脚 本 概 述
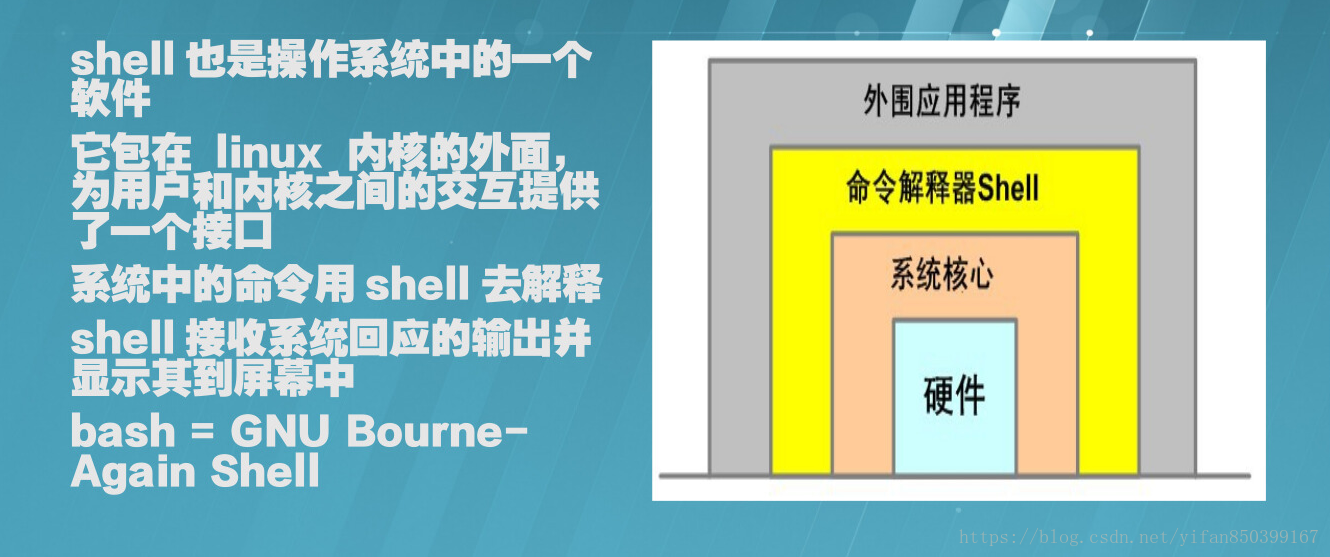
脚本是批处理文件的延伸,是一种纯文本保存的程序,一般来说的计算机脚本程序是确定的一系列控制计算机进行运算操作动作的组合,在其中可以实现一定的逻辑分支等。
脚本简单地说就是一条条的文字命令,这些文字命令是可以看到的(如可以用记事本打开查看、编辑),脚本程序在执行时,是由系统的一个解释器,将其一条条的翻译成机器可识别的指令,并按程序顺序执行。因为脚本在执行时多了一道翻译的过程,所以它比二进制程序执行效率要稍低一些。
脚本通常可以由应用程序临时调用并执行。各类脚本被广泛地应用于网页设计中,因为脚本不仅可以减小网页的规模和提高网页浏览速度,而且可以丰富网页的表现,如动画、声音等。举个最常见的例子,当点击网页上的Email地址时能自动调用Outlook Express或Foxmail这类邮箱软件,就是通过脚本功能来实现的。也正因为脚本的这些特点,往往被一些别有用心的人所利用。例如在脚本中加入一些破坏计算机系统的命令,这样当用户浏览网页时,一旦调用这类脚本,便会使用户的系统受到攻击。所以用户应根据对所访问网页的信任程度选择安全等级,特别是对于那些本身内容就非法的网页,更不要轻易允许使用脚本。通过”安全设置”对话框,选择”脚本”选项下的各种设置就可以轻松实现对脚本的禁用和启用。

脚本格式
(1)一般以#!/bin/bash 开头(幻数)
#!/bin/sh是指此脚本使用/bin/bash来解释执行,#!是特殊的表示符,其后面根的是此解释此脚本的shell的路径。其实第一句的#!是对脚本的解释器程序路径,脚本的内容是由解释器解释的,我们可以用各种各样的解释器来写对应的脚本。比如说/bin/csh脚本,/bin/perl脚本,/bin/awk脚本,/bin/sed脚本,甚至/bin/echo等等。#!/bin/sh同理
以.sh结尾时,编辑语言没有语法高亮。
(2)一般以.sh文件命名
当以.sh文件命名时,在编辑文本文件时会有语法高亮提示。
(3)脚本内一般要注释
脚本名称:文件名称
创建人:创建人
创建日期:格式为YYYY/MM/DD
功能:脚本完成功能概述
运行前要求:运行前的要打开的窗口及状态要求、数据库中的数据的要求、被测试程序运行的目录等等。
··········
(4)一般用“sh 脚本文件”来运行脚本
#在本篇文章后面会有几个小练习来举例几个简单的脚本运行,读者可以继续向后阅读一起来看看!
