Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,
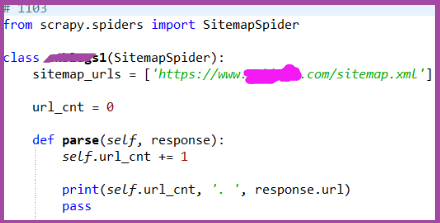
上午看了Scrapy的Spiders官文,并按照其中的SitemapSpider的示例练习,发现官文的示例存在问题——SitemapSpider下的Spider类没有name属性。

这导致孤编写的测试程序也没有name属性,结果,执行失败:No spider found in file
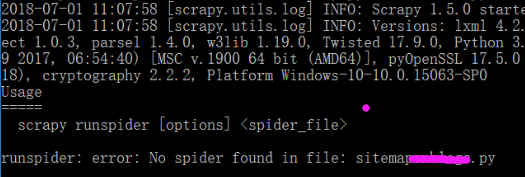
第一次执行使用的是runspider命令,失败;
第二次使用的是crawl命令——提前将爬虫文件放到某个Scrapy项目的spiders目录下,失败;
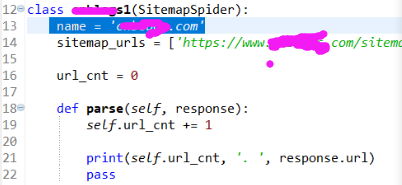
后来想起官文开始对于name属性的介绍:必须有的!
This is the most important spider attribute and it’s required.
那么,在爬虫程序中添加name属性,然后再用runspider命令执行,成功,得到了想要的信息。
关于Sitemaps的信息请参考:
What are Sitemaps? 和 Sitemap protocol
注意,并非每一个网站都有Sitemaps文件,当网站不存在Sitemaps文件时,无法用SitemapSpider抓取信息——主要抓取的是网站的链接(大型网站会有很多)。当然,按照官文的介绍,使用网站的robots.txt文件也可以(还需测试)。
孤的爬虫在测试网站发现了579个网页是使用Ctrl+C终止了爬虫的运行,否则,还会有更多:
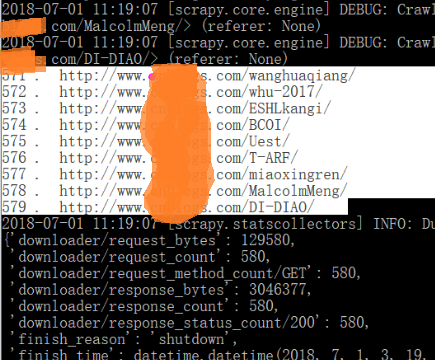
SitemapSpider有什么用呢?
抓取了网站所有【允许爬虫抓取的(Sitemap协议、robots协议)】链接,然后,再抓取各个链接中的内容。
关于robots协议:Robots exclusion standard 和 robots协议
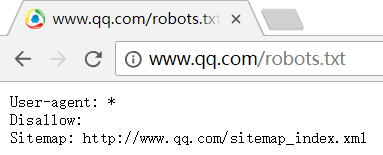
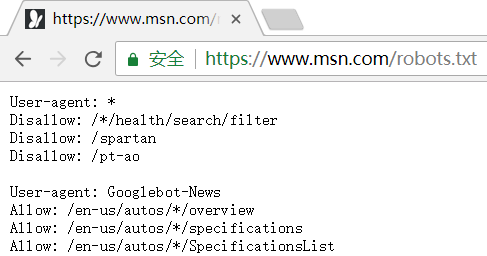
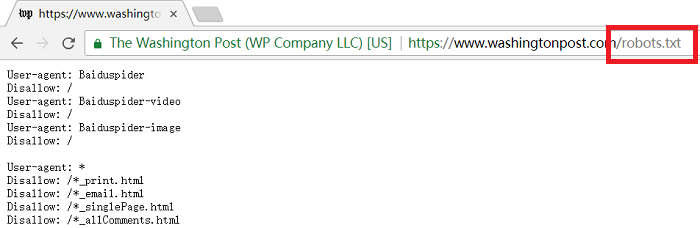
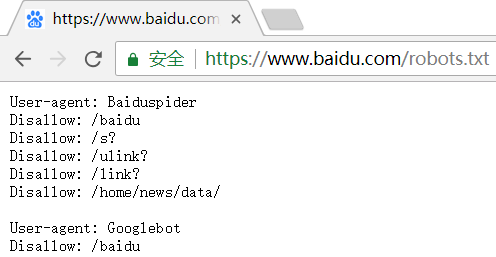
下面是一些网站的sitemap.xml或robots.txt截图:
发现很多网站时有robots.txt的,而没有sitemap.xml(或者我路径不对?),是因为robots协议是更先进的版本吗?
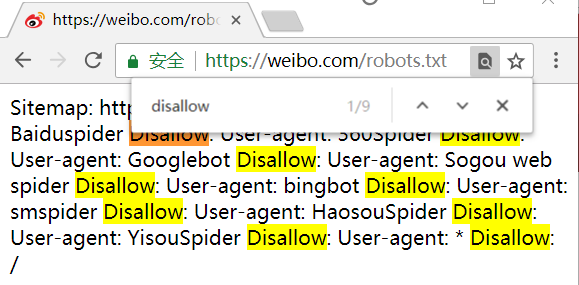
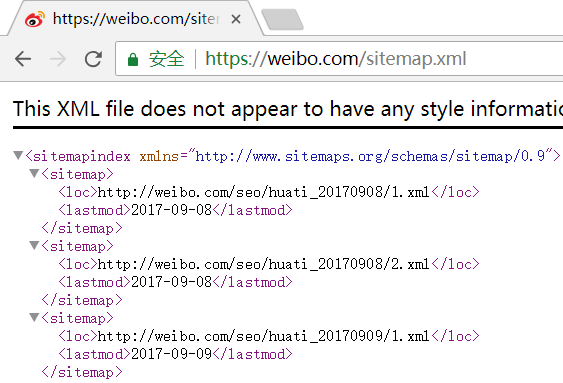
-微博几乎禁止了所有的 爬虫程序 去爬取其数据:
后记
SitemapSpider爬取了网站的链接后,是否可以交给其它爬虫程序处理?
在使用scrapy genspider创建爬虫程序时,没有名为sitemap*的模板: