MediaCodec
MediaCodec 类可以用来访问底层媒体编解码器,如编码器/解码器组件。是Android底层多媒体支持框架的一部分(通常和MediaExtractor,MediaSync,MediaMuxer,MediaCrypto,MediaDrm,Image, Surface, and AudioTrack一起使用)。
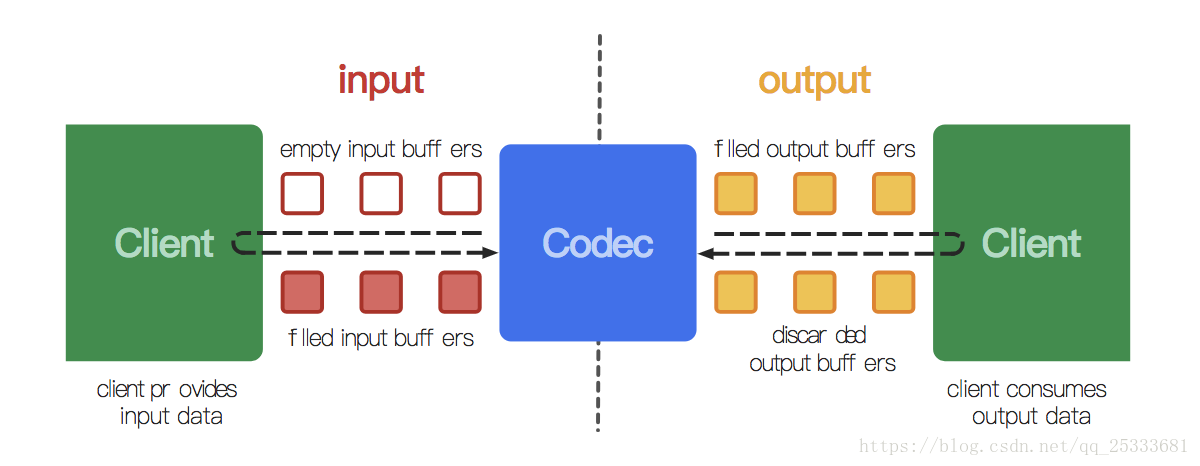
广义而言,编解码器通过处理输入数据生成输出数据。它使用一组输入以及输出缓冲区异步处理数据。简而言之,你请求(或接收)一个空的输入缓冲区,为它填充数据后将其送入编解码器做进一步处理。编解码器处理该数据,并将处理好的数据转移到一个空置的输出缓冲区。最后,你就可以请求(或者获取)一个填充满数据的输出缓冲区,消费掉它然后将输出缓冲释放回编解码器。
数据类型(DataTypes)
编解码器操作三种数据类型:压缩数据,原始音频、视频数据。这三种类型的数据都可以通过ByteBuffers处理,但对于原始视频数据,你应该使用Surface来提高编解码性能。Surface使用本地视频缓冲而不是映射或将它们拷贝到ByteBuffers;所以,它回更加高效。使用Surface,你通常无法访问原始视频数据,但是,你可以使用ImageReader类访问不安全的编码(原始)视频帧。这依然比使用ByteBuffers效率更高,因为一些本地缓冲区可能映射到direct ByteBuffers。使用ByteBuffer模式时,你可以使用Image类的getInput/OutputImage(int)方法来访问原始视频帧数据。
压缩缓冲区(Compressed Buffers)
输入缓冲区(用于解码器)和输出缓冲区(用于编码器)根据数据格式存放压缩数据。就视频类型而言,存放一个压缩视频帧,而对于音频数据类型,就是单个可访问单元(unit)(一个编码音频单元通常包含指定格式类型的几毫秒音频),但这个规定稍显宽松,因为缓冲区也可能包含多个已编码音频诗句单元。无论如何,缓冲区不会以任意字节边界开始或结束,除非在帧/可访问单元边界上,又或者被BUFFER_FLAG_PARTIAL_FRAME标记。
原始音频缓冲区(Raw Audio Buffers)
原始视频缓冲区保存有完整的PCM音频帧,这是每个通道在通道序列中的一个样本。每个样本都以本地字节序的16位有符号整数。
short[] getSamplesForChannel(MediaCodec codec, int bufferId, int channelIx) {
ByteBuffer outputBuffer = codec.getOutputBuffer(bufferId);
MediaFormat format = codec.getOutputFormat(bufferId);
ShortBuffer samples = outputBuffer.order(ByteOrder.nativeOrder()).asShortBuffer();
int numChannels = formet.getInteger(MediaFormat.KEY_CHANNEL_COUNT);