一、脚本文件自动添加注释
为了书写方便,我们可以在/etc/vimrc 文件中添加注释内容,这样每当我们要写一个新的脚本是就会自动添加注释内容。
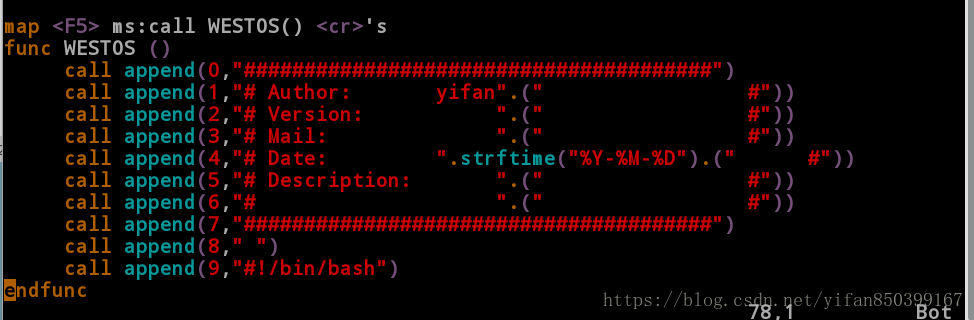
方法一:设置指定的键去自动添加注释内容
[root@client ~]# vim /etc/vimrc
------->在文件后面添加<-----
map <F5> ms:call WESTOS()<cr>'s
func WESTOS ()
call append(0,"#######################################")
call append(1,"# Author: yifan".(" #"))
call append(2,"# Version: ".(" #"))
call append(3,"# Mail: ".(" #"))
call append(4,"# Date: ".strftime("%Y-%M-%D").(" #"))
call append(5,"# Description: ".(" #"))
call append(6,"# ".(" #"))
call append(7,"#######################################")
call append(8," ")
call append(9,"#!/bin/bash")
endfunc
[root@client ~]# chmod +x /etc/vimrc #添加可执行权限
[root@client ~]# vim /mnt/hello.sh #此时在编辑文件时按F5会自动出现以下内容
#######################################
# Author: yifan #
# Version: #
# Mail: #
# Date: 2018-30-06/09/18 #
# Description: #
# #
#######################################
#!/bin/bash

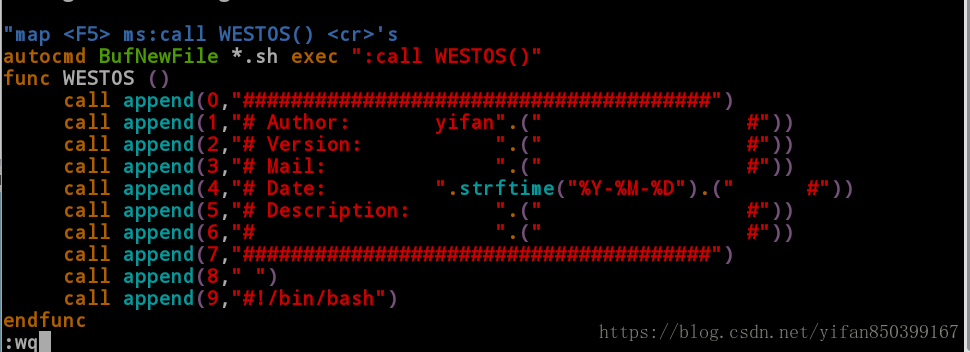
方法二:新文件打开自动添加注释内容
[root@client ~]# vim /etc/vimrc
------->在文件后面添加<-----
autocmd BufNewFile *.sh exec ":call WESTOS()"
#在编辑以.sh新文件时会自动出现,旧文件不会出现。
“ map <F4> ms:call WESTOS()<cr>'s #注释掉,注意这里用双引号注释。
func WESTOS ()
call append(0,"#######################################")
call append(1,"# Author: yifan".(" #"))
call append(2,"# Version: ".(" #"))
call append(3,"# Mail: ".(" #"))
call append(4,"# Date: ".strftime("%Y-%M-%D").(" #"))
call append(5,"# Description: ".(" #"))
call append(6,"# ".(" #"))
call append(7,"#######################################")
call append(8," ")
call append(9,"#!/bin/bash")
endfunc
[root@client ~]# vim /mnt/westos.sh #此时在编辑文件时会自动出现以下内容
#######################################
# Author: yifan #
# Version: #
# Mail: #
# Date: 2018-30-06/09/18 #
# Description: #
# #
#######################################
#!/bin/bash
二、diff命令的使用
1.格式:
diff <变动前文件> <变动后文件>
Diff有三种格式:
a 添加(addition)
c 改变(change)
d 删除(deletion)
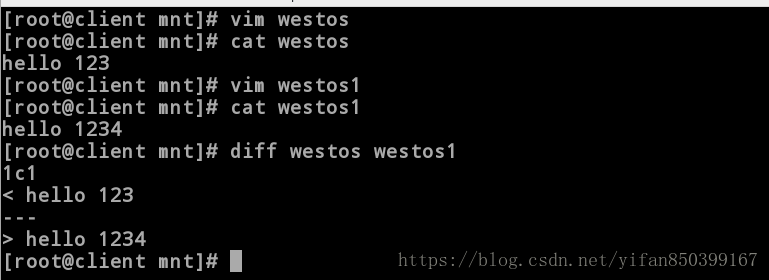
示例一、比较westos和westos1。
[root@client mnt]# cat westos
hello 123
[root@client mnt]# cat westos1
hello 1234
[root@client mnt]# diff westos westos1
1c1
< hello 123
---
> hello 12341.第一行是一个提示,用来说明变动位置,分为三个部分:
(1)前面的“1”表示westos的第一行有变化.
(2)中间的“c”表示变动模式为内容改变.
