1.diff命令
1. diff 命令是用来比较两个文件或目录的不同
2. 格式:diff [options] target1 target2
3. diff file1 file2比较两个文件的不同之处
4. diff direcory1 directory2比较两个目录的不同之处
diff 命令是用来比较两个文件或目录的不同,并且是以行为单位来比对的,
一般是用在 **ASCII 纯文本文件的比对上**。由于是==以行为比对的单位==,
因此 diff 通常是用在==同一文件(或软件)的新旧版本差异上对比上==,
能够借由 diff 创建的分析档,以处理补丁(patch)功能的文件
注:重点:
diff命令是比较不同,以行为单位,一般用于同一文件(或软件)的新旧版本差异上对比上
加粗样式
(1)diff在比较文件
[num1,num2][a|c|d][num3,num4]
num1,num2 表示在第一个文件中的行数
num3,num4 表示在第二个文件中的行数
| a | 表示添加 |
|---|---|
| c | 表示修改 |
| d | 表示删除 |
| < | 表示第一个文件的内容 |
| > | 表示第二个文件的内容 |
实例:
file1中的内容:
123
haha
file2中的内容:
123
nihao
diff file1 file2
运行结果:
2c2 #第一个文件的第二行修改才能匹配第二个文件的第二行
< haha> nihao
cat file1
123
cat file2
123
nihao
diff file1 file2 #以file2为例,file1必须增加一行,才能变为file2
diff file2 file1
运行结果:
1a2
> nihao
2d1
< nihao
(2)diff比较目录
Only in directroy/:这个目录有filename这个文件
directory 表示在这个目录中
filename 表示在这个目录的文件
(3)常用的diff命令的参数
| 参数 | 描述 |
|---|---|
| -b 或 --ignore-space-change | 不检查空格字符的不同 |
| -B 或 --ignore-blank-lines | 不检查空白行 |
| -c | 显示全部内容,并标出不同之处 |
| -i 或 --ignore-case | 不检查大小写的不同 |
| -p | 若比较的文件为 C 语言的程序码文件时,显示差异所在的函数名称 |
| -q 或 --brief | 仅显示有无差异,不显示详细的信息 |
| -r 或 --recursive | 仅比较子目录中的文件 |
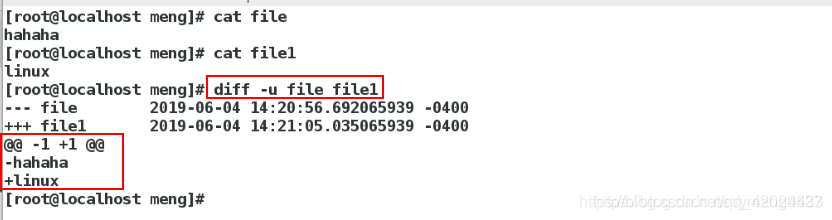
| -u | 合并显示两个文件的不同 |



-b 或 --ignore-space-change 不检查空格字符的不同

-B 或 --ignore-blank-lines 不检查空白行

-c 显示全部内容,并标出不同之处

-i 或 --ignore-case 不检查大小写的不同

-p :若比较的文件为 C 语言的程序码文件时,显示差异所在的函数名称;


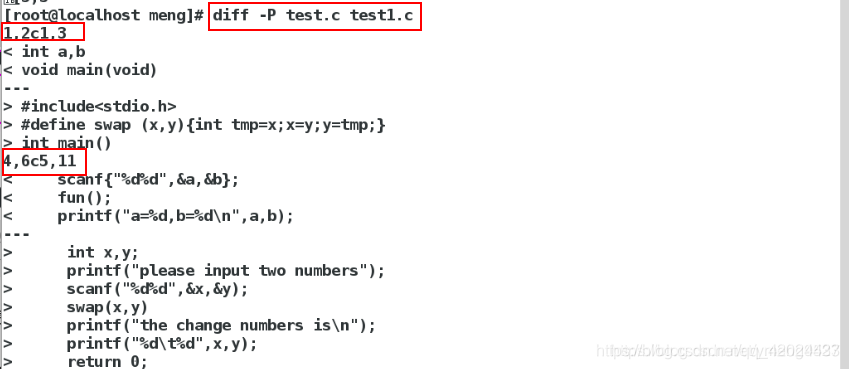

-q 或 --brief :仅显示有无差异,不显示详细的信息

-r 或 --recursive :比较子目录中的文件
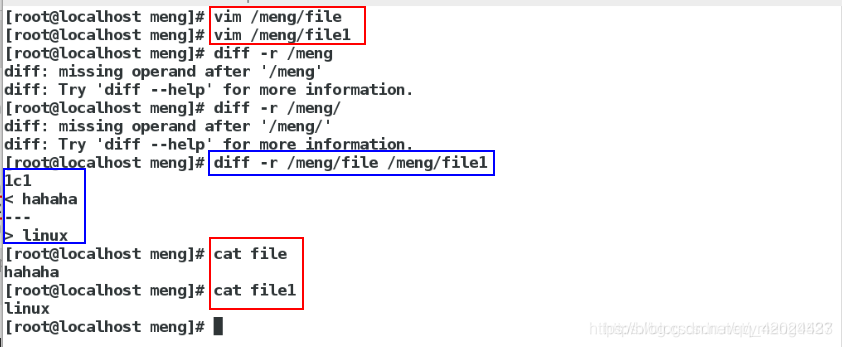
-u 以合并的方式来显示文件内容的不同
2.patch命令
(1)基本描述
Linux patch命令用于修补文件,用于文件不同文件打布丁,这个指令常与 diff 配合使用,diff 可以用来分辨两个版本之间的差异
我们将旧的文件升级成为新的文件时,应该要怎么做?
就是“先比较新旧版本的差异,并将差异档制作成为补丁文件,再由补丁文件更新旧文件“即可,也就是我们俗称的打补丁
patch指令让用户利用设置修补文件的方式,修改,更新原始文件。倘若一次仅修改一个文件,可直接在指令列中下达指令依序执行
如果配合修补文件的方式则能一次修补大批文件,这也是Linux系统核心的升级方法之一
-b或–backup:备份每一个原始文件。在修补文件时,重命名或复制原始文件,而不是删除它
-p :后面可以接“取消几层目录”的意思。
-R :代表还原,将新的文件还原成原来旧的版本
用于不同文件打补丁
命令格式
patch [options] file.old(旧文件) file.path(补丁文件)使用补丁文件来完善旧文件
(2)实例
yum install patch -y ##安装打补丁的软件
diff -u test1 test2 > test.patch ##生成补丁文件 test.patch
patch -b test1 test.patch ##修补文件test1

