
R-CNN
背景
自从CNN以来,计算机视觉是一个跨学科领域,近年来受到越来越多的关注,并且自动驾驶汽车已成为焦点。计算机视觉的另一个组成部分是对象检测。对象检测有助于姿态估计,车辆检测,监视等。对象检测算法与分类算法之间的区别在于,在检测算
法中,我们尝试在感兴趣的对象周围绘制一个边界框以将其定位在图像中。此外,在对象检测情况下,您不一定会只绘制一个边界框,在图像中可能有许多边界框代表不同的感兴趣对象,并且您可能事先不知道有多少个边界框。
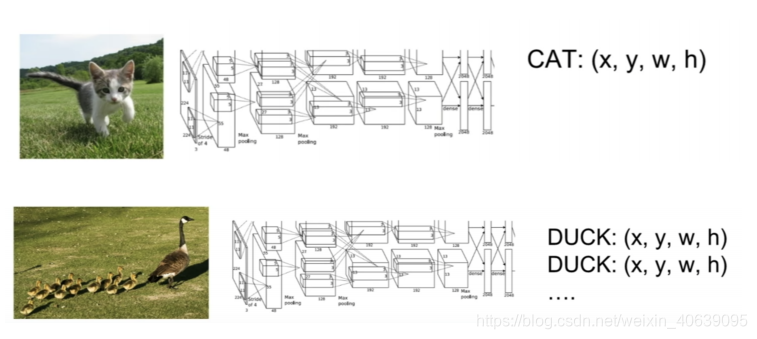
您不能通过建立标准的卷积网络以及完全连接的层来解决此问题的主要原因是,输出层的长度是可变的-不是恒定的,这是因为感兴趣的对象的出现次数是不固定。解决此问题的幼稚方法是从图像中获取不同的感兴趣区域,并使用CNN对该对象在该区域内
的存在进行分类。这种方法的问题在于,感兴趣的对象可能在图像中具有不同的空间位置和不同的纵横比。因此,您将不得不选择大量的区域,这可能会导致计算爆炸。因此,已经开发了诸如R-CNN,YOLO等算法来发现这些事件并快速找到它们。
神经网络
为了绕过选择大量区域的问题,Ross Girshick等人。提出了一种方法,其中我们使用选择性搜索从图像中仅提取2000个区域,他将其称为区域建议。因此,现在,您可以尝试使用2000个区域,而不必尝试对大量区域进行分类。使用下面编写的选择性搜索算法生成了这2000个区域建议。
选择性搜索:
- 生成初始子细分,我们生成许多候选区域
- 使用贪婪算法将相似区域递归组合为较大区域
- 使用生成的区域生成最终候选区域建议
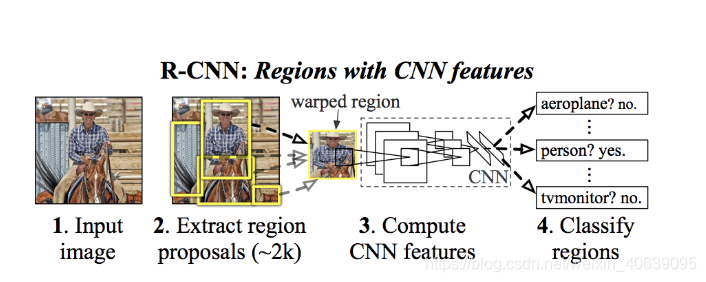