(3)后面的”1“表示变动后变成westos1的第一行。
2.第二行分为两个部分:
(1)前面的”<”表示要从westos中改变这一行,
(2)后面的hello 123表示这行内容。
3.第三行用来分割westos和westos1
4.第四行类似域第二行
前面的“>”号表示westos1增加了这一行,即修改策略,让westos和westos1相同,可以修改westos的第一行为hello 1234。
示例二、比较westos和westos1。
[root@client mnt]# cat westos1
hello 123
[root@client mnt]# cat westos
hello 123
linux
[root@client mnt]# diff westos westos1
2d1
< linux#修改策略,让westos和westos1相同,可以在westos的第二行删除linux。
示例三、比较westos1和westos。
[root@client mnt]# cat westos1
hello 123
[root@client mnt]# cat westos
hello 123
linux
[root@client mnt]# diff westos1 westos
1a2
> linux#修改策略,让westos1和westos相同,可以在westos1的第二行添加linux。
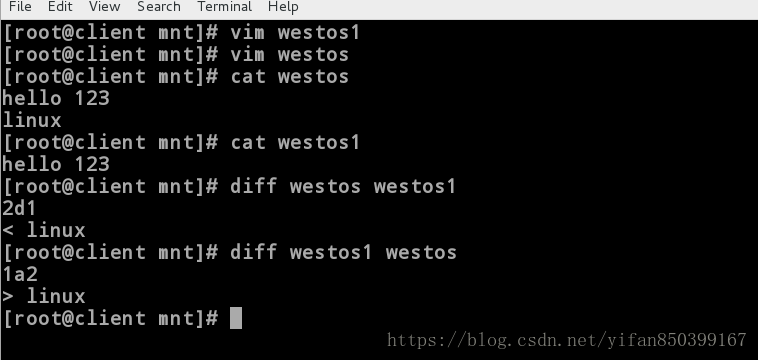
#大家可以比较以下二、三实验,对比一些一下diff后面跟的文件顺序时的不同修改策略,会发现diff对比的准则时按照使第一个文件和第二个文件相同来实现的。
2.利用patch(补丁)修改文件
(1)生成补丁文件
[root@client mnt]# cat westos1
hello 123
[root@client mnt]# cat westos
hello 123
linux #修改westos文件与westos1不同
[root@client mnt]# diff -u westos westos1 #比较westos与westos1并生成补丁。
--- westos 2018-06-09 22:45:17.519300323 -0400
+++ westos1 2018-06-09 22:46:07.711300323 -0400
@@ -1,2 +1 @@
hello 123
-linux
[root@client mnt]# diff -u westos westos1 > westos.patch #将补丁输入到westos.patch文件中。
[root@client mnt]# cat westos.patch
--- westos 2018-06-09 22:45:17.519300323 -0400
+++ westos1 2018-06-09 22:46:07.711300323 -0400
@@ -1,2 +1 @@
hello 123
-linux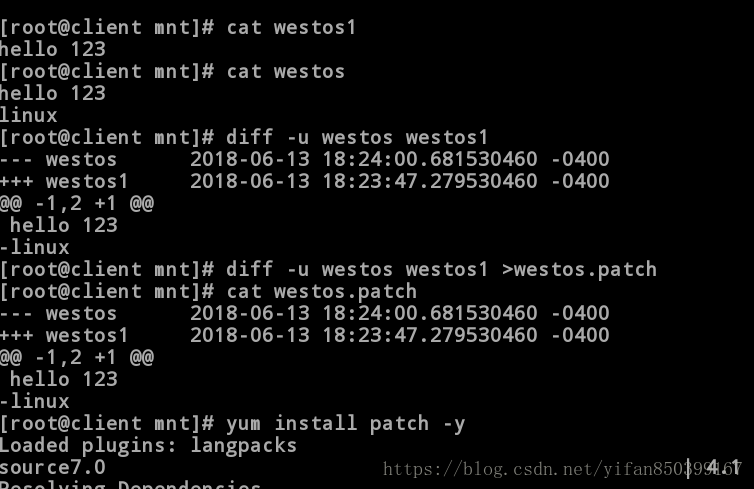
(2)下载补丁软件进行修补
[root@client mnt]# yum install patch -y #下载patch(补丁)
Loaded plugins: langpacks
rhel_dvd | 4.1 kB 00:00
Resolving Dependencies
--> Running transaction check
[root@client mnt]# patch westos westos.patch #通过补丁文件修补westos文件,使其和westos1文件相同。
patching file westos
[root@client mnt]# cat westos
hello 123
[root@client mnt]# cat westos1
hello 123 #此时两者相同。
[root@client mnt]# ls
westos westos1 westos.patch #但之前的westos文件已经消失,下面我们可以通过“patch -b”来保留原文件并修改
[root@client mnt]# vim westos
[root@client mnt]# cat westos
hello 123
linux
[root@client mnt]# cat westos1
hello 123
[root@client mnt]# diff -u westos westos1 >westos.patch
[root@client mnt]# ls
westos westos1 westos.patch
[root@client mnt]# patch -b westos westos.patch
patching file westos
[root@client mnt]# cat westos
hello 123
[root@client mnt]# ls
westos westos1 westos.orig westos.patch #此时westos.orig为原文件内容。
[root@client mnt]# cat westos.orig
hello 123
linux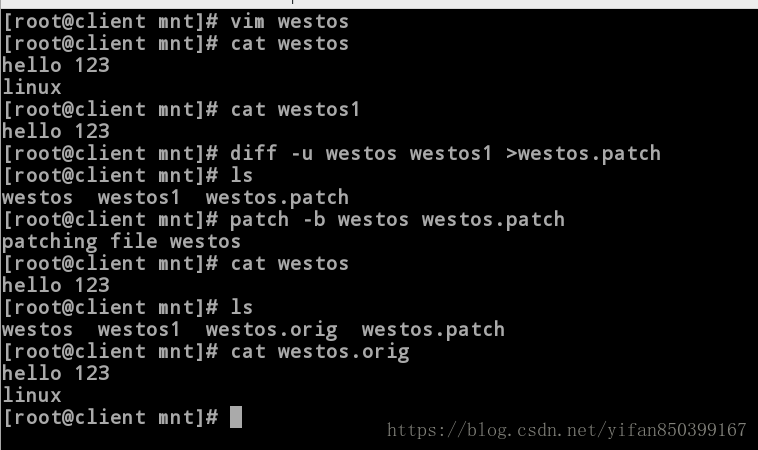
Diff除了比较两个文件,也可以用来比较两个目录,此时用diff -r <目录1> <目录2> 来实现,非常简单,读者可以尝试一下。
三、CUT 命令的简单使用
1.格式:
cut 命令多用于字符截取
cut -d #指定分隔符
cut -f 1,7 | 1-7 | 3- #指定截取的列,以分隔符分开为一列“1,7”指第一列与第七列,“1-7”指第一列到第七列,“3-”指第三列以后的列。
cut -c 1,7 | 1-7 # 指定截取字符数位置,即字符单个为一列。
示例
为了做实验,我将/etc/passwd复制一份到当前目录,并删除掉一些内容,留下一些用来演示。
(1)cut -d : -f 1 passwd #截取以分隔符“:”为界的第一列数据。
[root@client mnt]# cp /etc/passwd .
