先写一个简单的爬虫项目
package com.kgc;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupTest {
public static void main(String[] args) {
String url = "https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&tn=monline_3_dg&wd=jsoup%E8%A7%A3%E6%9E%90html&oq=httpclient4.4.9&rsv_pq=d7f6243e00006886&rsv_t=1c21FPkhF%2BgQg6I4fQ2ZuApWm%2B5jszdGTEjEmVgQAeQV1%2FQcJwcpl1e9fVIk6IexhrHV&rqlang=cn&rsv_enter=1&inputT=5488&rsv_sug3=34&rsv_sug1=35&rsv_sug7=100&rsv_sug2=1&prefixsug=jsoup&rsp=1&rsv_sug4=6912&rsv_sug=1";
try {
Document doc = Jsoup.connect(url).get();
// System.out.println(doc.html());
Elements es = doc.select("h3.t a");
for (Element e : es) {
System.out.println("h3.t a:\n" + e.attr("href") + "\n" + e.text());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Anti-Spider(反爬虫)
为什么要反爬
反爬虫策略
1.限IP
2.限User Agent
3.组合
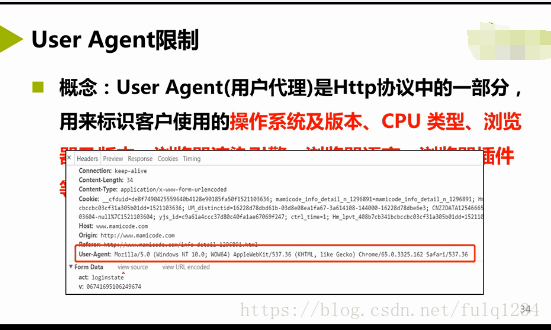
User Agent限制
概念
Anti-Anti-Spider(反反爬)策略
1.设置User Agent
2.动态代理IP
概念:爬虫过程中使用不同ip去进行爬虫

Jsonp设置User Agent
1.语法
Jsonp.connect(url).header("User-Agent","Mozilla/5.0 .... ");
2.策略
设置真实的User Agent
Jsonp设置 IP
1.设置IP
2.获取IP方法
(1).免费代理IP库
(2).付费IP代理
http://www.goubanjia.com/buy/dynamic.html
反反爬
/*获取代理ip*/
public class ProxyIPUtils{
public static ProxyIp getProxyIp(){
String url = "<获取ip的地址>";
try{
String ipStr = Jsonp.connect(url).get().text();
String ip = ipStr.split(regex:":")[0];//冒号前面的是ip,冒号后面的是端口
String port = ipStr.split(regex:":")[1];
ProxyIp p = new ProxyIP();
p.setPort(Integer.parseInt(port));
p.setIp(ip);
}catch(IOException e){
/*如果出现异常,比如请求ip太频繁
线程缓存2秒,然后递归调用方法。
Thread.sleep(millis:2000)
return getProxyIp();*/
}
return p;
}
}
/**
*/
public Class DocumentUtil{
/**
url:要爬取的地址
**/
public static Document getDocument(String url){
Connection connection = Jsonp.connect(url);
String usergent = "";//设置合法的useragent
connection.userAgent(usergent);//不同浏览器有不同的userAgent
//connection.header();
//设置动态代理ip
Document document = setProxyIp(connection);
return document;
}
public static Document setProxyIp(Connection connection){
Document document = null;
ProxyIp proxyIp = new ProxyIp();
try{
proxyIp = ProxyIPUtils.getProxyIp();
connection.proxy(proxyIp.getIp(),proxyIp.getPort());
document = connection.get();
}catch(IOException e){//如果出现异常,要求还能继续爬取,所以要捕捉异常,休眠几秒,再递归
try{
Thread.sleep(millis:5000);
return setProxyIp(connection);
}catch(IOException e){
e.printStackTrace();
}
e.printStackTrace();
}
return document;
}
}
分词器

2.过滤掉无效词汇
3.统计有效词汇出现概率
算法:(出现次数/总招聘数)
前两部用分词
分词作用
切割:将一段文字进行词语切分
筛选:
无效词过滤
拓展词定义
常见分词器
IKAnalyzer
1.引入依赖
2.配置IKAnalyzer.cfg.xml

3.设置停止词,扩展词
@Controller
@RequestMapping("/ik")
public class IKController{
@Resource
private RecuitService rService;
@Resource
private KeywordService kservice;
@RequestMapping("/ikDataDeal")
@ResponseBody
public String ikDataDeal(){
/**获取所有的招聘信息,
**/
Map<String,Object> map = new HashMap<String,Object>();
map.put("datatype",1");//放歌数据类型
List<RecruitVo> list = rService.getReByMap();//具体再写
//遍历招聘信息,将所有的招聘信息进行分词处理
for(int i = 0;i<list.size();i++){
String jobDesc = list.get(i).getJobDescription();
Integer rid = list.get(i).getId();
//再用刚才写的类进行分词处理
Set<String> set = new HashSet<String>();
set = IKUtils.getKeyword(jobDesc);
for(String word: set){
Keyword keyword = new Keyword();//实体类和keyword表进行映射
keyword.setRid(rid);
keyword.setName(word);//分词出的每一个词
keyword.setStatus(0);//0:没有删除;1:已经删除
keyword.setDataType(1);
keywordService.kdkk(keyword);//入库操作
}
}
}
}
public clas IKUtils{
/**
* @param jobDesc:工作描述
* @return set 分词之后的词,set 也去重
*/
public static Set<String> getKeyWord(String jobDesc) throws Exception{
//estword.etc:扩展词词典
//stopword.etc:停用词词典,这个是不用关心的词
Set<String> set = new HashSet<String>();
//set中不允许重复
String jobstr = jobDesc.trim();
StringReader reader = new StringReader(jsonstr);
IKSegmenter ikSementer = new IKSegment(reader,userSmart:true);
Lexene lexene = null;//词,分析出来的词
while(lexene = ikSementer.next() != null){
String job = lexene.getLexeneText().trim();
set.add(job);
}
return set;
}
}