要了解有关选择性搜索算法的更多信息,请点击此链接。将这2000个候选区域建议输入到卷积神经网络中,该卷积神经网络生成4096维特征向量作为输出。CNN用作特征提取器,输出密集层包含从图像中提取的特征,并将提取的特征馈送到SVM中分类对象在该候选区域提议中的存在。除了预测区域提议中对象的存在之外,该算法还预测四个值,这些值是偏移值,以提高边界框的精度。例如,给定一个区域提议,该算法将预测一个人的存在,但是该人在该区域提议中的面孔可以被切成两半。因此,偏移值有助于调整区域建议的边界框。
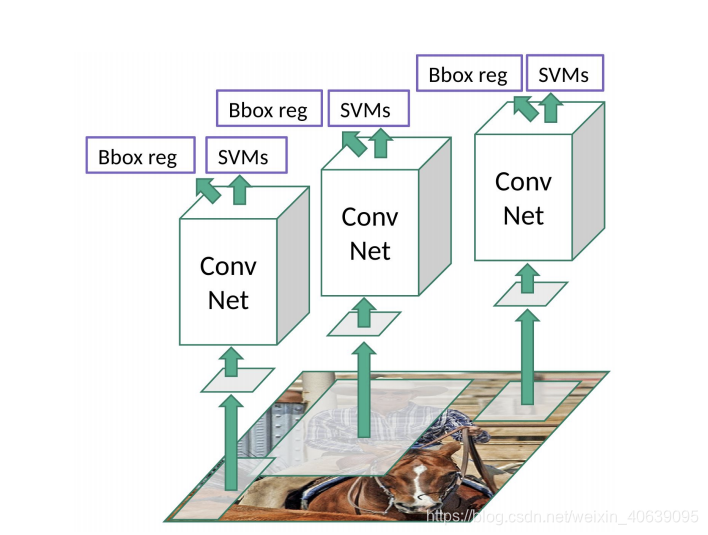
R-CNN的问题
- 训练网络仍然需要大量时间,因为您必须为每个图像分类2000个区域建议。
- 由于每个测试图像大约需要47秒,因此无法实时实施。
- 选择性搜索算法是固定算法。因此,在那个阶段没有学习发生。这可能导致生成不良的候选区域建议。
Fast R-CNN
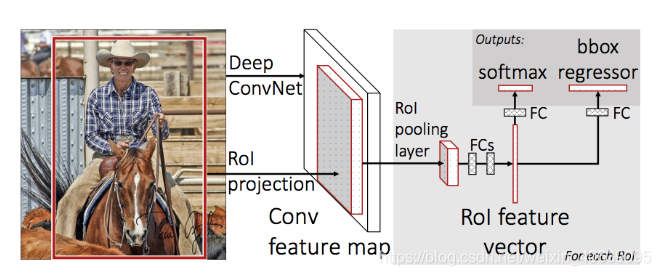
为了解决了R-CNN的一些缺点,以构建一种更快的对象检测算法,该算法称为Fast R-CNN。该方法类似于R-CNN算法。但是,我们不是将区域提议提供给CNN,而是将输入图像提供给CNN以生成卷积特征图。从卷积特征图中,我们确定提议的区域并将其扭曲为正方形,并通过使用RoI合并层将它们重塑为固定大小,以便可以将其馈送到完全连接的层中。根据RoI特征向量,我们使用softmax层来预测拟议区域的类别以及边界框的偏移值。
Fast R-CNN比R-CNN更快的原因是,您不必每次都向卷积神经网络提供2000个区域建议。取而代之的是,每个图像仅进行一次卷积操作,并从中生成特征图。
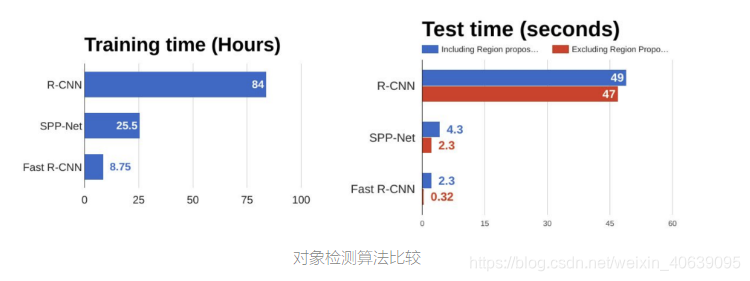
Faster R-CNN
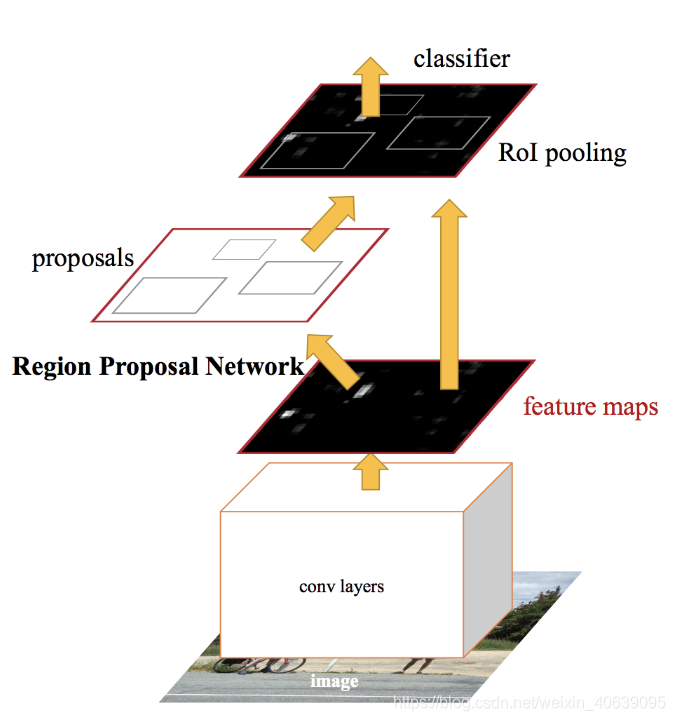
以上两种算法(R-CNN和Fast R-CNN)均使用选择性搜索来找出区域提议。选择性搜索是一个缓慢且耗时的过程,会影响网络的性能。因此,提出了一种对象检测算法,该算法消除了选择性搜索算法,并让网络学习了区域提议。