[root@client mnt]# vim passwd
[root@client mnt]# cat passwd
radvd:x:75:75:radvd user:/:/sbin/nologin
pulse:x:171:171:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
gdm:x:42:42::/var/lib/gdm:/sbin/nologin
gnome-initial-setup:x:993:991::/run/gnome-initial-setup/:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
dhcpd:x:177:177:DHCP server:/:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
[root@client mnt]# cut -d : -f 1 passwd #截取以分隔符“:”为界的第一列数据。
radvd
pulse
gdm
gnome-initial-setup
tcpdump
dhcpd
apache
mysql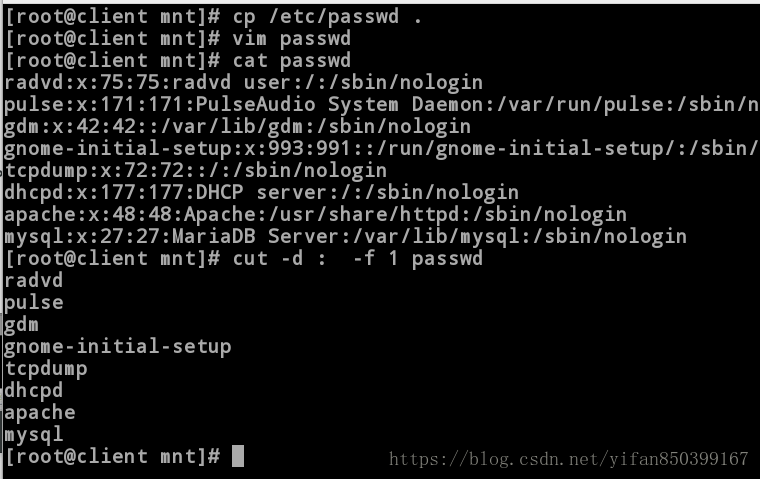
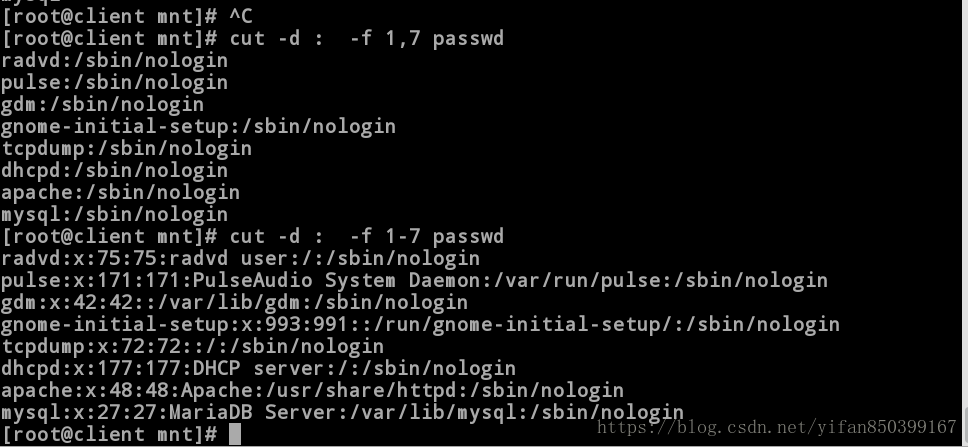
(2)cut -d : -f 1,7 passwd #截取以分隔符“:”为界的第一列与第七列数据。
[root@client mnt]# cut -d : -f 1,7 passwd #截取以分隔符“:”为界的第一列与第七列数据。
radvd:/sbin/nologin
pulse:/sbin/nologin
gdm:/sbin/nologin
gnome-initial-setup:/sbin/nologin
tcpdump:/sbin/nologin
dhcpd:/sbin/nologin
apache:/sbin/nologin
mysql:/sbin/nologin
[root@client mnt]# cut -d : -f 1-7 passwd #截取以分隔符“:”为界的第一列到第七列数据。
radvd:x:75:75:radvd user:/:/sbin/nologin
pulse:x:171:171:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
gdm:x:42:42::/var/lib/gdm:/sbin/nologin
gnome-initial-setup:x:993:991::/run/gnome-initial-setup/:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
dhcpd:x:177:177:DHCP server:/:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
(3)cut -c 1,7 passwd #截取第一个与第七个字符。
[root@client mnt]# cut -c 1,7 passwd #截取第一个与第七个字符。
rx
px
g4
gi
tp
dx
a:
mx
[root@client mnt]# cut -c 1-7 passwd #截取第一个到第七个字符。
radvd:x
pulse:x
gdm:x:4
gnome-i
tcpdump
dhcpd:x
apache:
mysql:x

练习一:脚本练习,结合cut命令,写一个脚本——ip_show,当执行此脚本时,只显示当前主机的ip。
思路:先显示主机eth0网卡的ip,根据分析可以先过滤出“inet “,从“inet “开始,以空格为分隔符,显示第十列内容,即为ip。
