一 序
单分片的SQL查询不需要合并,多分片的情况在各分片排序完后,Sharding-JDBC 获取到结果后,仍然需要再进一步排序。目前有 分页、分组、排序、聚合列、迭代 五种场景需要做进一步处理。
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
Collection<PreparedStatementUnit> preparedStatementUnits = route();
List<ResultSet> resultSets = new PreparedStatementExecutor(
getConnection().getShardingContext().getExecutorEngine(), routeResult.getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeQuery();
result = new ShardingResultSet(resultSets, new MergeEngine(resultSets, (SelectStatement) routeResult.getSqlStatement()).merge(), this);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
merger部分源码结构如上图。核心是mergeEngine.
二 MergeEngine
MergeEngine,分片结果集归并引擎。
private final DatabaseType databaseType;
private final List<ResultSet> resultSets;
private final SelectStatement selectStatement;
private final Map<String, Integer> columnLabelIndexMap;
public MergeEngine(final DatabaseType databaseType, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
this.databaseType = databaseType;
this.resultSets = resultSets;
this.selectStatement = selectStatement;
// 获得 查询列名与位置映射
columnLabelIndexMap = getColumnLabelIndexMap(resultSets.get(0));
}
private Map<String, Integer> getColumnLabelIndexMap(final ResultSet resultSet) throws SQLException {
ResultSetMetaData resultSetMetaData = resultSet.getMetaData(); // 元数据(包含查询列信息)
Map<String, Integer> result = new TreeMap<>(String.CASE_INSENSITIVE_ORDER);
for (int i = 1; i <= resultSetMetaData.getColumnCount(); i++) {
result.put(SQLUtil.getExactlyValue(resultSetMetaData.getColumnLabel(i)), i);
}
return result;
}当 MergeEngine 被创建时,会传入 resultSets 结果集集合,并根据其获得 columnLabelIndexMap 查询列名与位置映射。
MergeEngine.merge()方法作为入口提供查询结果归并功能,源码如下:
/**
* Merge result sets.
*
* @return merged result set.
* @throws SQLException SQL exception
*/
public ResultSetMerger merge() throws SQLException {
selectStatement.setIndexForItems(columnLabelIndexMap);
return decorate(build());
}2.1 SelectStatement#setIndexForItems()
/**
* Set index for select items.
*
* @param columnLabelIndexMap map for column label and index
*/
public void setIndexForItems(final Map<String, Integer> columnLabelIndexMap) {
setIndexForAggregationItem(columnLabelIndexMap);
setIndexForOrderItem(columnLabelIndexMap, orderByItems);
setIndexForOrderItem(columnLabelIndexMap, groupByItems);
}部分查询列是经过推到出来,在 SQL解析 过程中,未获得到查询列位置,需要通过该方法进行初始化。这里可以结合SQL改写部分进行理解。
#setIndexForAggregationItem() 处理 AVG聚合计算列 推导出其对应的 SUM/COUNT 聚合计算列的位置:
