一:前言
之前答应一个朋友介绍一下机器学习项目的基本流程,就以一个短文本分类项目为示例,介绍一下在面对机器学习项目时的基本解决思路,因为不是专业的算法工程师,所以有疏漏之处请大家多多见谅。同时由于这是一个内部比赛项目,所以数据无法公开,但是代码会分享在git上,代码写的也很一般,请大家多多理解。
二:题目
为了减少公司售后服务的人力投入,相关部门做了售后智能机器人,主要通过用户的问题得到他的意图所属类别,但是现有的方案对用户提问问题的类别识别准确率较低,需要研究更为优化的方案提升问题类别识别准确率。出题方提供的数据集如下,大概22w条训练数据,已知存在大量脏数据,问题和所属类别中间用\t分隔。

同时提供2w条预测数据,预测数据只有用户的问题,需要去预测这2w条数据所属的类别。
在本题中,评价标准是优先比较问题识别总的准确率,准确率相同比较类别24的召回率(查准率和查全率的加和平均)。三:解决思路
1.判断题目类别
机器学习项目有(分类/回归/聚类)三大类问题,分类就是训练集已知样本和对应的类别,然后去预测新的样本类别;回归就是相当于分类中的离散值类别变成连续值;聚类就是训练集中没有类别,需要通过聚类算法去找到对应类别。
本道题是一个典型的分类的问题,由于用户所提的问题都很短,所以是一个短文本分类问题,确定好问题之后,下面就是去搜集对应的资料了。
2.搜集资料
一般来说现有的问题学术界都已经给出了解决方案,所以可以通过关键词(短文本分类/Text Classfication)去搜索(百度/中国知网/Google Scholar),通过查阅资料可以知道解决短文本分类有以下几种常见的解决方案:
(1)通过TF-IDF算法生成每个短文本的特征向量,然后使用传统分类算法去训练模型,通过模型去预测新数据的类别。
(2)通过Word2Vec算法生成每个短文本的特征向量,然后使用CNN卷积神经网络进行模型训练,通过模型去预测新数据的类别。
(3)通过Word2Vec算法生成每个短文本的特征向量,然后使用CNN进行文本语义相似度分析,通过文本相似度判断所属类别。