注:利用patch -b 来备份原始数据,通过补丁文件(haha.patch)来更新haha1文件,此时生成的haha1和haha2相同,但是原始文件(haha1.org)文件的内容还是原始的数据
3.cut命令(多用于字符截取)
(1)常用的参数
| -c | 指定截取字符的位置 |
|---|---|
| -d | 指定分隔符 |
| -f | 指定要截取的列 |
(2)实例
cp /etc/passwd .
vim passwd
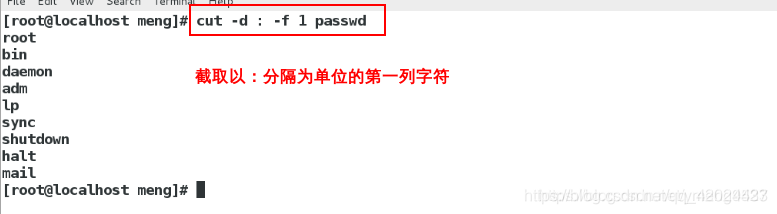
指定分隔符:-d 指定截取的列:-f
cut -d : -f 1 passwd
cut -d : -f 1,3 passwd ##截取第1和第3列
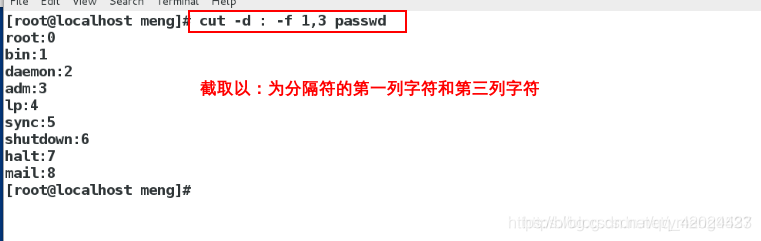
cut - d : -f 1-3 passwd
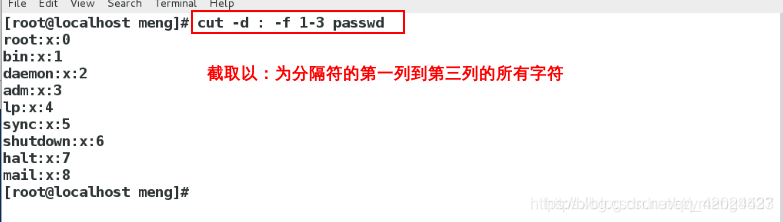
cut -c(位置) 2-4(2到4) passwd ##;截取第二到第四个的字符
cut -c 2-4 passwd
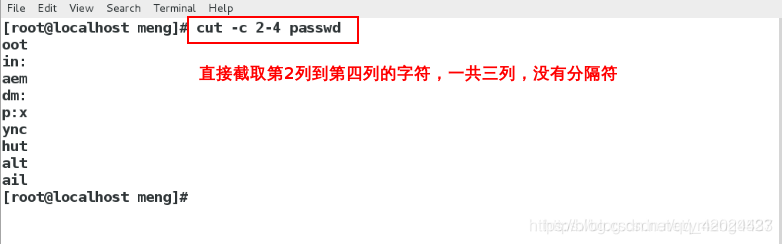
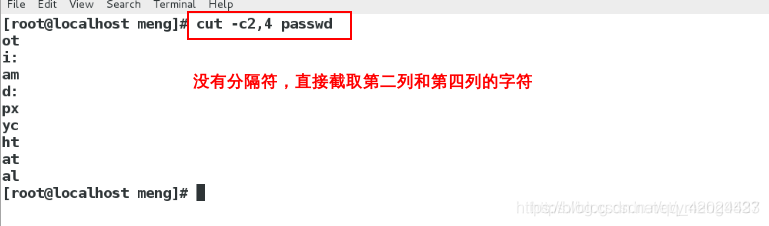
cut -c2,4 passwd
4.sort命令(通常排序)
(1)常用参数
| -n | 纯数字排序 |
|---|---|
| -r | 倒序 |
| -u | 去掉重复数字 |
| -o | 输出到指定的文件 |
| -t | 指定分隔符 |
| -k | 指定要排序的列 |
(2)实例
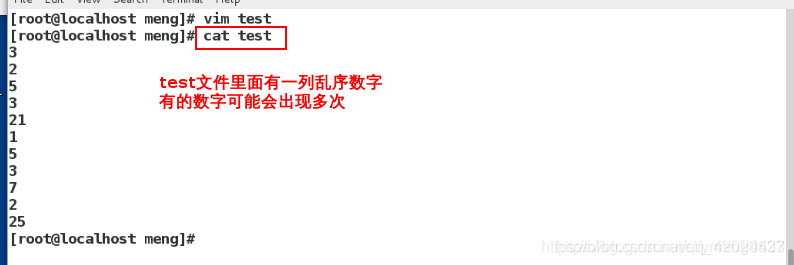
vim test
sort test
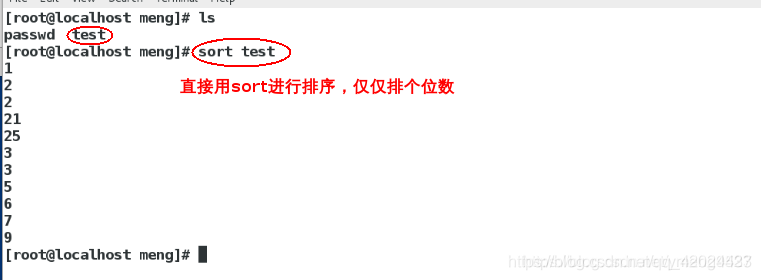
注:该排序是先对第一列 进行排序。然后在排序第二例
##纯数字排序
sort -n test
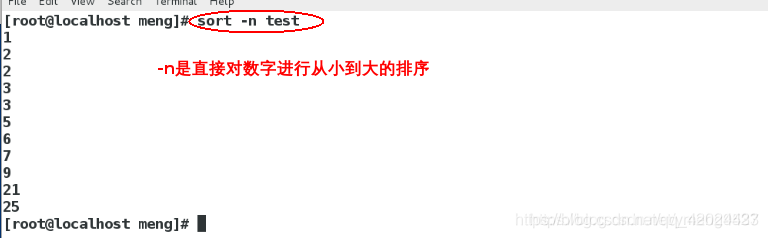
sort -nr test ##对数字进行倒序输出
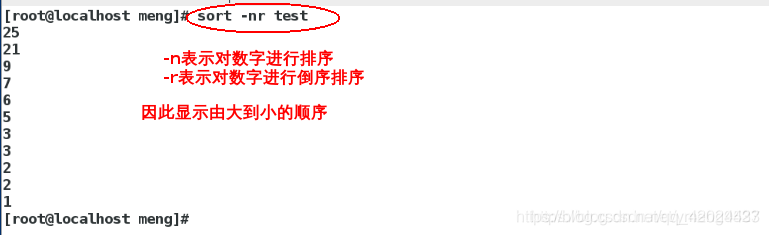
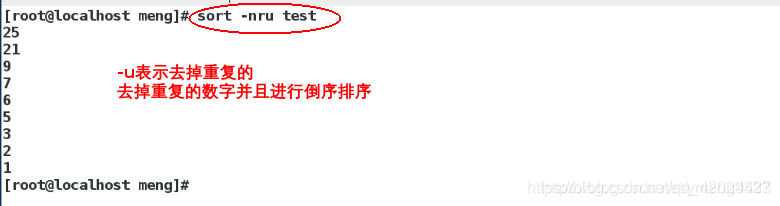
#去掉重复的数字,再次倒序输出
sort -nru test
#输出指定的文件
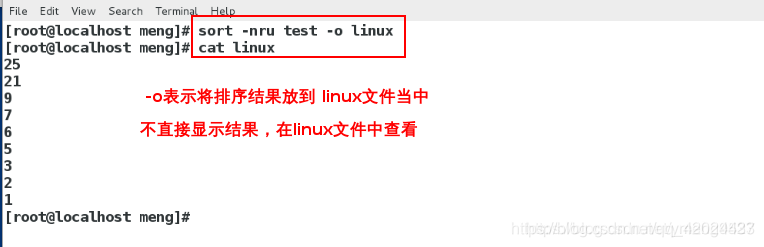
sort -nru test -o linux
#指定分隔符
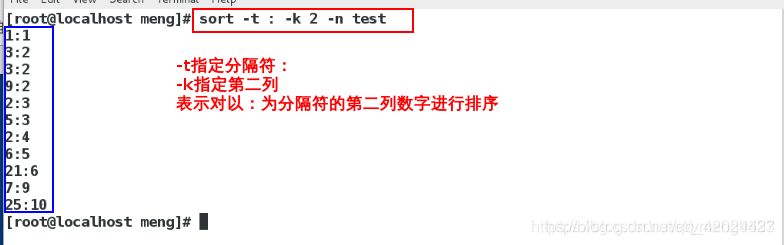
sort -t : -k 2 -n test
5.unqi命令(处理重复的字符做出相应的处理)
(1)常用参数
| -u | 显示唯一的行 |
|---|---|
| -d | 显示重复的行 |
| -c | 每行显示一次并统计行数 |
sort -n test | uniq -c #显示出现的次数,以及排序

