(未完)
3.1 例子3 添加层def add_layer()
为神经网络添加一个神经层
import tensorflow as tf
#添加一个神经层
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size,out_size])) #in_size代表行/输入层
biases = tf.Variable(tf.zeros([1,out_put]) + 0.1)
Wx_plus_b = tf.matmul(inputs,Weights) + biases #Wx_plus_b代表W*x+b
if activation_function is None: #如果没有激励函数,即为线性关系,那么直接输出,不需要激励函数(非线性函数)
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b) #把这个值传进去
return outputs 3.2 例子3 建造神经网络
构建一个简单的神经网络来预测y=x^2
import tensorflow as tf
import numpy as np
#添加一个神经层,定义添加神经层的函数
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size,out_size])) #in_size代表行/输入层
biases = tf.Variable(tf.zeros([1,out_put]) + 0.1)
Wx_plus_b = tf.matmul(inputs,Weights) + biases #Wx_plus_b代表W*x+b
if activation_function is None: #如果没有激励函数,即为线性关系,那么直接输出,不需要激励函数(非线性函数)
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b) #把这个值传进去
return outputs
x_data = np.linspace(-1, 1, 300, dtype = np.float32)[:, np.newaxis] #输入,np.float32改变数组的长度显示,linspace创建一个从-1到1的等差数列,默认为50个数,这里规定了要生成300个数,并且使用[:, np.newaxis]将数组转换为列向量,[np.newaxis,:]可转换为行向量
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32) #生成一个均值/中心为0,标准差/宽度为0.05的正太分布作为噪点/干扰点,它的格式为x_data,使得我们想要预测的函数更加接近实际情况;astype转换数据类型格式为float32
y_data = np.square(x_data) - 0.5 + noise #x的平方减去一个任意值再加上噪点
xs = tf.placeholder(tf.float32, [None, 1]) #占位符,保存数据的利器,float32数据类型,[None,1]表示列为1,行不定的列向量;xs表示x_Session,因为placeholder是与Session一起用的,它在使用的时候和前面的variable不同的是在session运行阶段,需要给placeholder提供数据,利用feed_dict的字典结构给placeholdr变量“喂数据”;placeholder的语法:tf.placeholder(dtype, shape=[None,None] [, name=None])
ys = tf.placeholder(tf.float32, [None, 1])
l1 = add_layer(xs, 1, 10, activation_function = tf.nn.relu) #创建一个隐藏层l1,输入为xs,输入的层数/神经元的个数1=输入层,输出的层数10=隐藏层中神经元的个数
prediction = add_layer(l1, 10, 1, activation_function = None) #预测值;定义输出层,输入为l1=前一层隐藏层的输出,输入的层数为10=隐藏层神经元的个数,输出的层数为1=输出一般只有1层
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices = [1])) #计算预测值prediction与真实值ys的误差:所有的平方差相加再求平均;reduction_indices = [1]表示相加的方法,[1]表示行求和,[0]表示列求和,具体解释见下文
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #机器要学习的内容,使用优化器提升准确率,学习率为0.1<1,表示以0.1的效率来最小化误差loss
init = tf.global_variable_initializer() #使用变量,就要对其初始化
sess = Session() #定义Session,并使用Session来初始化步骤
sess.run(init)
for i in range(1000): #训练1000次
sess.run(train_step, feed_dict={xs:x_data, ys:y_data}) #给placeholder喂数据,把x_data赋值给xs
if 1 % 50 == 0: #每50步输出一次机器学习的误差
print(sess.run(loss, feed_dict=={xs:x_data, ys:y_data})) 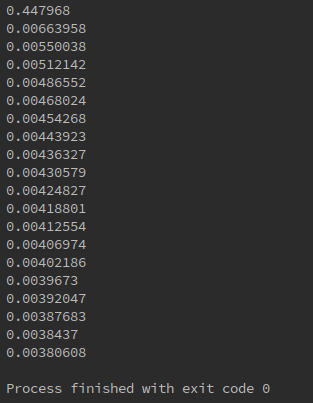
可见,误差越来越小。
关于reduce_sum()函数:
在tensorflow中使用加法函数,同时需要reduction_indices=[1, 0],[1]表示行求和,[0]表示列求和。
下图中[3, 3]竖起来显示是为了说明reduction_indices这个过程中维度的信息是一直保留的,所以它并不是一个列向量,所以它不是[ [3], [3] ],它本质还是[3, 3],所以说无论是行求和还是列求和最后输出都被转换成行向量。

转自知乎用户:凡心 reduction_indices的解释