3.确认方案
由于刚开始做的时候对该类型项目不熟悉,所以就采用了第一种最传统的做法,简单高效学习成本低。下面概述的就是基于第一种方案,该方案效果较优,但可拓展性差,后面会做详细说明。

4.数据探查
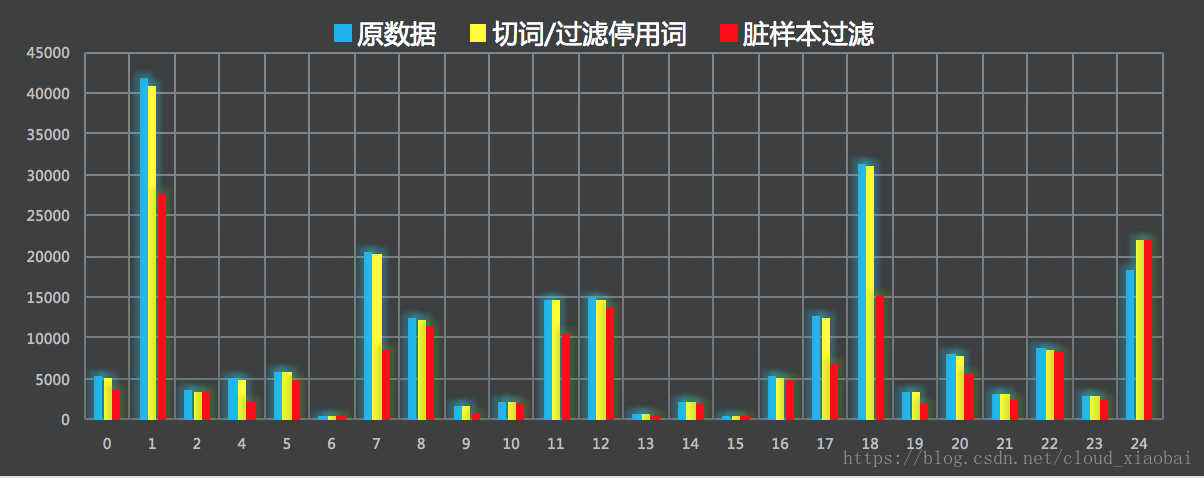
在实际项目中,样本分布不均匀和样本质量低下都是常见的问题,分布不均匀反映在不同类别的训练样本数量呈几十到上百倍的差距,样本质量低下反映的是大量样本类别标错/样本特征值缺失/样本特征值错误等问题。通过人工探查和数据分析得到如下的结论:

5.数据处理
数据处理有两方面工作:
(1)首先要使用分词工具对样本进行切词,并过滤掉停用词(停用词就是类似标点符号/转折词/语气词这些词汇,因为本方案采用的是TF-IDF方法,是基于词频逆文本的方案,所以不需要这些语气转折词),并针对过滤掉停用词为空的样本标记为“闲聊”类别。
(2)使用TF-IDF提取各类别的关键词,然后进行近义词拓展,得到每个类别的关键词,如果训练集中某类别的样本不包含对应的类别关键词,就将该样本过滤(因为用户提问的问题都是很直白的,比如酒店类型的问题中一般都会包含订房/退房/改签等,所以可以认为不包含对应类别的关键词但是属于该类别的样本就是脏样本,这种方式是基于规则的,通过该方式过滤了30%的脏样本,人工check之后发现效果过滤很好)。
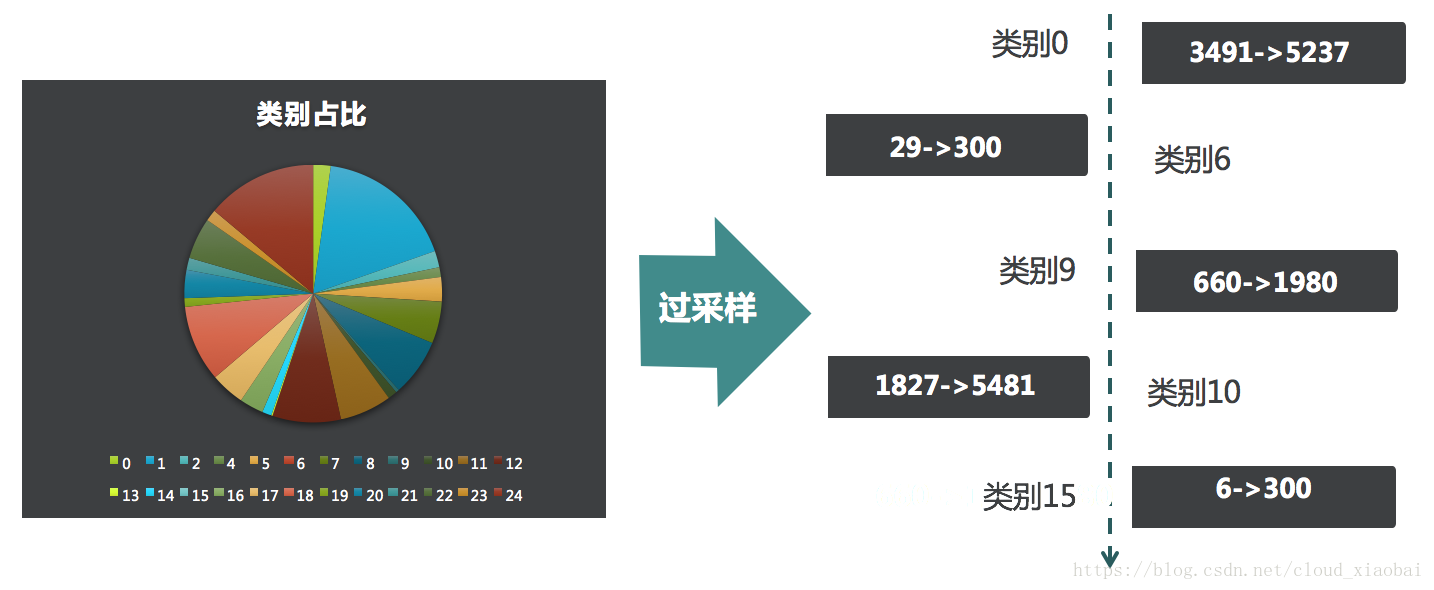
6.数据平衡
数据不平衡是机器学习项目中最常遇见的问题,容易造成过拟合,业界也有很多解决方案,本方案采用了最简单的随机过采样方式,针对实验预测效果不佳的类别进行过采样。
7.特征工程
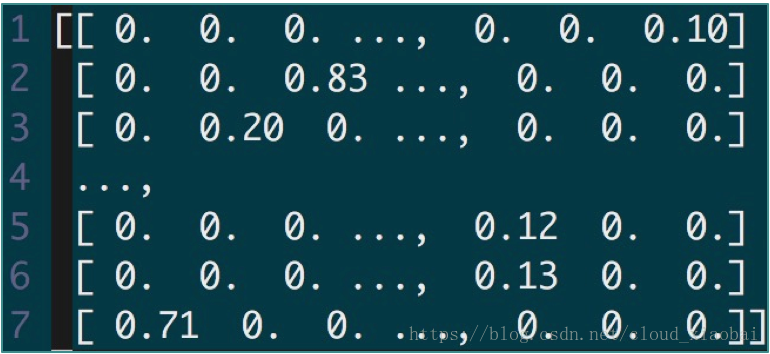