方法一:
[root@client mnt]# cat ip_show.sh
######################################
# Author: yifan #
# Version: #
# Mail: #
# Date: 2018-13-06/13/18 #
# Description: #
# #
######################################
#!/bin/bash
ifconfig eth0 | grep "inet " | cut -d " " -f 10 
方法二:
[root@client mnt]# cat ip_show.sh
######################################
# Author: yifan #
# Version: #
# Mail: #
# Date: 2018-13-06/13/18 #
# Description: #
# #
#######################################
#!/bin/bash
ifconfig eth0 | awk -F " " 'inet\>/{print $2}'
[root@client mnt]# sh ip_show.sh
172.25.254.226
##awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理,读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,0则表示所有域,1表示第一个域,$n表示第n个域,这里指以“inet”且不加以扩展为初始域,读取其后第二个域的内容。
四、&& 和 || 命令的简单使用
&& 用来执行条件成立后执行的命令
|| 用来执行条件不成立后执行的命令
例如:ping -c1 -w1 172.25.254.111 && echo up
ping -c1 -w1 172.25.254.111 || echo up
##c1表示只发送一个icmp echo_r equest包,-w表示只等待一秒。如果ping通则显示up ,否则显示down,若我们不想显示ping的结果,则可以使用“ping -c1 -w1 172.25.254.111 &>/dev/null && echo up” 将其导入到垃圾桶中。
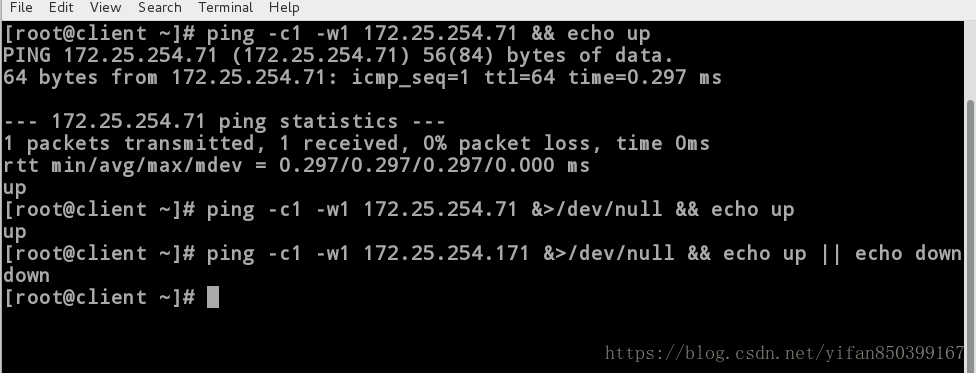
练习二:写一个脚本“check_ip.sh”,当主机的ip可以ping通时显示up,否则显示down。
[root@client ~]# vim check_ip.sh
[root@client ~]# cat check_ip.sh
#######################################
# Author: yifan #
# Version: #
# Mail: #
# Date: 2018-20-06/14/18 #
# Description: #
# #
#######################################
#!/bin/bash
ping -c1 -w1 $1 &> /dev/null && echo $1 is up || echo $1 is down
[root@client ~]# sh check_ip.sh 172.25.254.71
172.25.254.71 is up
[root@client ~]# sh check_ip.sh 172.25.254.171
172.25.254.171 is down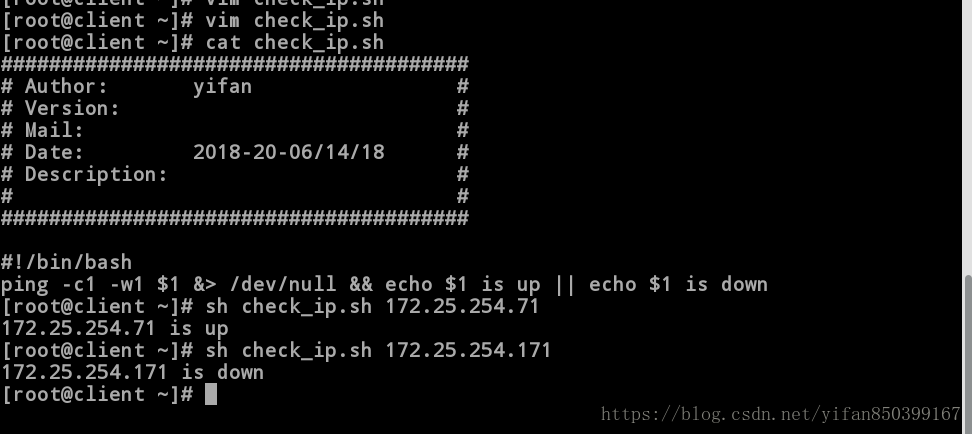
五、sort命令的使用
Sort(多用于字符排序)
| Sort | |
|---|---|