if (channelIx < 0 || channelIx >= numChannels) {
return null;
}
short[] res = new short[samples.remaining() / numChannels];
for (int i = 0; i < res.length; ++i) {
res[i] = samples.get(i * numChannels + channelIx);
}
return res;
}原始视频缓冲区(Raw Video Buffers)
在ByteBuffer模式下,视频缓冲区会根据颜色格式布局。你可以通过getCodecInfo().getCapabilitiesForType(...).colorFormats获得支持的颜色格式数组。视频编解码器支持三种类型的颜色格式:
- 本地原始视频格式:这是由
COLOR_FormatSurface标记,可用于输入或者输出表面(Surface)。 - 灵活的YUV缓冲区(例如
COLOR_FormatYUV420Flexible):可以和输入/输出表面(Surface)配合使用,也可以通过getInput/OutputImage(int)在ByteBuffer模式下使用。 - 其它特定格式:通常只有在ByteBuffer模式下支持。有些颜色格式是供应商特定的。其它的定义在
MediaCodecInfo.CodecCapabilities中。对于等效于灵活格式的颜色格式,仍然可以使用getInput / OutputImage(int)。
从LOLLIPOP_MR1开始,所有的视频编解码器都支持灵活的YUV 4:2:0缓冲区。
在旧设备上访问原始视频缓冲区。
在LOLLIPOP和Image支持之前,您需要使用KEY_STRIDE和KEY_SLICE_HEIGHT输出格式值来了解原始输出缓冲区的布局。
考虑到市面上LOLLIPOP的设备不是主流,这部分就不翻译了,想要了解的可以区官网看看。
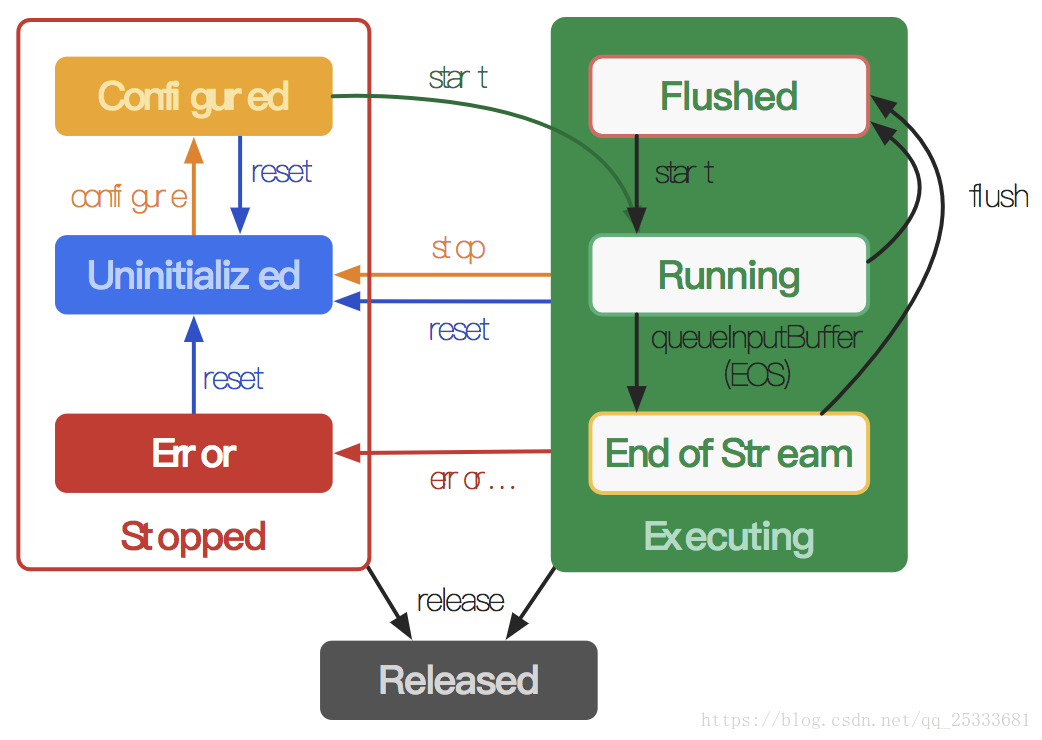
状态(States)
在MediaCodec生命周期中,概念上存在三种状态:停止,执行或释放。 停止状态实际上是三种状态的集合:未初始化,已配置和错误,而执行状态也有三个子状态:刷新,运行和结束流。
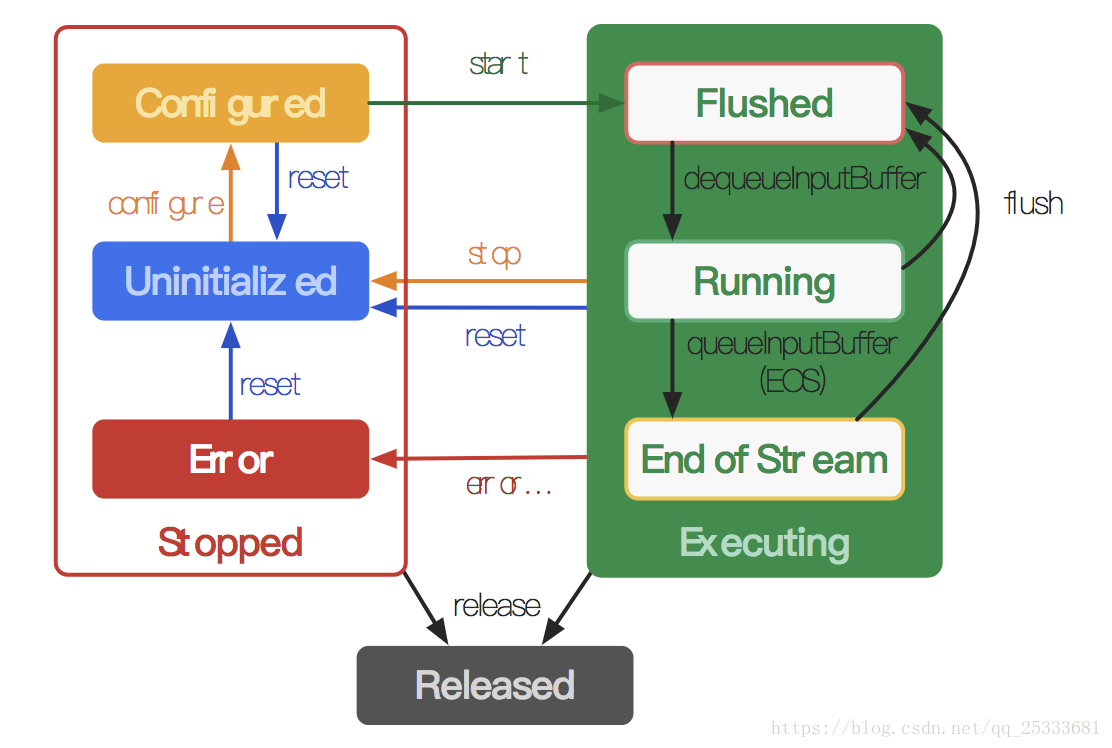
当您使用一种工厂方法创建编解码器时,编解码器处于未初始化状态。 首先,您需要通过configure(...)进行配置,将其置于Configured状态,然后调用start()将其移至Executing状态。 在这种状态下,您可以通过前面提到的缓冲区队列处理来处理数据。