private void setIndexForAggregationItem(final Map<String, Integer> columnLabelIndexMap) {
for (AggregationSelectItem each : getAggregationSelectItems()) {
Preconditions.checkState(columnLabelIndexMap.containsKey(each.getColumnLabel()), String.format("Can't find index: %s, please add alias for aggregate selections", each));
each.setIndex(columnLabelIndexMap.get(each.getColumnLabel()));
for (AggregationSelectItem derived : each.getDerivedAggregationSelectItems()) {
Preconditions.checkState(columnLabelIndexMap.containsKey(derived.getColumnLabel()), String.format("Can't find index: %s", derived));
derived.setIndex(columnLabelIndexMap.get(derived.getColumnLabel()));
}
}
}#setIndexForOrderItem() 处理 ORDER BY / GROUP BY 列不在查询列 推导出的查询列的位置:
private void setIndexForOrderItem(final Map<String, Integer> columnLabelIndexMap, final List<OrderItem> orderItems) {
for (OrderItem each : orderItems) {
if (-1 != each.getIndex()) {
continue;
}
Preconditions.checkState(columnLabelIndexMap.containsKey(each.getColumnLabel()), String.format("Can't find index: %s", each));
if (columnLabelIndexMap.containsKey(each.getColumnLabel())) {
each.setIndex(columnLabelIndexMap.get(each.getColumnLabel()));
}
}
}2.2 ResultSetMerger
ResultSetMerger,归并结果集接口。
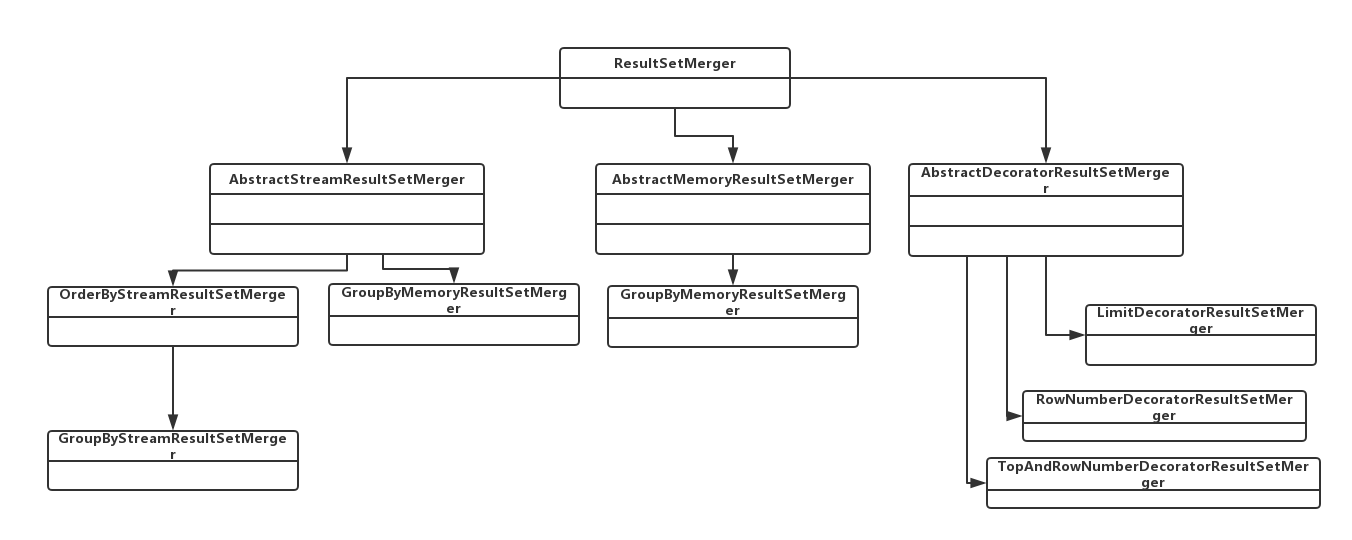
这个图主要是整理了关系。细节没有加上。
因为umlplant插件在eclipse上面只是辅助显示某个类(如下图)。不能整体展示层级关系。要是有好的办法欢迎留言告知。

从 实现方式 上分成三种:
Stream 流式:AbstractStreamResultSetMerger
Memory 内存:AbstractMemoryResultSetMerger
Decorator 装饰者:AbstractDecoratorResultSetMerger
Stream 流式:将数据游标与结果集的游标保持一致,顺序的从结果集中一条条的获取正确的数据。看完下文第三节 OrderByStreamResultSetMerger 可以形象的理解。
Memory 内存:需要将结果集的所有数据都遍历并存储在内存中,再通过内存归并后,将内存中的数据伪装成结果集返回。看完下文第五节 GroupByMemoryResultSetMerger 可以形象的理解。
Decorator 装饰者:可以和前二者任意组合
build()方法源码如下:
public ResultSetMerger merge() throws SQLException {
selectStatement.setIndexForItems(columnLabelIndexMap);
return decorate(build());
}
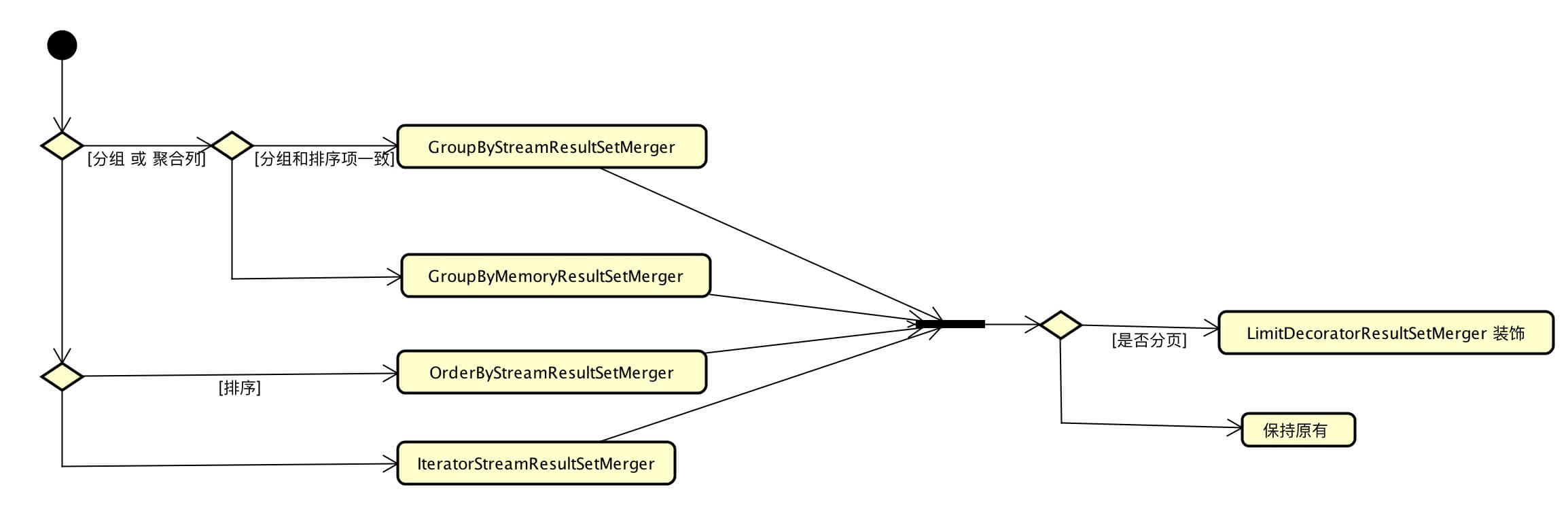
private ResultSetMerger build() throws SQLException {
//分组或者聚合,个人觉得把里面条件拆出来更直观些
if (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) {
if (selectStatement.isSameGroupByAndOrderByItems()) {
return new GroupByStreamResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
} else {
return new GroupByMemoryResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
}
}
//如果select语句中有order by字段,那么需要OrderByStreamResultSetMerger对结果处理
if (!selectStatement.getOrderByItems().isEmpty()) {
return new OrderByStreamResultSetMerger(resultSets, selectStatement.getOrderByItems());
}
