因为项目需要简历一个森林来保存图形之间的父子关系,因此建立一种多叉树作为验证模型。具体原理如下草稿所示:

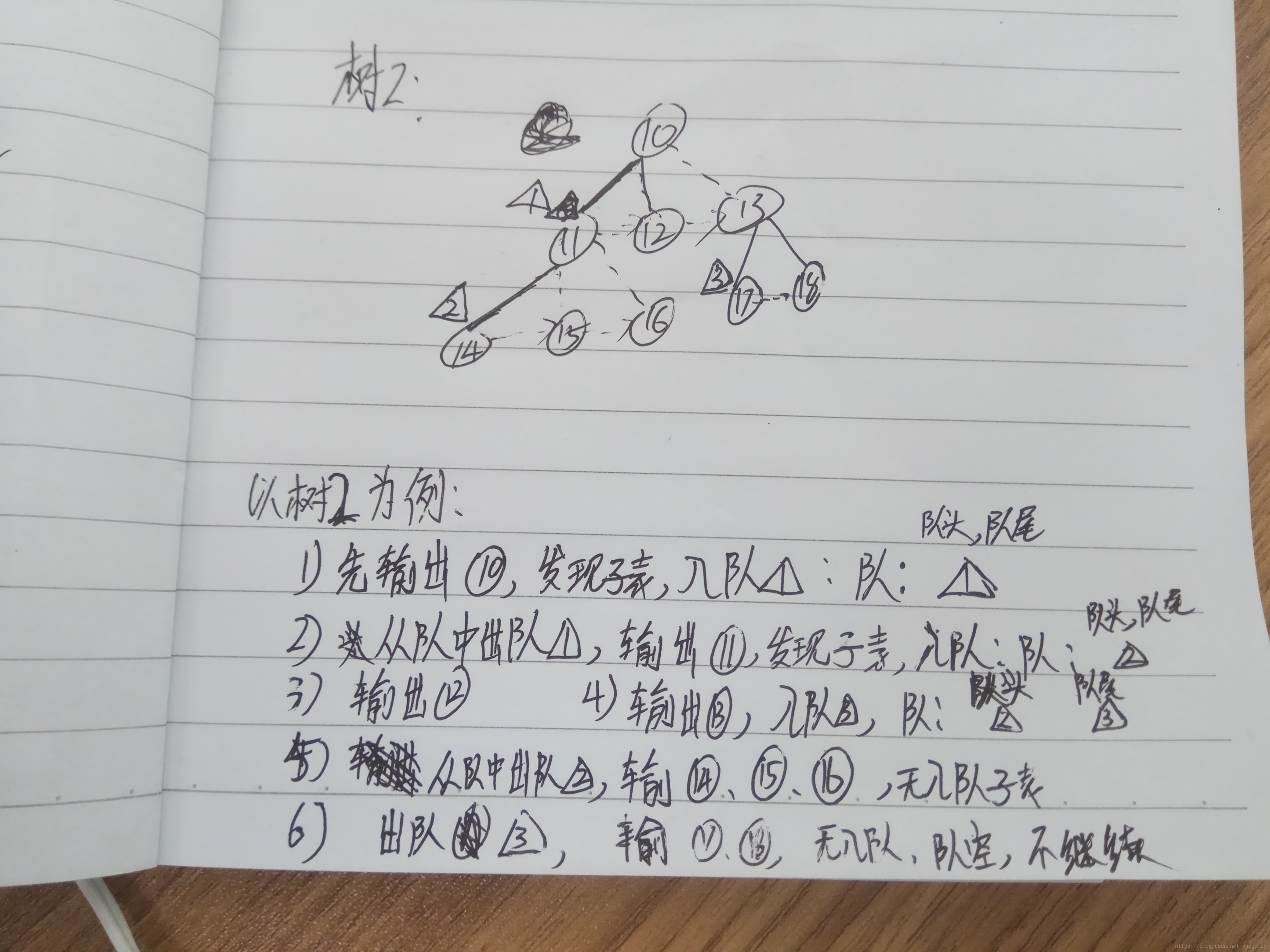
实现代码如下:
结点数据结构:
package com.test.forest;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class SerPath implements Serializable{
private int fakePath = 0;
public int layerIndex = -1;
public List<SerPath> childList = new ArrayList<>();
public SerPath(int index){
fakePath = index;
}
public int getPath(){
return fakePath;
}
}
遍历流程:
package com.test.forest;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.LinkedBlockingQueue;
public class Forest {
/**构造测试样本**/
public List<SerPath> createForest() {
/**森林表**/
List<SerPath> forestTreeHeadList = new ArrayList<>();
/**第一棵树**/
SerPath treeHead1 = new SerPath(1);
treeHead1.childList.add(new SerPath(2));
treeHead1.childList.add(new SerPath(3));
treeHead1.childList.add(new SerPath(4));
treeHead1.childList.add(new SerPath(5));
treeHead1.childList.get(2).childList.add(new SerPath(6));
treeHead1.childList.get(2).childList.add(new SerPath(7));
treeHead1.childList.get(2).childList.add(new SerPath(8));
treeHead1.childList.get(2).childList.add(new SerPath(9));
forestTreeHeadList.add(treeHead1);
/**第2棵树**/
SerPath treeHead2 = new SerPath(10);
treeHead2.childList.add(new SerPath(11));
treeHead2.childList.add(new SerPath(12));
treeHead2.childList.add(new SerPath(13));
treeHead2.childList.get(0).childList.add(new SerPath(14));
treeHead2.childList.get(0).childList.add(new SerPath(15));
treeHead2.childList.get(0).childList.add(new SerPath(16));
treeHead2.childList.get(2).childList.add(new SerPath(17));
treeHead2.childList.get(2).childList.add(new SerPath(18));
forestTreeHeadList.add(treeHead2);
return forestTreeHeadList;
}
/**遍历森林中的所有树和树节点**/
public void readForest(List<SerPath> forestTreeHeadList) {
for(SerPath treeHead : forestTreeHeadList){
Queue<List<SerPath>> layerQueue = new LinkedBlockingQueue<>();
//输出头结点的值:
System.out.println(treeHead.getPath());
//发现头结点有孩子表,表入队:
if(!treeHead.childList.isEmpty()){
layerQueue.add(treeHead.childList);
}
//只要孩子表队列不为空就循环
while(!layerQueue.isEmpty()){
List<SerPath> nodeList = layerQueue.poll(); //出队孩子表表头
for(SerPath childNode : nodeList){ //遍历当前孩子表,如果孩子节点也有孩子表,则将这个孩子节点的孩子表放入队尾等候遍历
System.out.println(childNode.getPath()); //读孩子数据
if(!childNode.childList.isEmpty()) { //如果孩子节点也有孩子表,则将这个孩子节点的孩子表放入队尾等候遍历
layerQueue.add(childNode.childList);
}
}
}
}
}
public static void main(String[] args) {
Forest forest = new Forest();
forest.readForest(forest.createForest());
}
}实际输出:

利用序列化保存再读取的测试:
package com.test.forest;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.LinkedBlockingQueue;
public class Forest {
/**构造测试样本**/
public List<SerPath> createForest() {
/**森林表**/
List<SerPath> forestTreeHeadList = new ArrayList<>();