Executing状态有三个子状态:刷新(Flushed),运行(Running)和结束流(End of Stream)。 在start()之后编解码器立即处于Flushed子状态,它保存所有缓冲区。 只要第一个输入缓冲区出列,编解码器就会转移到运行子状态,在该状态下它大部分时间都在使用。 当您使用流结束标记对输入缓冲区进行排队时,编解码器将转换为流结束子状态。 在这种状态下,编解码器不再接受进一步的输入缓冲器,但仍然产生输出缓冲器,直到结束流(End of Stream)达到输出端。 您可以随时在使用flush()执行状态时移回Flushed子状态。
调用stop()将编解码器返回到未初始化状态,然后再次配置它。 当您使用完编解码器时,您必须通过调用release()来释放它。
在极少数情况下,编解码器可能会遇到错误并进入错误状态。 这是使用来自排队操作的无效返回值或有时通过异常传递的。 调用reset()使编解码器再次可用。 您可以从任何状态调用它以将编解码器移回未初始化状态。 否则,调用release()移到释放(Released)状态。
创建(Creation)
使用MediaCodecList为特定的MediaFormat媒体创建MediaCodec。 在解码文件或流时,您可以从MediaExtractor.getTrackFormat获取所需的格式。 使用MediaFormat.setFeatureEnabled注入要添加的任何特定功能,然后调用MediaCodecList.findDecoderForFormat以获取可处理该特定媒体格式的编解码器的名称。 最后,使用createByCodecName(String)创建编解码器。
在LOLLIPOP上,
MediaCodecList.findDecoder / EncoderForFormat的格式不得包含帧率。 使用format.setString(MediaFormat.KEY_FRAME_RATE,null)清除格式中的任何现有帧速率设置。
您还可以使用createDecoder / EncoderByType(String)为特定的MIME类型创建首选编解码器。 但是,这不能用于注入功能,并且可能会创建无法处理特定所需媒体格式的编解码器。
创建安全的解码器
在KITKAT_WATCH和更早版本上,安全编解码器可能未列在MediaCodecList中,但也许仍在系统中可用。 这种安全编码解码器只能通过名称实例化,方法是将“.secure”附加到常规编解码器的名称之后(所有安全编解码器的名称必须以“.secure”结尾。)。如果编解码器不存在createByCodecName(String)将抛出IOException。
从LOLLIPOP开始,您应该使用媒体格式的FEATURE_SecurePlayback功能来创建安全的解码器。
初始化(Initialization)
创建编解码器后,如果要异步处理数据,可以使用setCallback设置回调。 然后,使用特定的媒体格式配置编解码器。 这是您可以为视频制作者指定输出表面 - 生成原始视频数据的编解码器(例如视频解码器)。 您也可以设置安全编解码器的解密参数(请参阅MediaCrypto)。 最后,由于一些编解码器可以在多种模式下运行,因此您必须指定是否要将其用作解码器或编码器。
由于LOLLIPOP,您可以在配置状态下查询生成的输入和输出格式。 在开始编解码器前,您可以使用它来验证最终的配置,例如 颜色格式。
