首先是关于flume的基础介绍
组件名称 |
功能介绍 |
Agent代理 |
使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
Client客户端 |
生产数据,运行在一个独立的线程。 |
Source源 |
从Client收集数据,传递给Channel。 |
Sink接收器 |
从Channel收集数据,进行相关操作,运行在一个独立线程。 |
Channel通道 |
连接 sources 和 sinks ,这个有点像一个队列。 |
Events事件 |
传输的基本数据负载。 |
目前来说flume是支持多种source
其中是支持读取jms消息队列消息,但是并不支持读取rabbitMq,所以需要对flume进行二次开发
这里主要就是flume怎么从rabbitMq读取数据
这里从git上找到了一个关于flume从rabbitMq读取数据的插件
上面有一些英文的描述,大家可以看下
环境介绍
centOS 7.3 jdk1.8 cdh5.14.0
1.用 mvn 打包该项目,会生成两个JAR包
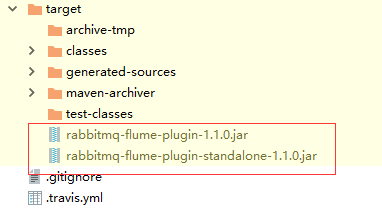
2.因为我这边使用的以cdh方式安装集成flume的,所以把这两个jar 扔到 /usr/lib 下面
如果是普通的安装方式需要把这两个jar包复制到 flume安装目录的lib下面

3.进入cdh管理页面配置Agent
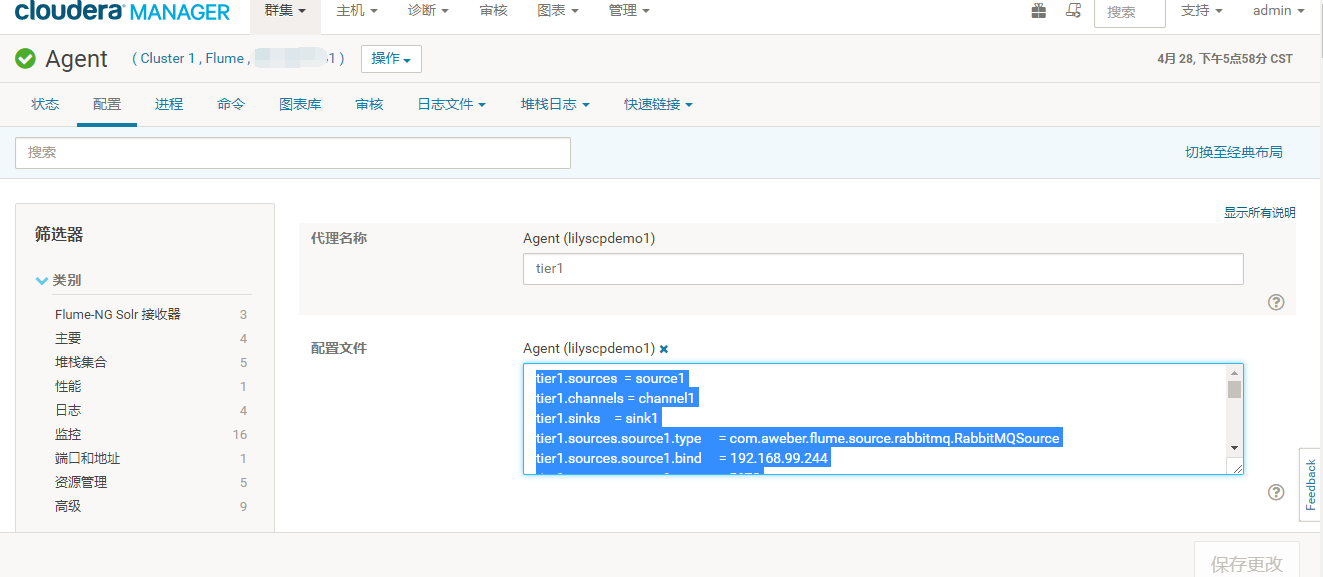
下面是详细的配置,我这边是直接把消息写入kafka集群里 的
tier1.sources = source1
tier1.channels = channel1
tier1.sinks = sink1
tier1.sources.source1.type = com.aweber.flume.source.rabbitmq.RabbitMQSource
tier1.sources.source1.bind = 127.0.0.1
tier1.sources.source1.port = 5672
tier1.sources.source1.virtual-host = /
tier1.sources.source1.username = guest
tier1.sources.source1.password = guest
tier1.sources.source1.queue = test
tier1.sources.source1.prefetchCount = 10
tier1.sources.source1.channels = channel1
tier1.sources.source1.threads = 2
tier1.sources.source1.interceptors = i1
tier1.sources.source1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
tier1.sources.source1.interceptors.i1.preserveExisting = true
tier1.channels.channel1.type = memory
tier1.sinks.sink1.channel = channel1
tier1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
tier1.sinks.sink1.topic = flume_out
tier1.sinks.sink1.brokerList = 127.0.0.1:9092,127.0.0.1:9093,27.0.0.1:9094
tier1.sinks.sink1.requiredAcks = 1
tier1.sinks.sink11.batchSize = 20
配置完成更新配置重新启动Agent

这个是接收到rabbitMq消息
