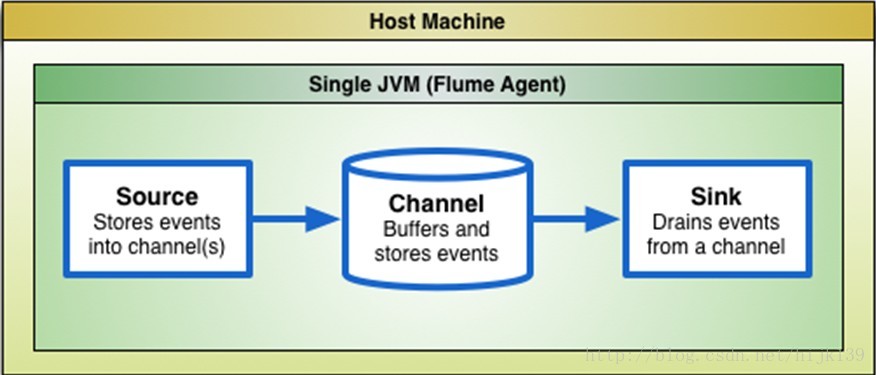
flume的整体基础架构包括三个,分别是source,chanel, sink. 下面是官网的截图:
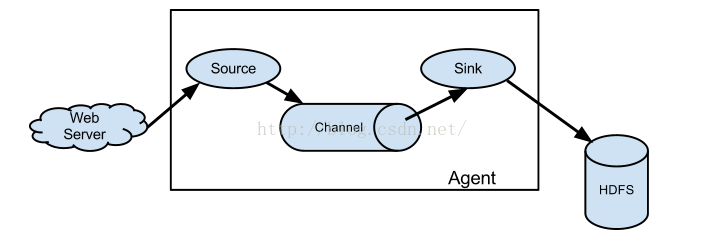
因此,优化要从三个组件的角度去分别优化。
1、source
sources是flume日志采集的起点,监控日志文件系统目录。其中最常用的是 Spooling Directory Source , Exec Source 和 Avro Source 。
关键参数讲解:
(1)batchSize: 这个参数当你采用的是 Exec Source 时,含义是一次读入channel的数据的行数,当你采用Spooling Directory Source含义是 Granularity(粒度) at which to batch transfer to the channel ,据我分析应该是events(flume最小处理数据单元)的数量。
这个参数一般 会设置比较大,一般的数值跟每秒要处理的数值相当。
(2)inputCharset 这个很重要,就是文本文件的编码,默认是flume按照utf-8处理,如果文本数据是gbk,则要增加此参数,
(3)interceptors flume自带的拦截器,可以根据正则表达式去过滤数据,但是据我实际经验总结,这个配置很影响入库性能,因此这部分工作我基本都在sink代码里面做。
2、channel
channel 是flume的中间数据缓存管道,有点类似kafka的机制,因此个组件的性能很重要。
我在项目中主要采用的是menmory channel,原因是数据量大,要求极大的数据吞吐量和速度,但是有一点不好的是
如果一旦flume进程down掉,是没有“续点传输”的机制的,filechannel 和它正好相反。
关键参数讲解:
(1) capacity : 存储在channel中的events的最大数量(2) transactionCapacity : 每次数据由channel到sink传输的最大events的数量
(3) byteCapacity :该channel的内存大小,单位是 byte 。

其中transactionCapacity关键中最容易忽略的,因为每个sink的终端不一样,批处理的数量要严格限制。还有一点,events的数量值和channel大小不是一回事,一个event包括单位数据的内容+头数据+数据传输状态。可以说 (events的数量值*单位数据所占字节数)* 0.9 = 所占空间内存数值(就是想说明transactionCapacity 的大小和byteCapacity 不能简答的数值比较 )。
3、sink
sink组件的核心工作是把channel中数据进行输出到特定的终端,比如hdfs,hbase,database,avro等等。
因此这块的核心优化工作在 优化各个终端(hdfs,hbase,database,avro)的数据插入性能。在这里面我只优化过hbase的数据插入性能(具体的做法就是打开flume hbasesink源码,修改然后打包),当然这块的工作不在flume本身,这也不是flume所能控制的。
4、整体架构
这三个组件当然顺序不能颠倒,但是每个组件的数量你可以自定义规定。 一个flume agent 就好比一个进程,一个source就好比进程里面的一个大组件,但是这里面注意的是每个sink 你又可以定义多个子线程,就是说一个flume agent进程可以多个sink,每个sink又可以多个线程(具体参数是 threadsPoolSize)。
5、 JAVA内存的设计
6 、 主要问题
这里面最恶心的问题是 三个组件互相传递数据速度不一致,这是要严格限制和摒除的,这也是flume的小难点之一吧。如果不一致,会严重影响采集整个系统的稳定性。当然这块我也在逐渐摸索,其他优化方面待续 ........................................