如果您想要使用视频消费者处理原始输入视频缓冲区 - 处理原始视频输入的编解码器(例如视频编码器) - 使用配置后的createInputSurface()为输入数据创建目标Surface。 或者,通过调用setInputSurface(Surface)将编解码器设置为使用先前创建的输入Surface。
编解码指定数据(Codec-specific Data)
某些格式,特别是AAC音频和MPEG4,H.264和H.265视频格式要求实际数据前缀包含设置数据或编解码器特定数据的多个缓冲区。 处理这种压缩格式时,必须在start()之后、任何帧数据之前,将这些数据提交给编解码器。 在调用queueInputBuffer时,必须使用标志BUFFER_FLAG_CODEC_CONFIG标记这些数据。
编解码器指定数据也可以包含在通过密钥“csd-0”,“csd-1”等在ByteBuffer条目中进行配置的格式实体中。这些密钥始终包含在从MediaExtractor获取的轨道MediaFormat中。 在start()时,格式中指定的边界马数据会自动提交给编解码器; 你绝不能显式地提交这些数据。 如果格式不包含编解码器特定数据,则可以根据格式要求,选择使用指定数量的缓冲区以正确的顺序提交它。 在H.264 AVC的情况下,您还可以连接所有编解码器专用数据并将其作为单个编解码器配置缓冲区提交。
Android使用以下编解码器特定的数据缓冲区。 这些也需要设置为正确的MediaMuxer轨道格式。 用(*)标记的每个参数集和特定于编解码器的数据部分必须以“\ x00 \ x00 \ x00 \ x01”开始代码开头。
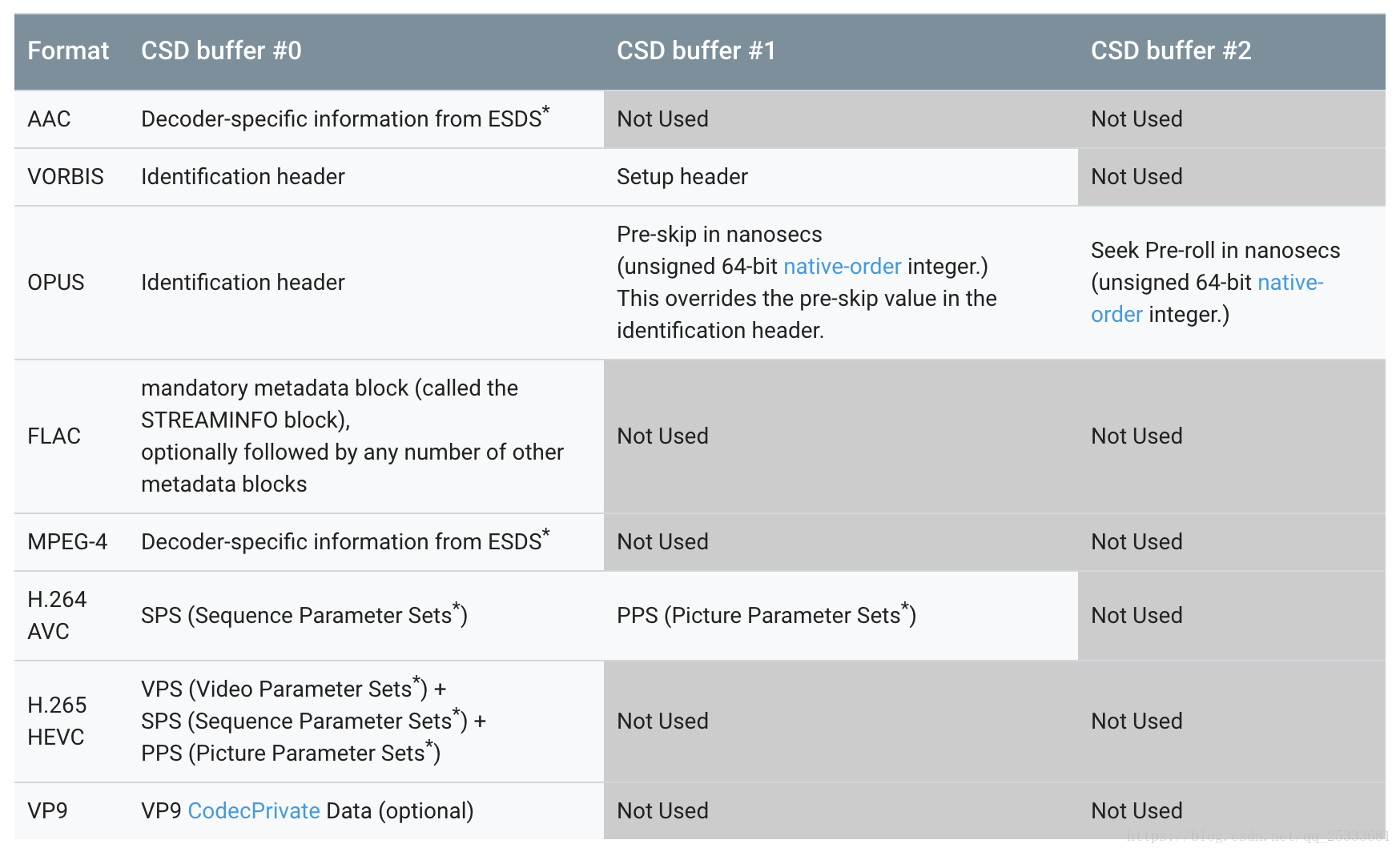
如果在
start之后立即刷新编解码器或在刷新输出缓冲区以及输出格式更改之前立即刷新编解码器,必须小心谨慎,因为在刷新期间编解码器的特定数据可能会丢失。 在这样的刷新之后,您必须使用标有BUFFER_FLAG_CODEC_CONFIG的缓冲区重新提交数据,以确保正确的编解码器操作。
在使用codec-config标志标记的输出缓冲区中的任何有效输出缓冲区之前,编码器(或生成压缩数据的解码器)将创建或返回指定的编解码数据。 包含编解码器专用数据的缓冲器没有有意义的时间戳。
数据处理(Data Processing)
每个编解码器都维护一组输入和输出缓冲区,这些缓冲区通过API调用中的buffer-ID所引用。 在成功调用start()之后,客户端不会“拥有“输入/输出缓冲区。 在同步模式下,调用dequeueInput / OutputBuffer(...)以从编解码器获取(获取所有权)输入或输出缓冲区。 在异步模式下,您将通过MediaCodec.Callback.onInput / OutputBufferAvailable(...)回调自动接收可用的缓冲区。
在获得输入缓冲区时填充好数据,并使用queueInputBuffer 或queueSecureInputBuffer(如果使用解密)将其提交给编解码器。 不要使用相同的时间戳提交多个输入缓冲区(除非它是特定编解码器的数据标记)。