与Fast R-CNN相似,将图像作为输入提供给卷积网络,后者提供卷积特征图。代替在特征图上使用选择性搜索算法来识别区域提议,而是使用单独的网络来预测区域提议。然后使用RoI合并层对预测的区域建议进行重塑,然后将其用于对建议区域内的图像进行分类并预测边界框的偏移值。
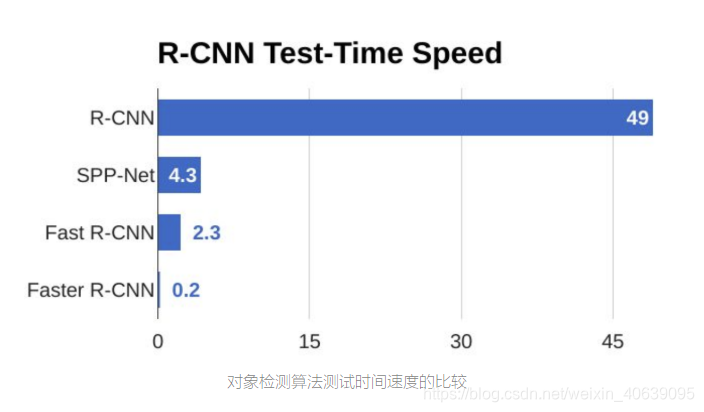
从上面的图表中,您可以看到Faster R-CNN比其前身要快得多。因此,它甚至可以用于实时物体检测。
YOLO-您只看一次
所有先前的对象检测算法都使用区域来在图像内定位对象。网络不会查看完整的图像。相反,图像中包含对象的可能性很高的部分。YOLO或“只看一次”是一种对象检测算法,与上面看到的基于区域的算法有很大不同。在YOLO中,单个卷积网络可预测边界框和这些框的类概率。
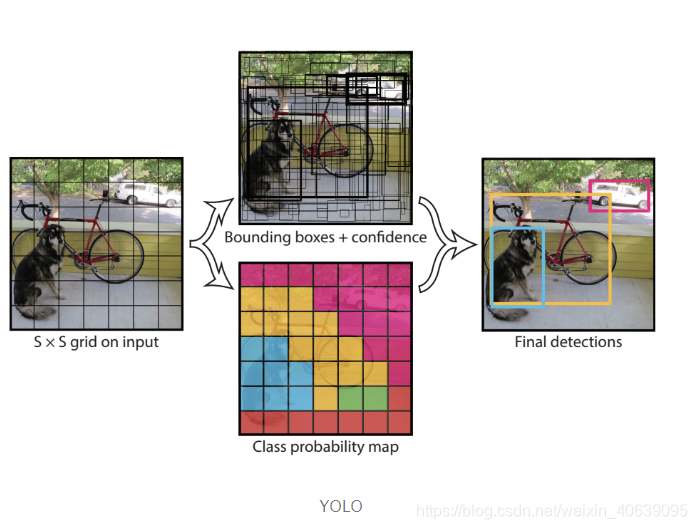
YOLO的工作方式是,我们拍摄一张图像并将其分成一个SxS网格,在每个网格中我们使用m个边界框。对于每个边界框,网络为边界框输出类别概率和偏移值。选择具有高于阈值的类别概率的边界框,并将其用于在图像内定位对象。
YOLO比其他物体检测算法快几个数量级。YOLO算法的局限性在于它难以与图像中的小物体斗争,例如,它可能难以检测到鸟类。这是由于算法的空间限制。
参考文献:
https://arxiv.org/pdf/1311.2524.pdf
https://arxiv.org/pdf/1504.08083.pdf
https://arxiv.org/pdf/1506.01497.pdf
https://arxiv.org/pdf/1506.02640v5.pdf
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