return new IteratorStreamResultSetMerger(resultSets);
} private ResultSetMerger decorate(final ResultSetMerger resultSetMerger) throws SQLException {
Limit limit = selectStatement.getLimit();
if (null == limit) {
return resultSetMerger;
}
if (DatabaseType.MySQL == limit.getDatabaseType() || DatabaseType.PostgreSQL == limit.getDatabaseType() || DatabaseType.H2 == limit.getDatabaseType()) {
return new LimitDecoratorResultSetMerger(resultSetMerger, selectStatement.getLimit());
}
if (DatabaseType.Oracle == limit.getDatabaseType()) {
return new RowNumberDecoratorResultSetMerger(resultSetMerger, selectStatement.getLimit());
}
if (DatabaseType.SQLServer == limit.getDatabaseType()) {
return new TopAndRowNumberDecoratorResultSetMerger(resultSetMerger, selectStatement.getLimit());
}
return resultSetMerger;
}decorate源码可见,如果SQL语句中有limist,还需要根据数据库类型选择不同的DecoratorResultSetMerger配合进行结果归并;下面看看不同的实现方式。
2.2.1 AbstractStreamResultSetMerger
public abstract class AbstractStreamResultSetMerger implements ResultSetMerger {
private ResultSet currentResultSet;
private boolean wasNull;
protected ResultSet getCurrentResultSet() throws SQLException {
if (null == currentResultSet) {
throw new SQLException("Current ResultSet is null, ResultSet perhaps end of next.");
}
return currentResultSet;
}
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
Object result;
if (Object.class == type) {
result = getCurrentResultSet().getObject(columnIndex);
} else if (boolean.class == type) {
result = getCurrentResultSet().getBoolean(columnIndex);。。。2.2.2 AbstractMemoryResultSetMerger
AbstractMemoryResultSetMerger,内存归并结果集抽象类,提供从内存数据行对象( MemoryResultSetRow ) 获得行数据。
public abstract class AbstractMemoryResultSetMerger implements ResultSetMerger {
private final Map<String, Integer> labelAndIndexMap;
@Setter
private MemoryResultSetRow currentResultSetRow;
private boolean wasNull;
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
if (Blob.class == type || Clob.class == type || Reader.class == type || InputStream.class == type || SQLXML.class == type) {
throw new SQLFeatureNotSupportedException();
}
Object result = currentResultSetRow.getCell(columnIndex);
wasNull = null == result;
return result;
}MemoryResultSetRow调用 #load() 方法,将当前结果集的一条行数据加载到内存。
public class MemoryResultSetRow {
private final Object[] data;
public MemoryResultSetRow(final ResultSet resultSet) throws SQLException {
data = load(resultSet);
}
private Object[] load(final ResultSet resultSet) throws SQLException {