编解码器将通过异步模式下的onOutputBufferAvailable回调或者响应同步模式下的dequeuOutputBuffer调用返回一个只读输出缓冲区。 输出缓冲区处理完毕后,调用其中一个releaseOutputBuffer方法将缓冲区返回给编解码器。
虽然您不需要立即重新提交/释放缓冲区到编解码器,但握住输入和/或输出缓冲区可能会使编解码器停顿,并且此行为取决于设备。 特别是,编解码器有可能在产生输出缓冲区之前暂缓,直到所有未完成的缓冲区被释放/重新提交。 因此,尽可能少地尝试保留可用的缓冲区。
根据API版本,您可以通过三种方式处理数据:
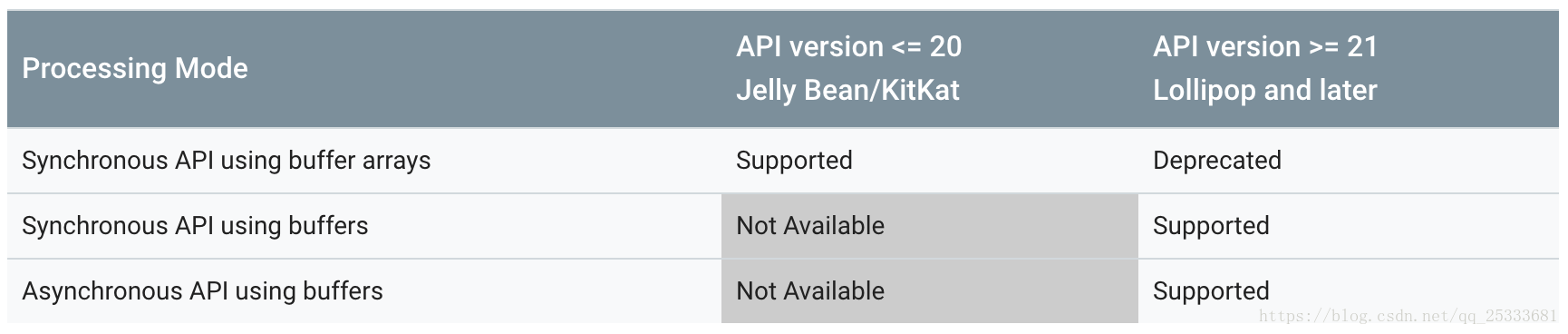
使用缓冲区的异步处理
LOLLIPOP以后,优先选择在调用configure之前通过设置回调来异步处理数据。 异步模式会稍微改变状态转换,因为您必须在flush()之后调用start()将编解码器转换为Running子状态并开始接收输入缓冲区。 同样,在初始调用start时,编解码器将直接移至Running子状态,并通过回调开始传递可用的输入缓冲区。
MediaCodec异步模式使用:
MediaCodec codec = MediaCodec.createByCodecName(name);
MediaFormat mOutputFormat; // member variable
codec.setCallback(new MediaCodec.Callback() {
@Override
void onInputBufferAvailable(MediaCodec mc, int inputBufferId) {
ByteBuffer inputBuffer = codec.getInputBuffer(inputBufferId);
// fill inputBuffer with valid data
…
codec.queueInputBuffer(inputBufferId, …);
}
@Override
void onOutputBufferAvailable(MediaCodec mc, int outputBufferId, …) {
ByteBuffer outputBuffer = codec.getOutputBuffer(outputBufferId);
MediaFormat bufferFormat = codec.getOutputFormat(outputBufferId); // option A
// bufferFormat is equivalent to mOutputFormat
// outputBuffer is ready to be processed or rendered.
…
codec.releaseOutputBuffer(outputBufferId, …);
}
@Override
void onOutputFormatChanged(MediaCodec mc, MediaFormat format) {