| sort -n | 纯数字排序 |
| sort -u | 去掉重复数字 |
| sort -r | 倒序 |
| sort -o | 输出到指定文件中 |
| sort -t | 指定分隔符 |
| sort -k | 指定要排序的列 |
具体举例:
[root@client mnt]# cat westos
12
45
8
5
6
7
7
8
3
[root@client mnt]# sort -r westos #倒序,默认只按照第一列数字进行排序。
8
8
7
7
6
5
45
3
12
[root@client mnt]# sort -n westos #纯数字排序,按照从大到小。
3
5
6
7
7
8
8
12
45
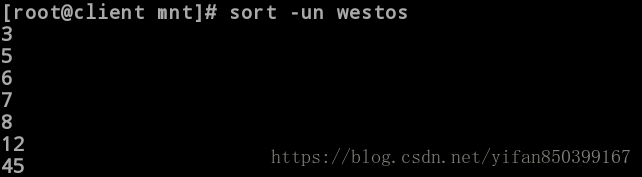
[root@client mnt]# sort -un westos #去掉重复数字排序,此时数字7,8只剩下一个。
3
5
6
7
8
12
45
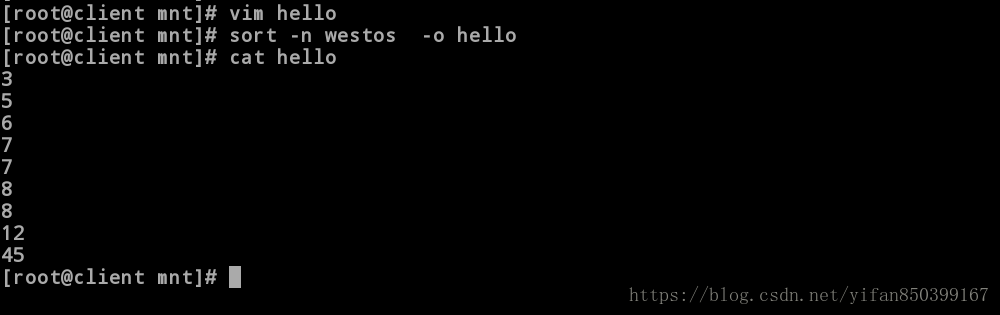
[root@client mnt]# vim hello #新建一个hello文件。
[root@client mnt]# sort -n westos -o hello #将westos内数字按照纯数字排序导入到hello文件中。
[root@client mnt]# cat hello
3
5
6
7
7
8
8
12
45
[root@client mnt]# vim westos #以“:”为分隔符,在westos中再添加一列数字。
[root@client mnt]# cat westos
12:2
45:6
8:5
5:24
6:2
7:98
7:7
8:11
3:32
[root@client mnt]# sort -t : -k 2 -nr westos
#“-t”指定“:”为分隔符,“-k”指定为第二列,“-nr”按照纯数字倒序的方法对westos文件中第二列数字进行排序。
7:98
3:32
5:24
8:11
7:7
45:6
8:5
6:2
12:2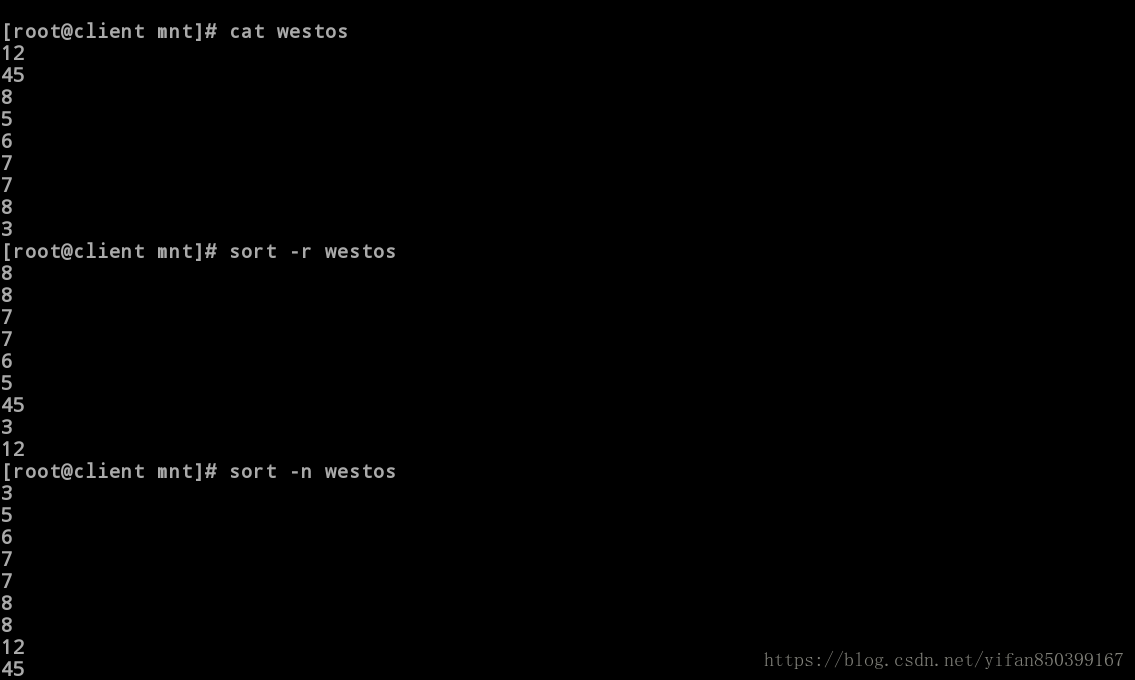

六、unique、命令的简单使用
uniq对重复字符做相应的处理
| uniq | |
|---|---|
| uniq -u | 显示唯一的行 |
| uniq -d | 显示重复的行 |
| uniq -c | 每行显示一次并统计重复次数 |
具体举列:
[root@client mnt]# vim westos
[root@client mnt]# cat westos
1
2
3
5
3
2
4
5
6
2
[root@client mnt]# sort -n westos | uniq -c #前面一行显示的为数字出现的次数
1 1
3 2
2 3
1 4
2 5
1 6
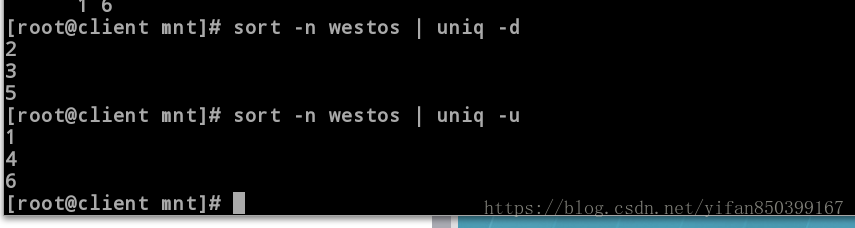
[root@client mnt]# sort -n westos | uniq -d #显示有重复的行
2
3
5
[root@client mnt]# sort -n westos | uniq -u #显示唯一的行
1
4
6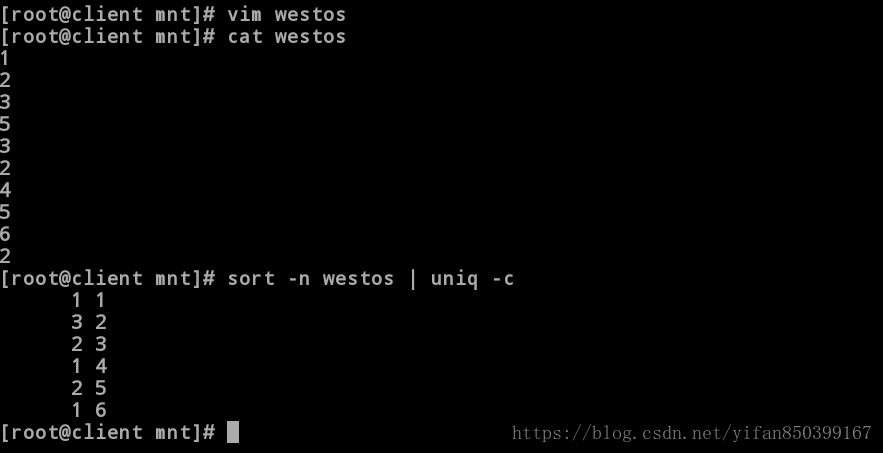
练习三:写一个脚本“check_file.sh’’,运行时后加目录名,可以显示目录内最大文件。
思路解析:
[root@client mnt]# ls -l /mnt/ #1.查看/mnt目录下文件的属性
total 8
-rw-r--r-- 1 root root 20 Jun 19 04:32 hello
-rw-r--r-- 1 root root 20 Jun 19 04:44 westos