int columnCount = resultSet.getMetaData().getColumnCount();
Object[] result = new Object[columnCount];
for (int i = 0; i < columnCount; i++) {
result[i] = resultSet.getObject(i + 1);
}
return result;
}主要是获取value的方式不同。
2.2.3 AbstractDecoratorResultSetMerger
public abstract class AbstractDecoratorResultSetMerger implements ResultSetMerger {
private final ResultSetMerger resultSetMerger;
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
return resultSetMerger.getValue(columnIndex, type);
} 3 OrderByStreamResultSetMerger
看完抽象类,看看子类的实现。
OrderByStreamResultSetMerger,基于 Stream 方式排序归并结果集实现。
3.1 归并算法
归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。为啥这里适合用归并算法呢?因为之前的各个分片的结果集已经排序。
举个例子:order by order_id desc
public class OrderByStreamResultSetMerger extends AbstractStreamResultSetMerger {
@Getter(AccessLevel.NONE)
private final List<OrderItem> orderByItems;
private final Queue<OrderByValue> orderByValuesQueue;
private boolean isFirstNext;
public OrderByStreamResultSetMerger(final List<ResultSet> resultSets, final List<OrderItem> orderByItems) throws SQLException {
// sql中order by列的信息,实例sql是order by order_id desc,即此处就是order_id
this.orderByItems = orderByItems;
// 初始化一个优先级队列,优先级队列中的元素会根据OrderByValue中compareTo()方法排序,并且SQL重写后发送到多少个目标实际表,List<ResultSet>的size就有多大,Queue的capacity就有多大;
this.orderByValuesQueue = new PriorityQueue<>(resultSets.size());
// 将结果压入队列中
orderResultSetsToQueue(resultSets);
isFirstNext = true;
}
private void orderResultSetsToQueue(final List<ResultSet> resultSets) throws SQLException {
// 遍历resultSets--在多少个目标实际表上执行SQL,该集合的size就有多大
for (ResultSet each : resultSets) {
// 将ResultSet和排序列信息封装成一个OrderByValue类型
OrderByValue orderByValue = new OrderByValue(each, orderByItems);
// 如果值存在,那么压入队列中
if (orderByValue.next()) {
orderByValuesQueue.offer(orderByValue);
}
}
// 重置currentResultSet的位置:如果队列不为空,那么将队列的顶部(peek)位置设置为currentResultSet的位置
setCurrentResultSet(orderByValuesQueue.isEmpty() ? resultSets.get(0) : orderByValuesQueue.peek().getResultSet());
}
@Override
public boolean next() throws SQLException {
// 调用next()判断是否还有值, 如果队列为空, 表示没有任何值, 那么直接返回false
if (orderByValuesQueue.isEmpty()) {
return false;
}
// 如果队列不为空, 那么第一次一定返回true;即有结果可取(且将isFirstNext置为false,表示接下来的请求都不是第一次请求next()方法)
if (isFirstNext) {
isFirstNext = false;
return true;
}
// 从队列中弹出第一个元素(因为是优先级队列,所以poll()返回的值,就是此次要取的值)
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
// 如果它的next()存在,那么将它的next()再添加到队列中
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