sort -n test | uniq -u ##去掉重复的行

sort -n test | uniq -d ##显示重复的行

6 seq语句
(1)基本描述
seq 主要是输出序列化的东西
用法:seq [option ] 首数 增量 尾数
以指定增量从首数开始打印到尾数
(2)常用的参数
| -s | 使用指定的分隔符分割数字,默认\n |
|---|---|
| -w | 在列前补0 ,使得宽度相同【自动补位】 |
| -f | 使用 printf 样式的浮点格式 |
(3)实例
seq 5
seq -s '@' 5
seq -2 2 10
输出结果:
1 2 3 4 5
1@2@3@4@5
-2 0 2 4 6 8 10
seq -w 10
seq -f "03g" 98 101
输出结果:
01
02
03
04
05
06
07
08
09
10
098
100
101
7 tr语句:translate的简写,只能翻译单个字符,不能翻译句子
(1)常用变量
| -c | 用集合1中的字符串转换 |
|---|---|
| -d | 删除集合1中的字符而不是转化 |
| -s | 删除所有重复出现字符序列,只保留第一个 |
| -t | 先删除第一个集合比第二个字符多出来的字符串 |
(2)实例:




echo "1234"|tr '0-9' '9876543210'
结果:8765
echo "hello 123 nihao 567 " |tr -d '0-9'