[root@client mnt]# ls -l /mnt/ | grep total -v #2.显示除掉含有total的行
-rw-r--r-- 1 root root 20 Jun 19 04:32 hello
-rw-r--r-- 1 root root 20 Jun 19 04:44 westos
[root@client mnt]# ls -l /mnt/ | grep total -v|awk -F " " '//{print $5,$9}'
#3.以空格为分隔符,显示第五列和第九列。
20 hello
20 westos
[root@client mnt]# ls -l /mnt/ | grep total -v|awk -F " " '//{print $5,$9}'|sort -nr
#4.对现在的第一列进行排序。
20 westos
20 hello
[root@client mnt]# ls -l /mnt/ | grep total -v|awk -F " " '//{print $5,$9}'|sort -nr | head -n 1
#5.排序后显示第一行。
20 westos
[root@client mnt]# ls -l /mnt/ | grep total -v|awk -F " " '//{print $5,$9}'|sort -nr | head -n 1|cut -d " " -f 2
#6.最后显示第而列文件的名称。
Westos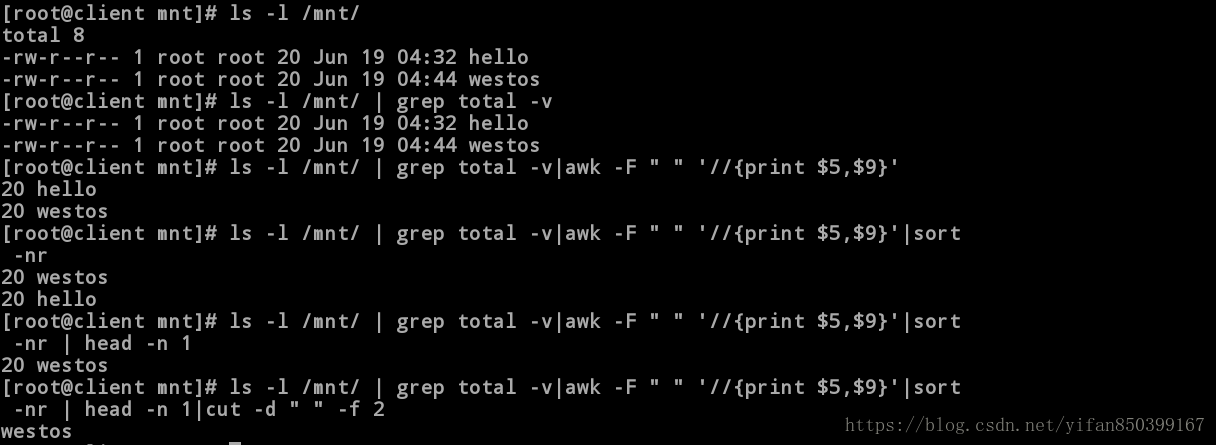
脚本书写:
[root@client mnt]# cat check_file.sh
#########################
# Author: yifan #
# Version: #
# Mail: #
# Date: 2018-05-06/19/18 #
# Description: #
# #
########################
#!/bin/bash
ls -l /$1/ | grep total -v|awk -F " " '//{print $5,$9}'|sort -nr | head -n 1|cut -d " " -f 2
[root@client mnt]# sh check_file.sh /mnt
check_file.sh
[root@client mnt]# sh check_file.sh /etc/
services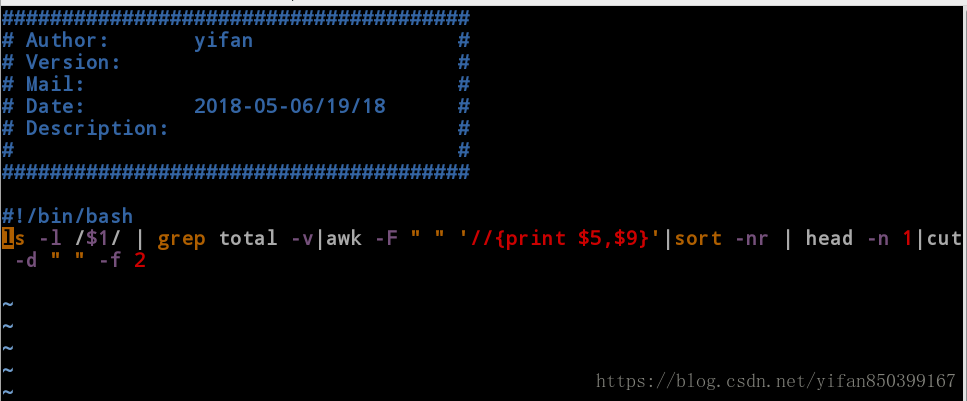
七、test命令的简单使用
一、对于数字的一般比较用法:
Test 命令和“[ ]”等同,Test “ B” 等同 [ “ B” ]
| Test | |
|---|---|
| [ “ B” ] | 判断A是否不等于B |
| [ “ B” ] | 判断A是否等于B |
| [ “ B” ] | 判断A是否不等于B |
| [ “ B”] | 判断A是否小于等于B |
| [ “ B” ] | 判断A是否小于B |
| [ “ B” ] | 判断A是否大于等于B |
| [ “ B” ] | 判断A是否大于B |
| [ “ B” -a “ C” ] | 判断A不等于B且A大于C,两个条件均满足 |
| [ “ B” -o “ C” ] | 判断A不等于B或A大于C,两个条件至少满足一个就好 |
| [ -z “$A” ] | 判断A是否为空 |
| [ -n “$A” ] | #判断A是否不为空 |
具体举例:
[root@client mnt]# a=1
[root@client mnt]# b=2
[root@client mnt]# test "$a" = "$b" && echo yes || echo no #注意“=”的两边必须加空格!!!