// 队列中所有元素全部处理完后就返回false
if (orderByValuesQueue.isEmpty()) {
return false;
}
// 再次重置currentResultSet的位置为队列的顶部位置;
setCurrentResultSet(orderByValuesQueue.peek().getResultSet());
return true;
}看到这里,我觉得我之前整理的Java 集合还没完,还得补上PriorityQueue。
#offer():增加元素。增加时,会将该元素和已有元素们按照优先级进行排序
#peek():获得优先级第一的元素
#pool():获得优先级第一的元素并移除
ResultSet 构建一个 OrderByValue 包含了排序信息用于排序,
public final class OrderByValue implements Comparable<OrderByValue> {
@Getter
private final ResultSet resultSet;
private final List<OrderItem> orderByItems;
private List<Comparable<?>> orderValues;
/**
* iterate next data.
*
* @return has next data
* @throws SQLException SQL Exception
*/
public boolean next() throws SQLException {
boolean result = resultSet.next();
orderValues = result ? getOrderValues() : Collections.<Comparable<?>>emptyList();
return result;
}
private List<Comparable<?>> getOrderValues() throws SQLException {
List<Comparable<?>> result = new ArrayList<>(orderByItems.size());
for (OrderItem each : orderByItems) {
Object value = resultSet.getObject(each.getIndex());
Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable");
result.add((Comparable<?>) value);
}
return result;
}
@Override
public int compareTo(final OrderByValue o) {
for (int i = 0; i < orderByItems.size(); i++) {
OrderItem thisOrderBy = orderByItems.get(i);
int result = ResultSetUtil.compareTo(orderValues.get(i), o.orderValues.get(i), thisOrderBy.getType(), thisOrderBy.getNullOrderType());
if (0 != result) {
return result;
}
}
return 0;
}
}看看OrderByValue.next()方面里面通过 #getOrderValues() 计算该记录的排序字段值。这样两个OrderByValue 通过 #compareTo() 方法可以比较两个结果集的第一条记录。
if (orderByValue.next()) { 处,添加到 PriorityQueue。因此,orderByValuesQueue.peek().getResultSet() 能够获得多个 ResultSet 中排在第一的。
通过调用 OrderByStreamResultSetMerger#next() 不断获得当前排在第一的记录。#next() 每次调用后,实际做的是当前 ResultSet 的替换,以及当前的 ResultSet 的记录指向下一条。可以结合next()代码注释来理解。当然最好的还是debug完了之后花个图看看。比如:
假设运行SQLSELECT o.* FROM t_order o where o.user_id=10 order by o.order_id desc limit 3会分发到两个目标实际表,且第一个实际表返回的结果是1,3,5,7,9;第二个实际表返回的结果是2,4,6,8,10;那么,经过OrderByStreamResultSetMerger的构造方法中的orderResultSetsToQueue()方法后,Queue<OrderByValue> orderByValuesQueue中包含两个OrderByValue,一个是10,一个是9;接下来取值运行过程如下:
1. 取得10,并且10的next()是8,然后执行orderByValuesQueue.offer(8);,这时候orderByValuesQueue中包含8和9;
2. 取得9,并且9的next()是7,然后执行orderByValuesQueue.offer(7);,这时候orderByValuesQueue中包含7和8;
3. 取得8,并且8的next()是6,然后执行orderByValuesQueue.offer(6);,这时候orderByValuesQueue中包含7和6;
取值数量已经达到limit 3的限制(源码在LimitDecoratorResultSetMerger中的next()方法中),退出;