// Subsequent data will conform to new format.
// Can ignore if using getOutputFormat(outputBufferId)
mOutputFormat = format; // option B
}
@Override
void onError(…) {
…
}
});
codec.configure(format, …);
mOutputFormat = codec.getOutputFormat(); // option B
codec.start();
// wait for processing to complete
codec.stop();
codec.release();使用缓冲区的同步处理
由于LOLLIPOP,即使在同步模式下使用编解码器时,也应该使用getInput / OutputBuffer(int)或getInput / OutputImage(int)检索输入和输出缓冲区。 这允许框架进行某些优化,例如 处理动态内容时。 如果您调用getInput / OutputBuffers(),则此优化将被禁用。
不要混合同时使用缓冲区和缓冲区数组的方法。 具体而言,只需在
start()之后或者在出队缓冲区ID为INFO_OUTPUT_FORMAT_CHANGED的值之后直接调用getInput / OutputBuffers。
MediaCodec典型的同步模式使用:
MediaCodec codec = MediaCodec.createByCodecName(name);
codec.configure(format, …);
MediaFormat outputFormat = codec.getOutputFormat(); // option B
codec.start();
for (;;) {
int inputBufferId = codec.dequeueInputBuffer(timeoutUs);
if (inputBufferId >= 0) {
ByteBuffer inputBuffer = codec.getInputBuffer(…);
// fill inputBuffer with valid data
…
codec.queueInputBuffer(inputBufferId, …);
}
int outputBufferId = codec.dequeueOutputBuffer(…);
if (outputBufferId >= 0) {
ByteBuffer outputBuffer = codec.getOutputBuffer(outputBufferId);
MediaFormat bufferFormat = codec.getOutputFormat(outputBufferId); // option A
// bufferFormat is identical to outputFormat
// outputBuffer is ready to be processed or rendered.