/**第一棵树**/
SerPath treeHead1 = new SerPath(1);
treeHead1.childList.add(new SerPath(2));
treeHead1.childList.add(new SerPath(3));
treeHead1.childList.add(new SerPath(4));
treeHead1.childList.add(new SerPath(5));
treeHead1.childList.get(2).childList.add(new SerPath(6));
treeHead1.childList.get(2).childList.add(new SerPath(7));
treeHead1.childList.get(2).childList.add(new SerPath(8));
treeHead1.childList.get(2).childList.add(new SerPath(9));
forestTreeHeadList.add(treeHead1);
/**第2棵树**/
SerPath treeHead2 = new SerPath(10);
treeHead2.childList.add(new SerPath(11));
treeHead2.childList.add(new SerPath(12));
treeHead2.childList.add(new SerPath(13));
treeHead2.childList.get(0).childList.add(new SerPath(14));
treeHead2.childList.get(0).childList.add(new SerPath(15));
treeHead2.childList.get(0).childList.add(new SerPath(16));
treeHead2.childList.get(2).childList.add(new SerPath(17));
treeHead2.childList.get(2).childList.add(new SerPath(18));
forestTreeHeadList.add(treeHead2);
return forestTreeHeadList;
}
/**遍历森林中的所有树和树节点**/
public void readForest(List<SerPath> forestTreeHeadList) {
for(SerPath treeHead : forestTreeHeadList){
Queue<List<SerPath>> layerQueue = new LinkedBlockingQueue<>();
//输出头结点的值:
System.out.println(treeHead.getPath());
//发现头结点有孩子表,表入队:
if(!treeHead.childList.isEmpty()){
layerQueue.add(treeHead.childList);
}
//只要孩子表队列不为空就循环
while(!layerQueue.isEmpty()){
List<SerPath> nodeList = layerQueue.poll(); //出队孩子表表头
for(SerPath childNode : nodeList){ //遍历当前孩子表,如果孩子节点也有孩子表,则将这个孩子节点的孩子表放入队尾等候遍历
System.out.println(childNode.getPath()); //读孩子数据
if(!childNode.childList.isEmpty()) { //如果孩子节点也有孩子表,则将这个孩子节点的孩子表放入队尾等候遍历
layerQueue.add(childNode.childList);
}
}
}
}
}
/**前序遍历、深度优先遍历**/
public void readForestDepthFirst(List<SerPath> forestTreeHeadList){
if(forestTreeHeadList == null || forestTreeHeadList.isEmpty())
return;
for(SerPath path : forestTreeHeadList) {
System.out.println(path.getPath());
readForest(path.childList);
}
}
public static void main(String[] args) {
Forest forest = new Forest();
List<SerPath> forestTreeHeadList = forest.createForest();
//广度遍历:
forest.readForest(forestTreeHeadList);
System.out.println();
try {
File file = new File("E:\\1.temp");
if(!file.exists()){
file.createNewFile();
}
FileOutputStream outputStream = new FileOutputStream(file);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(forestTreeHeadList);
FileInputStream inputStream = new FileInputStream(file);
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
List<SerPath> reLoad = (List<SerPath>) objectInputStream.readObject();
//读取之后广度遍历第二次:
forest.readForest(reLoad);
//读取之后深度遍历:
System.out.println();
forest.readForestDepthFirst(reLoad);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
测试结果:
