的表现方式可以有很多种选择,可以以一个很大的包括每个不同棋局和对应的分数的表格来表示,也可以是根据当前棋局的特点总结出来的一系列规则,一个多项式或者一个人工神经网络。在选择时,有一个折衷的考虑。一方面,我们希望W非常的具体,从而更接近V。另一方面,越具体的模型会需要更多的训练数据。
下面,我们将以一个简单的多项式代表W。
W(棋局)=w0+w1*x1+w2*x2+w3*x3+w4*x4+w5*x5+w6*x6
x1:黑棋数量
x2:红旗数量
x3:黑色国王数量
x4:红色国王数量
x5:受威胁的黑棋数量(受威胁:下一步会被吃掉)
x6:受威胁的红旗数量
w0到w6就是每个参数的比重,将有学习算法从训练数据中得出。
现在,棋局学习系统的设计更加完善了。
T:下棋
P:世界锦标赛的胜率
E:和自己下
目标函数:V:棋局->R
目标函数的表示方式:
W(棋局)=w0+w1*x1+w2*x2+w3*x3+w4*x4+w5*x5+w6*x6
现在我们的问题已经从学习下棋策略的一个大问题缩小到通过学习算法得出W中w0到w6的数值问题。
1.2.4逼近算法的选择
为了训练学习目标函数W,我们必须有大量的训练例子。每个例子的形式需要是<棋局,棋局分数>(需要棋局分数来调整w0到w6的数值)。下面就是一个黑方已经胜利的例子(因为红方剩余棋子x2为0),分数则为100:
<<x1=3, x2=0, x3=1, x4=0, x5=0, x6=0>, +100>
接下来的部分将介绍如何得出棋局分数,以及用逼近算法得出w0到w6
1.2.4.1预测棋局分数
我们的W并非是一个已经建立好的黑箱,输入棋局可以直接得出对应准确的棋局分数,而是需要一步步通过训练例子的学习才能构建。那么现在问题是,除了明显胜利/失败/平的分数为100/-100/0之外,如何估计其他棋局(尤其是前中期)的棋局分数?之前也提到过,最终结果的胜利不一定代表前期棋局的高分。
由于我们用的方式是系统和自己下,是无法提前人为的给出对应分数,但是能让系统预估分数又是我们程序的最终学习目标,那么该如何才能在系统学习完成之前就获得训练例子的棋局分数?
有一个很好的方法:
棋局b的分数=W(接替棋局(b))
接替棋局(b)代表着b棋局止之后系统和对手都走了一步之后的局面。
W表示当前系统学习了一部分训练例子后的W,即便尚未成熟,而不是最终构建好的目标函数W。
1.2.4.2调整权重(w0到w6)
---恢复内容结束---
1.1Well-posed learning problems
什么是机器学习?
一个程序在任务T中的表现P随着之前的经验E而提高。
简单来说,就是程序先从经验E中学习,学习的越多,在后面的任务T中表现P就越好。
例如一个下棋软件,可以通过和自己大量的下棋(经验E),在下棋这一方面(任务T)提高下棋的胜率(表现P)。
下面将用E代表经验,T代表任务,P代表表现。
为了认清楚学习的适应问题,必须像上面的例子一样识别出三个特点:经验E,任务T,表现P
下面是更多的例子:
识别手写字的学习系统:
T:识别图像中的手写字并分类
P:识别的正确率
E:从一个已给出对应分类的手写字数据库中读取数据
机器人驾驶系统:
T:通过视觉感应器在高速路上行驶
P:在出错前行驶的距离
E:一系列的图片以及对应的人类四级驾驶操作
1.2设计学习系统
下面将以一个将进入世界下棋锦标赛的下棋软件为例,具体介绍设计学习系统的细节。表现P为在世界锦标赛中的胜率。
1.2.1经验E的选择
在设计学习系统面临的第一个选择就是经验E种类的选择。下面将从三个属性分别论述E的选择
1.程序或者系统做的选择是由E提供的直接的还是间接的反馈
直接的反馈是给出大量已有棋局和每个棋局正确的下法。
间接的反馈是给出双方每一步下的棋,和最终的胜负。这样每一步下棋的选择必须间接的从最终是否胜利来判断。对于这种情况,学习程序将会面临一个评分系统的设计问题,需要合理的给每步棋在不同的棋局中评分,而这是很难做到的。比如,最终胜利的一方他的每步棋分数更高,失败的一方会更低。但是失败方有可能前期下的都是最优解,但是在后期没下好导致失败。如果评分制度无法识别这一点,容易导致对于失败方前期下的棋评分的偏低。
所以,一般从直接的反馈中学习是更容易的。
2.学习程序对于训练样本的掌控程度
可能有下面几种情况:
1.依赖于老师(人类)提供的棋局和提供的正确走法
2.提出不理解的棋局并要求提供正确走法
3.完全掌控棋局,只和自己下。
在第三种情况下,程序有可能会实验到从来没有遇到过的棋局,或者修改某几步的走法来磨炼技术。接下来几章将详细介绍学习的设置,包括通过随机过程提供训练经验,向’老师‘(人类)提问,和自由的探索环境以收集训练素材的设置。
3.E和最终用来测试P的T的关联度。
一般而言,E和T的关联度,或者分布越接近,E就越可靠。在例子中,P是计算在世界锦标赛(与人对抗)中胜率。如果程序只是和自己下棋,他的E(只和自己训练产生的棋谱)可能并不能完全覆盖接下来测试时的各种情况。某些人类棋手下的常见棋局有可能程序从来没遇到过。由于E和测试棋谱的分布不一样,在E中的良好表现不一定能带来在测试棋谱中的良好表现(例如像星际这类的moba类游戏,有可能ai自己打就是打运营,和人类打轻松被rush干掉)。现在机器学习的理论都是建立在E和测试例子的分布是一样的假设上。即便我们通过这个假设获得理论结果,但是仍应该记住这个假设在实际中有可能是不成立的。
为了继续我们的设计,现在将系统设定为和自己下,这样就不需要外来训练者(人类陪练),也能在短时间内获得大量训练数据。
现在这个程序的学习任务就算是设定好了:
下棋学习系统:
T:下棋
P:世界锦标赛的胜率
E:和自己下
为了完成设计,接下来会讨论下列问题:
1.学习什么类型的知识?