…
codec.releaseOutputBuffer(outputBufferId, …);
} else if (outputBufferId == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED) {
// Subsequent data will conform to new format.
// Can ignore if using getOutputFormat(outputBufferId)
outputFormat = codec.getOutputFormat(); // option B
}
}
codec.stop();
codec.release();使用缓冲区阵列的同步处理(deprecated)
在KITKAT_WATCH以及之前版本,输入和输出缓冲区集由ByteBuffer []数组表示。 在成功调用start()之后,使用getInput / OutputBuffers()检索缓冲区数组。 如以下示例所示,使用缓冲区ID-s作为这些数组中的索引(非负数时)。 请注意,尽管数组大小提供了上限,但阵列大小与系统使用的输入和输出缓冲区数量之间没有固有的相关性。
MediaCodec codec = MediaCodec.createByCodecName(name);
codec.configure(format, …);
codec.start();
ByteBuffer[] inputBuffers = codec.getInputBuffers();
ByteBuffer[] outputBuffers = codec.getOutputBuffers();
for (;;) {
int inputBufferId = codec.dequeueInputBuffer(…);
if (inputBufferId >= 0) {
// fill inputBuffers[inputBufferId] with valid data
…
codec.queueInputBuffer(inputBufferId, …);
}
int outputBufferId = codec.dequeueOutputBuffer(…);
if (outputBufferId >= 0) {
// outputBuffers[outputBufferId] is ready to be processed or rendered.
…
codec.releaseOutputBuffer(outputBufferId, …);
} else if (outputBufferId == MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED) {
outputBuffers = codec.getOutputBuffers();
} else if (outputBufferId == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED) {
// Subsequent data will conform to new format.
MediaFormat format = codec.getOutputFormat();
}
}
codec.stop();
codec.release();流结束处理(End-of-stream Handling)
当您到达输入数据的末尾时,必须通过在queueInputBuffer调用中将BUFFER_FLAG_END_OF_STREAM标志将其发送给编解码器。 您可以在最后一个有效的输入缓冲区上执行此操作,或者通过提交一个额外的空输入缓冲区并设置流结束标志。 如果使用空缓冲区,时间戳将被忽略。
编解码器将继续返回输出缓冲区,直到它通过指定dequeueOutputBuffer中设置的MediaCodec.BufferInfo中的相同流结束标志或通过onOutputBufferAvailable返回来指示输出流的结束为止。 这可以在最后一个有效的输出缓冲区上设置,或者在最后一个有效的输出缓冲区之后的空缓冲区上设置。 这个空缓冲区的时间戳应该被忽略。
除非编解码器已被刷新,停止或重新启动,否则在发出输入流结束信号后,请勿提交其他输入缓冲区。
使用输出表面(Surface)
使用输出表面时,数据处理与ByteBuffer模式几乎相同; 但是,输出缓冲区将不可访问,并表示为空值。 例如:getOutputBuffer / Image(int)将返回null,getOutputBuffers()将返回仅包含null-s的数组。
使用输出表面时,可以选择是否渲染Surface上的每个输出缓冲区。 你有三个选择:
- 不要渲染缓冲区:调用
releaseOutputBuffer(bufferId,false)。 - 使用默认时间戳呈现缓冲区:调用
releaseOutputBuffer(bufferId,true)。 - 使用特定的时间戳呈现缓冲区:调用
releaseOutputBuffer(bufferId,timestamp)。
M以后,默认时间戳是缓冲区的显示时间戳(转换为纳秒)。 在此之前没有定义。
此外,M版本以后,您可以使用setOutputSurface动态更改输出表面。
渲染到表面时的转换
如果编解码器配置为Surface模式,任何裁剪矩形,旋转和视频缩放模式将自动应用,但有一个例外:
在M版本之前,软件解码器在渲染到Surface上时可能没有应用旋转。 不幸的是,没有标准和简单的方法来识别软件解码器。
额外的警告:
请注意,将输出显示在Surface上时,不考虑像素纵横比。 这意味着如果您使用
VIDEO_SCALING_MODE_SCALE_TO_FIT模式,则必须定位输出Surface,以使其具有适当的最终显示宽高比。 相反,对于具有方形像素(像素宽高比或1:1)的内容,您只能使用VIDEO_SCALING_MODE_SCALE_TO_FIT_WITH_CROPPING模式.