通过优先级队列不断的poll,offset实现了排序,设计很巧妙啊。
4. 5 GroupByStreamResultSetMerger和GroupByMemoryResultSetMerger
6. LimitDecoratorResultSetMerger
LimitDecoratorResultSetMerger,基于 Decorator 分页结果集归并实现。
public LimitDecoratorResultSetMerger(final ResultSetMerger resultSetMerger, final Limit limit) throws SQLException {
super(resultSetMerger);
// limit赋值(Limit对象包括limit m,n中的m和n两个值)
this.limit = limit;
// 判断是否会跳过所有的结果项,即判断是否有符合条件的结果
skipAll = skipOffset();
}
private boolean skipOffset() throws SQLException {
// 假定limit.getOffsetValue()就是offset,实例sql中为limit 2,3,所以offset=2
for (int i = 0; i < limit.getOffsetValue(); i++) {
// 尝试从OrderByStreamResultSetMerger生成的优先级队列中跳过offset个元素,如果.next()一直为true,表示有足够符合条件的结果,那么返回false;否则没有足够符合条件的结果,那么返回true;即skilAll=true就表示跳过了所有没有符合条件的结果;
if (!getResultSetMerger().next()) {
return true;
}
}
//行数: limit m,n的sql会被重写为limit 0, m+n,所以limit.isRowCountRewriteFlag()为true,rowNumber的值为0;
rowNumber = 0 ;
return false;
}
@Override
public boolean next() throws SQLException {
// 如果skipAll为true,即跳过所有,表示没有任何符合条件的值,那么返回false
if (skipAll) {
return false;
}
if (limit.getRowCountValue() <0) {
return getResultSetMerger().next();
} // 每次next()获取值后,rowNumber自增,当自增rowCountValue次后,就不能再往下继续取值了,因为条件limit 2,3(rowCountValue=3)限制了
return ++rowNumber <= limit.getRowCountValue() && getResultSetMerger().next();这是MySQL,PostgreSQL\H2实现方式,RowNumberDecoratorResultSetMerger是Oracle的。TopAndRowNumberDecoratorResultSetMerger是SQLserver的。对比下就是next()或者skipOffset实现方式不同。
7 IteratorStreamResultSetMerger
IteratorStreamResultSetMerger,基于 Stream 迭代归并结果集实现。
public final class IteratorStreamResultSetMerger extends AbstractStreamResultSetMerger {
private final Iterator<ResultSet> resultSets;
public IteratorStreamResultSetMerger(final List<ResultSet> resultSets) {
this.resultSets = resultSets.iterator();
// 设置当前 ResultSet,这样 #getValue() 能拿到记录
setCurrentResultSet(this.resultSets.next());
}
@Override
public boolean next() throws SQLException {
// 当前 ResultSet 迭代下一条记录
if (getCurrentResultSet().next()) {
return true;
}
if (!resultSets.hasNext()) {
return false;
}
// 获得下一个ResultSet, 设置当前 ResultSet
setCurrentResultSet(resultSets.next());
boolean hasNext = getCurrentResultSet().next();
if (hasNext) {
return true;
}
while (!hasNext && resultSets.hasNext()) {
setCurrentResultSet(resultSets.next());
hasNext = getCurrentResultSet().next();
}
return hasNext;
}
}参考:http://www.iocoder.cn/Sharding-JDBC/result-merger/
https://blog.csdn.net/feelwing1314/article/details/80237389