no
[root@client mnt]# b=1
[root@client mnt]# test "$a" = "$b" && echo yes || echo no
yes
[root@client mnt]# echo $c
[root@client mnt]# [ -z "$c" ] && echo yes || echo no #判断c变量是否为空,注意“[ ]”的两边必须加空格!!!
yes
[root@client mnt]# c=1
[root@client mnt]# [ -z "$c" ] && echo yes || echo no
no
二、对于文件的一般比较用法:
| Test | |
|---|---|
| [ “file1” -ef “file2” ] ] | 文件一与文件二具有相同的设备并具有相同的节点号 |
| [ “file1” -nt “file2” ] | 文件一比文件二新建立 |
| [ “file1” -ot “file2” ] | 文件一比文件而建立的早 |
具体举例:
[root@client mnt]# ls
[root@client mnt]# touch file1
[root@client mnt]# touch file2
[root@client mnt]# [ "file1" -ot "file2" ] && echo yes || echo no #文件一建立的时间比文件二长。
yes
[root@client mnt]# [ "file1" -nt "file2" ] && echo yes || echo no #文件2比文件1建立时间段。
no
[root@client mnt]# ln /mnt/file1 /mnt/file3 #给文件1生成一个链接文件3。
[root@client mnt]# ls
file1 file2 file3
[root@client mnt]# [ "file1" -ef "file3" ] && echo yes || echo no #两者有相同的节点号。
yes
| Test [-$1 test] | |
|---|---|
| -b FILE(块设备) | FILE exists and is block special |
| -e FILE(文件是否存在] | FILE exists |
| -f FILE(普通文件) | FILE exists and is a regular file |
| -L FILE (软连接) | FILE exists and is a symbolic link |
| -S FILE (套接字) | FILE exists and is a socket |
| -d FILE(目录)) | FILE exists and is a directory |
| -c FILE (字符设备) | FILE exists and is character special |
练习四:写一个脚本,判断文件的类型。
思路解析:
1.先判断脚本后是否有输入,若无则提示输入。
2.判断文件是否存在。
3.依次判断文件类型。
#判断文件类型。
#!/bin/bash
[ -z "$1" ] && {
echo "please input a file after script!!"
exit 1
}
[ -e "$1" ] || {
echo ""$1" is not exist !"
exit 0
}
[ -f "$1" ] && {
echo ""$1" is a regular file"
exit 0
}
[ -S "$1" ] && {
echo ""$1" is a socket "
exit 0
}
[ -d "$1" ] && {
echo ""$1" is a directory "
exit 0
}
[ -L "$1" ] && {
echo ""$1" is a symbolic link "
exit 0
}
[ -c "$1" ] && {
echo ""$1" is a character special "
exit 0
}
[ -b "$1" ] && {
echo ""$1" is a block specivial "
} || {
echo " Sorry,I don't know !"
}

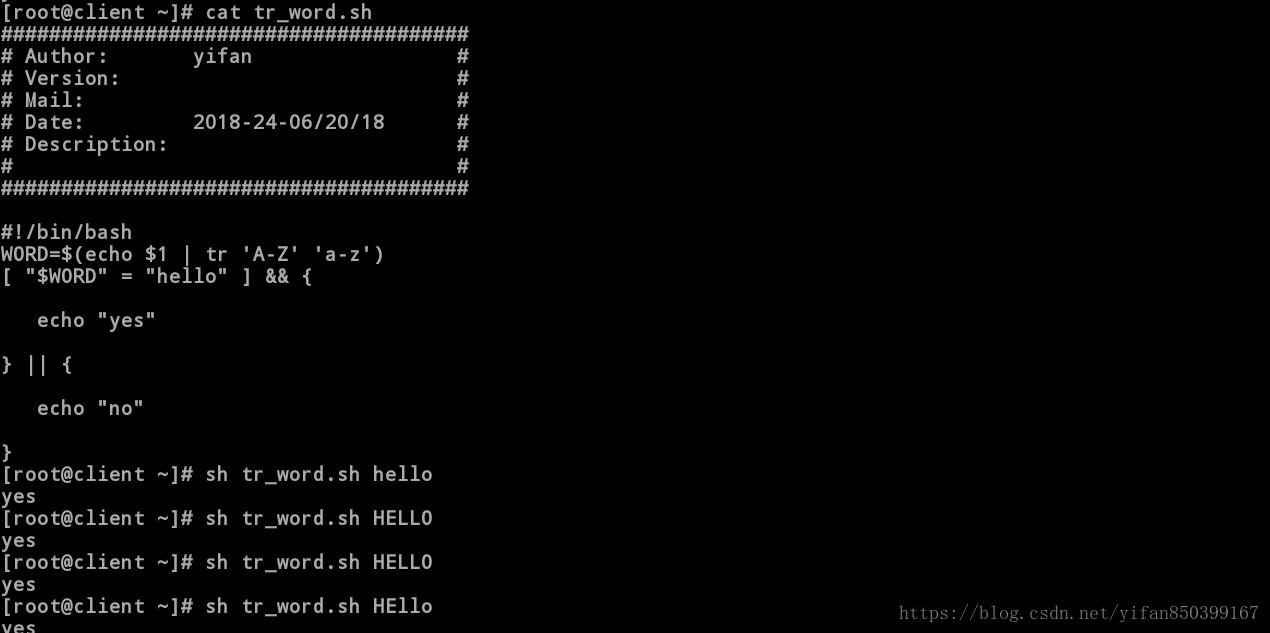
练习五:写一个脚本,输入大小写字母的hello时显示yes,否则显示no。
#!/bin/bash
WORD=$(echo $1 | tr 'A-Z' 'a-z')
##在执行语句前执行WORD=$(echo $1 | tr 'A-Z' 'a-z'),使用户输入的大写字母全部转换为小写字母。
[ "$WORD" = "hello" ] && {
echo "yes"
} || {
echo "no"
}