另外请注意:
从N版本开始,对于旋转90度或270度的视频,
VIDEO_SCALING_MODE_SCALE_TO_FIT_WITH_CROPPING模式可能无法正常工作。
最后:
设置视频缩放模式时,请注意每次输出缓冲区更改后必须重置。 由于
INFO_OUTPUT_BUFFERS_CHANGED事件已被弃用,您可以在每次输出格式更改后执行此操作。
使用输入表面
当使用输入表面时,没有可访问的输入缓冲区,因为缓冲区会自动从输入表面传递到编解码器。 调用dequeueInputBuffer将抛出一个IllegalStateException,并且getInputBuffers()返回一个不可写入的虚构ByteBuffer []数组。
调用signalEndOfInputStream()来发信号结束。 此通话后,输入表面将立即停止向编解码器提交数据。
Seek和自适应回放支持
视频解码器(以及一般使用压缩视频数据的编解码器)在搜索和格式更改方面表现不同,无论它们是否支持并配置为自适应播放。 您可以检查解码器是否支持通过CodecCapabilities.isFeatureSupported(String)进行自适应播放。 只有将编解码器配置为解码到Surface上时,才会激活对视频解码器的自适应播放支持。
流边界和关键帧
在start()或flush()之后的输入数据从合适的流边界开始非常重要:第一个帧必须是关键帧。 关键帧可以完全自行解码(对于大多数编解码器来说,这意味着I帧),并且在关键帧之后没有要显示的帧指的是关键帧之前的帧。
下表总结了各种视频格式的合适关键帧:

对于不支持自适应回放的解码器(包括不解码到Surface上时)
为了开始解码与先前提交的数据不相邻的数据(即,在寻找之后),你必须清空解码器。 由于所有输出缓冲区在刷新时立即被撤销,因此您可能需要首先发出信号,然后在调用flush之前等待流结束。 flush后的输入数据始于合适的流边界/关键帧,这一点很重要。
注意:刷新后提交的数据格式不能改变;
flush()不支持格式不连续性; 为此,完整的stop()-configure(...)-start()周期是必要的。
另请注意:
如果您在启动()后过早刷新编解码器 - 通常在收到第一个输出缓冲区或输出格式更改之前 - 您需要重新提交编解码器特定数据到编解码器。 有关更多信息,请参阅编解码器特定的数据部分。
适用于支持和配置自适应回放的解码器
为了开始解码与先前提交的数据不相邻的数据(即,在寻找之后),不需要刷新解码器; 然而,不连续性之后的输入数据必须从合适的流边界/关键帧开始。
对于某些视频格式(即H.264,H.265,VP8和VP9),也可以在中途更改图片大小或配置。 为此,您必须将全部新的编解码器特定配置数据与关键帧一起打包到单个缓冲区(包括任何开始代码)中,并将其作为常规输入缓冲区提交。
图片大小更改后,以及在返回任何具有新大小的帧之前,您将收到来自dequeueOutputBuffer的INFO_OUTPUT_FORMAT_CHANGED返回值或onOutputFormatChanged回调。
注意:就像编解码器专用数据的情况一样,在更改图片大小后不久调用
flush()时要小心。 如果您还没有收到图片尺寸更改的确认,则需要重新请求新图片尺寸。
错误处理
工厂方法createByCodecName和createDecoder / EncoderByType在发生失败时抛出IOException,您必须捕获或声明传递失败。 当方法从不允许的编解码器状态调用时,MediaCodec方法抛出IllegalStateException; 这通常是由于不正确的应用程序API使用。 涉及安全缓冲区的方法可能会抛出MediaCodec.CryptoException,该错误信息可从getErrorCode()获得更多错误信息。
内部编解码器错误导致MediaCodec.CodecException,这可能是由于媒体内容损坏,硬件故障,资源耗尽等等,即使应用程序正确使用该API也是如此。 接收到CodecException时推荐通过调用isRecoverable()和isTransient()来确定:
- 可恢复错误:如果
isRecoverable()返回true,则调用stop(),configure(...)和start()以恢复。 - 瞬间错误:如果
isTransient()返回true,则资源暂时不可用,并且该方法可能会在稍后重试。 - 致命错误:如果
isRecoverable()和isTransient()都返回false,那么CodecException是致命的,编解码器必须重置或释放。
isRecoverable()和isTransient()都不会同时返回true。
有效的API调用和API历史
以后更新