说明
说明一:此篇为大数据部分第二篇,第一篇见戳链接https://blog.csdn.net/focuson_/article/details/80153371,机器的安装准备说明和zookeeper的安装已经在上一篇博客中说明。
说明二:本文为hadoop的安装,集群分布情况设计为:
机器 |
安装软件 |
进程 |
focuson1 |
zookeeper,hadoop namenode,hadoop DataNode |
JournalNode; DataNode; QuorumPeerMain; NameNode; DFSZKFailoverController;NodeManager |
focuson2 |
zookeeper;hadoop namenode,hadoop DataNode;yarn |
JournalNode; DataNode; QuorumPeerMain; NameNode; DFSZKFailoverController;NodeManager;ResourceManager |
focuson3 |
zookeeper,hadoop DataNode;yarn |
JournalNode; DataNode; QuorumPeerMain;NodeManager;ResourceManager |
安装步骤:
1、压缩包上传到focuson1家目录
cd/usr/local/src/ mkdir hadoop mv~/hadoop-2.6.0.tar.gz . tar -xvfhadoop-2.6.0.tar.gz rm -fhadoop-2.6.0.tar.gz
2、修改配置文件
1》hadoop-env.sh
exportJAVA_HOME=/usr/local/src/java/jdk1.7.0_51//必须要有的
2》yarn 与Hadoop集成
2.1 mapred-site.xml
<configuration>
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
</configuration>
2.2 yarn-site.xml
<configuration>
<!-- Site specific YARNconfiguration properties -->
<!-- 开启RM高可靠-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的clusterid -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>focuson2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>focuson3</value>
</property>
<!-- 指定zk集群地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>focuson1:2181,focuson2:2181,focuson3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3》hdfs-site.xml(端口:rpc:9000;http:50070)
<configuration> <!--meservice为ns1,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <!-- ns1下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>focuson1:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>focuson1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>focuson2:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>focuson2:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://focuson1:8485;focuson2:8485;focuson3:8485/ns1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/src/hadoop/hadoop-2.6.0/journal</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
4》core-site.xml
<configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/src/hadoop/hadoop-2.6.0/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>focuson1:2181,focuson2:2181,focuson3:2181</value> </property> </configuration>
5》、slaves
focuson1 focuson2 focuson3
4、拷贝项目到另外两台机器
scp -r /usr/local/src/hadoopfocuson2:/usr/local/src/ scp -r /usr/local/src/hadoopfocuson3:/usr/local/src/
5、进行namenode格式化
在focuson1上执行:hdfs namenode format
会在/usr/local/src/hadoop/hadoop-2.6.0(该路径即配置的hadoop.tmp.dir)生成tmp文件夹,把文件夹考到focuson2的该路径下。
*如不执行该操作,会报错
5、启动一:dfs,只需在focuson1上执行即可,会自动执行namenode/datanode/journalnode/zkfc
进入/usr/local/src/hadoop,执行 sbin/start-dfs.sh
输出日志如下:
18/04/28 19:02:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [focuson1 focuson2] focuson1: starting namenode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-focuson1.out focuson2: starting namenode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-focuson2.out focuson1: starting datanode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-focuson1.out focuson2: starting datanode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-focuson2.out focuson3: starting datanode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-focuson3.out Starting journal nodes [focuson1 focuson2 focuson3] focuson3: starting journalnode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-journalnode-focuson3.out focuson1: starting journalnode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-journalnode-focuson1.out focuson2: starting journalnode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-journalnode-focuson2.out 18/04/28 19:03:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting ZK Failover Controllers on NN hosts [focuson1 focuson2] focuson2: starting zkfc, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-zkfc-focuson2.out focuson1: starting zkfc, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-zkfc-focuson1.out
启动二:yarn,在focuson2上:
进入/usr/local/src/hadoop,执行 sbin/start-dfs.sh
[root@focuson2 hadoop-2.6.0]# ./sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-resourcemanager-focuson1.out focuson2: starting nodemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-focuson2.out focuson3: starting nodemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-focuson3.out focuson1: starting nodemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-focuson1.out
在focuson3上执行(只会启动一个resourcemanager,是为了高可用):
[root@focuson3 hadoop-2.6.0]# ./sbin/start-yarn.sh starting yarn daemons resourcemanager running as process 4258. Stop it first. focuson3: nodemanager running as process 4689. Stop it first. focuson2: nodemanager running as process 5783. Stop it first. focuson1: nodemanager running as process 7596. Stop it first.
6、验证。在focuson1上,jps:
[root@focuson1 hadoop-2.6.0]# jps 6977 DataNode 7089 JournalNode 7177 DFSZKFailoverController 7596 NodeManager 7790 Jps 4255 QuorumPeerMain 6911 NameNode
在focuson2上,
[root@focuson2 hadoop-2.6.0]# jps 6144 Jps 5505 DFSZKFailoverController 2963 QuorumPeerMain 5140 DataNode 5783 NodeManager 5047 NameNode 6056 ResourceManager 5321 JournalNode
在focuson3上:
[root@focuson3 hadoop-2.6.0]# jps 5136 Jps 4689 NodeManager 4258 ResourceManager 4419 DataNode 3044 QuorumPeerMain 4504 JournalNode
登录web界面查看:
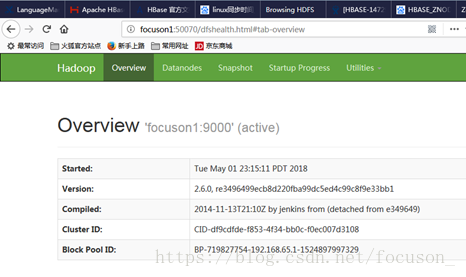
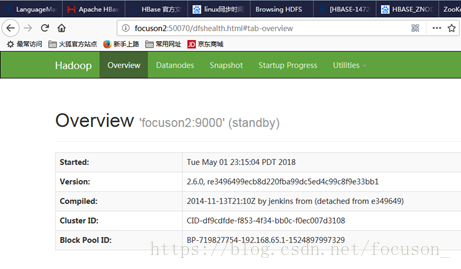
可见focuson2的namenode为standby,focuson1的为active。
在focuson1上杀掉namenode进程,会发现focuson2的为active,如下:
[root@focuson1 hadoop-2.6.0]# jps 6977 DataNode 7089 JournalNode 7177 DFSZKFailoverController 7596 NodeManager 7790 Jps 4255 QuorumPeerMain 6911 NameNode [root@focuson1 hadoop-2.6.0]# kill -9 6911
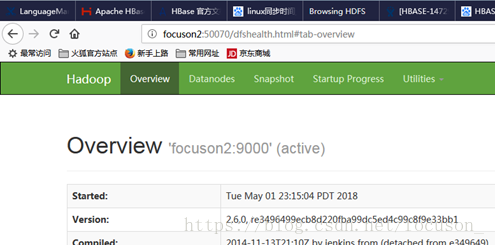
7.操作一把:
在focuson1上执行hdfs的一些命令:
touch first .txt hdfs dfs –put first.txt hdfs dfs –put /ls ......
成功!