2.如何表示这个知识?
3.学习的机制是什么?怎样学习?
1.2.2选择目标函数
chooseMove:B->M:
B:可能出现的局面的集合
M:不犯规的移动(棋子)的集合
简单来说,就是input为B中的一个局面时,会返回M中的最优解。很明显,如果程序是依赖于老师(人类)提供的棋局和提供的正确走法,chooseMove是很容易实现的,因为已知棋局的最优解已经给出来了。然而,因为是和自己下,E是间接的训练经验,通过学习E判断下一步是否为最优解将会非常困难。(例如之前提到的前期不错后期糟糕的情况,容易因为最终输了而给出前期走法偏低的分数。)
改动:
V:B-> R:
给所有的局面一个分数,分数越高优势越大。如果学习成功的话,可以用当前棋局找出所有可能的下一步,得出相应的新的局面,然后在新的局面中找到分数最高的,从而选择出最优的下一步。
我们现在进一步定义V:
假设现在的局面是b,b⊂B,那么
1.b是一局棋的最后局面,结果是赢,那么V(b)=100
2.b是一局棋的最后局面,结果是输,那么V(b)=-100
3.b是一局棋的最后局面,结果是平,那么V(b)=0
4.b不是一局棋的最后局面,V(b)=V(b')。b'代表在b之后所有可能的最后局面中分数最高的。
这样的话,任何局面的下一步都将是最优解。问题是,在第四种的情况中(1-3的情况里棋局已经结束了),V(b)相当于一个迭代函数,程序需要找出每一步的最优解直到游戏结束。如果b是前期的局面而不是残局的话,那么得出最优解将需要极大的运算量(类似于brutal force)。像这种运算效率低的V我们称之为nonoperational definition(不可行的定义),而我们需要做的就是让程序通过学习找到一个更加可行的V,能在一个比较实际的时间内分析棋局,选择最优解(或者比较好的下法)(discovering an operational description of the ideal target function V)。实际上,学习算法只需要做到和目标函数类似。接下来,我们将以W来表示接下来实际中使用的学习函数,以区分理想中的目标函数。
1.2.3选择目标函数(W,如前面提到的,不再用V为目标函数(因为V不可行))的表现方式
目标函数的表现方式可以有很多种选择,可以以一个很大的包括每个不同棋局和对应的分数的表格来表示,也可以是根据当前棋局的特点总结出来的一系列规则,一个多项式或者一个人工神经网络。在选择时,有一个折衷的考虑。一方面,我们希望W非常的具体,从而更接近V。另一方面,越具体的模型会需要更多的训练数据。
下面,我们将以一个简单的多项式代表W。
W(棋局)=w0+w1*x1+w2*x2+w3*x3+w4*x4+w5*x5+w6*x6
x1:黑棋数量
x2:红旗数量
x3:黑色国王数量
x4:红色国王数量
x5:受威胁的黑棋数量(受威胁:下一步会被吃掉)
x6:受威胁的红旗数量
w0到w6就是每个参数的比重,将有学习算法从训练数据中得出。
现在,棋局学习系统的设计更加完善了。
T:下棋
P:世界锦标赛的胜率
E:和自己下
目标函数:V:棋局->R
目标函数的表示方式:
W(棋局)=w0+w1*x1+w2*x2+w3*x3+w4*x4+w5*x5+w6*x6
现在我们的问题已经从学习下棋策略的一个大问题缩小到通过学习算法得出W中w0到w6的数值问题。
1.2.4逼近算法的选择
为了训练学习目标函数W,我们必须有大量的训练例子。每个例子的形式需要是<棋局,棋局分数>(需要棋局分数来调整w0到w6的数值)。下面就是一个黑方已经胜利的例子(因为红方剩余棋子x2为0),分数则为100:
<<x1=3, x2=0, x3=1, x4=0, x5=0, x6=0>, +100>
接下来的部分将介绍如何得出棋局分数,以及用逼近算法得出w0到w6
1.2.4.1预测棋局分数
我们的W并非是一个已经建立好的黑箱,输入棋局可以直接得出对应准确的棋局分数,而是需要一步步通过训练例子的学习才能构建。那么现在问题是,除了明显胜利/失败/平的分数为100/-100/0之外,如何估计其他棋局(尤其是前中期)的棋局分数?之前也提到过,最终结果的胜利不一定代表前期棋局的高分。
由于我们用的方式是系统和自己下,是无法提前人为的给出对应分数,但是能让系统预估分数又是我们程序的最终学习目标,那么该如何才能在系统学习完成之前就获得训练例子的棋局分数?