特征工程在正常的机器学习项目中属于最重要的一环,比如你有n个样本,那你要构造出m个特征(m范围一般几百到几千,以购物为例,用户过去1/2/3/4/5/6/7天的购买数就是7维特征了,这种项目就需要根据业务去构建合适的特征),这样一个n*m的矩阵就可以作为输入去训练模型了。由于本文是短文本分类的问题,直接使用TF-IDF通过字典构造特征的,并不需要人为干预,所以在这里特征工程就不是重点要说的了。使用TF-IDF为文本构造向量,维度设定为1w维,特征向量矩阵如下(因为维度太高,所以无法使用Smote算法进行过采样,也无法使用K-means进行样本过滤,所以建议还是使用Word2Vec生成几百维向量,方便拓展,但是毕竟这种方法好理解,作为练手完全可以)。
8.模型选择
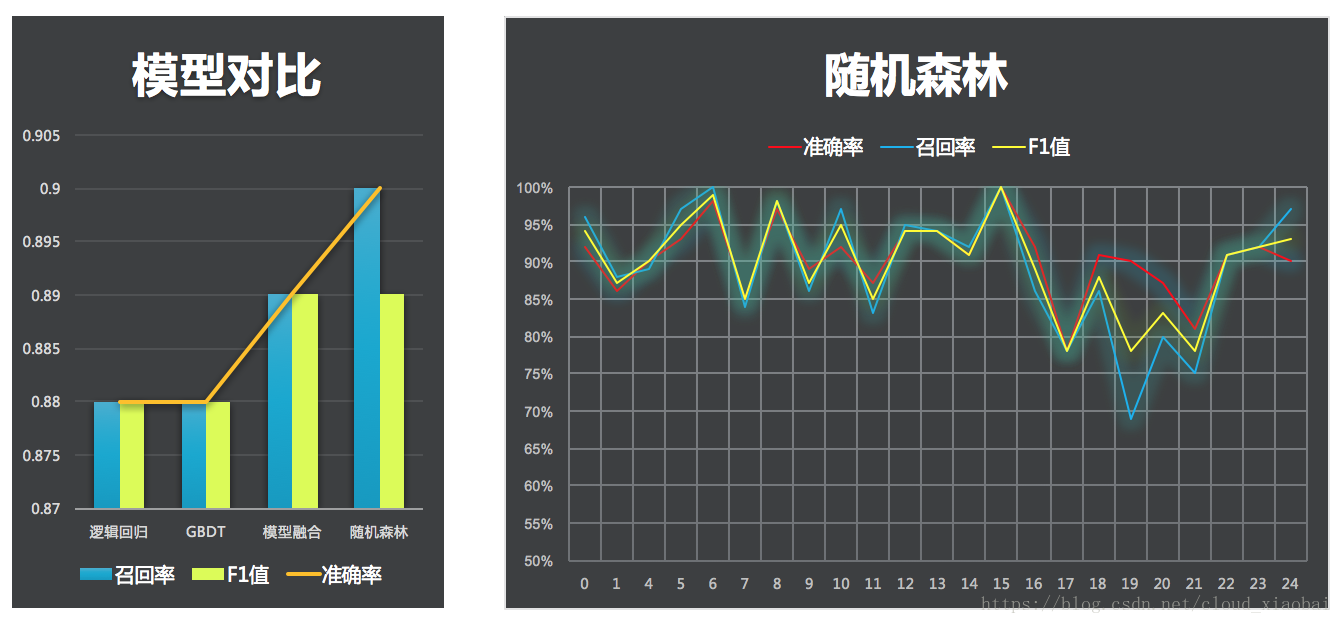
因为这是个分类问题,所以采用分类算法,业界常用逻辑回归/xgboost/gbdt/随机森林等,也可以将多个模型结果进行融合,模型融合有bagging/stacking/blending等方法,本文方案也尝试了模型融合,但是发现效果没有直接使用随机森林方法好,可能是参数没调好,最后因为时间原因还是采用速度快且效果明显的随机森林算法。下图分别表示各模型效果以及随机森林算法在各个子类别上的效果(在实验中发现某些样本数少的类别预测效果明显低于平均值,这个时候可以针对这些类别进行过采样或者单独预测)。
9.实验结果
最后预测测试集总体准确率高达百分之91%,类别24的f1值为0.98。

10.总结与反思
本文采用了传统的机器学习方法对短文本进行分类,容易理解且方便上手,但是采用TF-IDF算法生成的向量维度太高,无法进行有效拓展,如果采用Word2Vec方法,向量维度可以降低到几百维,这时可以使用k-means算法对样本进行聚类,对距离类别中心点较远的样本点进行过滤,同样可以采用Smote算法进行采样,有效的解决了脏样本过滤和类别不平衡的问题,降低了模型过拟合的风险。由于工作方向和时间的原因,没有进一步实现解决该问题的CNN方案。
四:代码地址
代码中敏感信息有删减,希望大家见谅,仅供参考
https://github.com/pengjiapeng/hackathon