有一个很好的方法(Vtrain):
棋局b的分数=W(接替棋局(b))
接替棋局(b)代表着b棋局之后系统和对手都走了一步之后的局面。
W表示当前系统学习了一部分训练例子后的W,即便尚未成熟,而不是最终构建好的目标函数W。
1.2.4.2调整权重(w0到w6)
接下来剩下的最后一个问题就是如果通过训练例子找到最合适的各项权重。
1.什么是‘最合适的各项权重’?
一个常用的方法是通过减少E(squared error)找出最合适的权重
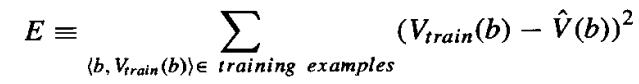
Vtrain(b):上一小节(1.2.4.1)提到的函数
![]() :之前提到的W
:之前提到的W
第六章会详细介绍为什么减少E为什么是合适的。
2.怎样根据训练例子不停地调整W?
LMS(least mean squares) training rule(最小化E)/LMS weight update rule:
对于每一个训练数据<棋局b,b的分数>:
- 用当前的W求出W(b)
- 对于每一个wi,以下面的方式更新:

同样的,
Vtrain(b):上一小节(1.2.4.1)提到的函数
![]() :之前提到的W
:之前提到的W
![]() :一个很小的常数(例如0.1),可以随着要求精确度的不同而改变
:一个很小的常数(例如0.1),可以随着要求精确度的不同而改变
假如Vtrain(b)-W=0,那么暂时不需要改动w。Vtrain(b)-W>0,那么每个w按照各自的LMS weight update rule增加,以让W和Vtrain(b)更接近。如果某个xi为0,那么不管他的w是多少,都不会有什么改变。这样保证了只有当前棋局上存在的特点才会受到影响。
1.2.5最终的设计
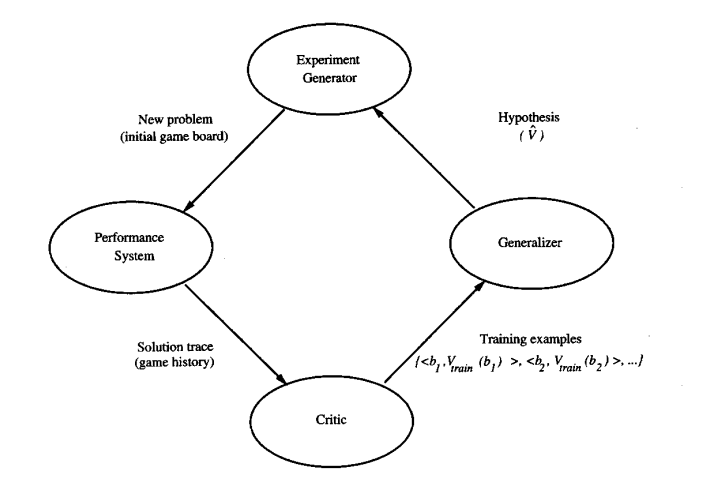
Performance system:利用当前的目标函数(W)下棋。当学习更多的训练例子后,表现也会随着W的更加成熟而提高。
Critic:从下棋过程中的棋局提取出训练例子(利用之前提到的:棋局b的分数=W(接替棋局(b)) )
Generalizer:建立一个模型代表目标函数(W),并且通过训练例子和逼近算法(LMS)以完善模型
Experiment Generator:利用当前目标函数(W)创建一个新的问题(初始棋局)。在这里,我们的学习系统创建的每一个新问题都是一样的(因为是和自己下,所以每次都是创建一样的开局)。
我们可以调整这4个部分让系统学习效率更高,我们之前设定的(目标函数,逼近算法,学习模式等)并不一定是最好的选择,然而要找到更好的选择,需要对机器学习有着更深刻的理解。这篇文章作为第一章,更多的是介绍一个简单的机器学习模型的构建流程和各个部分中的任务以及算法/函数选择,而不是系统的探讨各个选择之前的优劣。接下来的章节将会更加系统透彻的理解机器学习。
整个设计的流程可以用下图概括: