本篇学习笔记以HTTP、FTP、P2P叙述与网上下载文件有关的协议
需要掌握的要点:
- 下载一个文件可以使用 HTTP 或 FTP,这两种都是集中下载的方式,而 P2P 则换了一种思路,采取非中心化下载的方式
- P2P 也是有两种,一种是依赖于 tracker 的,也即元数据集中,文件数据分散;另一种是基于分布式的哈希算法,元数据和文件数据全部分散
HTTP与FTP
首先简述HTTP下载和FTP下载的区别:
我们先要知道,使用Web浏览器时,这两个协议之间的差异几乎不会对使用的方便性及下载时间产生影响。不过,两者却拥有各自不同的结构。
HTTP下载
- HTTP是一种为了将位于全球各个地方的Web服务器中的内容发送给不特定多数用户而制订的协议。也就是说,可以把HTTP看作是旨在向不特定多数的用户“发放”文件的协议。
- HTTP使用于从服务器读取Web页面内容。Web浏览器下载Web服务器中的HTML文件及图像文件等,并临时保存在个人电脑硬盘及内存中以供显示。
- 使用HTTP下载软件等内容时的不同之处只是在于是否以Web浏览器显示的方式保存,还是以不显示的方式保存而已。结构则完全相同。因此,只要指定文件,任何人都可以进行下载。
FTP下载
FTP即文件传输协议
FTP 采用两个 TCP 连接来传输一个文件。
- 控制连接:服务器以被动的方式,打开众所周知用于 FTP 的端口 21,客户端则主动发起连接。该连接将命令从客户端传给服务器,并传回服务器的应答。常用的命令有:list——获取文件目录;reter——取一个文件;store——存一个文件。
- 数据连接:每当一个文件在客户端与服务器之间传输时,就创建一个数据连接。
另一方面,FTP是为了在特定主机之间“传输”文件而开发的协议。因此,在FTP通信的起始阶段,必须运行通过用户ID和密码确认通信对方的认证程序,
FTP下载和HTTP下载的区别之一就在与此。
FTP 的两种工作模式:
每传输一个文件,都要建立一个全新的数据连接。FTP 有两种工作模式,分别是主动模式(PORT)和被动模式(PASV),这些都是站在 FTP 服务器的角度来说的。
P2P
无论是 HTTP 的方式,还是 FTP 的方式,都有一个比较大的缺点,就是难以解决单一服务器的带宽压力, 因为它们使用的都是传统的客户端服务器的方式。
后来,一种创新的、称为 P2P 的方式流行起来。P2P就是peer-to-peer。资源开始并不集中地存储在某些设备上,而是分散地存储在多台设备上。这些设备我们姑且称为 peer。
P2P定义
- Peer-to-peer 是一类允许一组用户互相连接并直接从用户硬盘上获取文件的网络
- Peer-to-peer网络是一个运行于个人电脑上的应用,通过网络在用户间分享文件。P2P网络通过连接个人电脑分享文件而不是通过中央服务器
- P2P是一种分布式网络,网络的参与者共享他们所拥有的一部分硬件资源(处理能力、存储能力、网络连接能力、打印机等),这些共享资源需要由网络提供服务和内容,能被其它对等节点(peer)直接访问而无需经过中间实体。在此网络中的参与者既是资源(服务和内容)提供者(server),又是资源(服务和内容)获取者(client)
P2P特点
- 无中央服务器,打破了C/S模式
- 用户之间互联并分享文件。
P2P分类
- 提供文件和其他内容共享的P2P网络,如Napster、Gnutella、eDonkey、emule、BitTorrent等;
- 挖掘P2P对等计算能力和存储共享能力,如SETI@home、Avaki、Popular Power等;
- 基于P2P方式的协同处理与服务共享平台,如JXTA、Magi、Groove、.NET My Service等;
- 即时通讯交流,包括ICQ、QICQ、Yahoo Messenger等;
- 安全的P2P通讯与信息共享,如Skype、Crowds、Onion Routing等。
BitTorrent
想要下载一个文件的时候,你只要得到那些已经存在了文件的 peer,并和这些 peer 之间,建立点对点的连接,而不需要到中心服务器上,就可以就近下载文件。
一旦下载了文件,你也就成为 peer 中的一员,你旁边的那些机器,也可能会选择从你这里下载文件,所以当你使用 P2P 软件的时候,例如 BitTorrent,往往能够看到,既有下载流量,也有上传的流量,也即你自己也加入了这个 P2P 的网络,自己从别人那里下载,同时也提供给其他人下载。
可以想象,这种方式,参与的人越多,下载速度越快,一切完美。
种子(.torrent)文件
但是有一个问题,当你想下载一个文件的时候,怎么知道哪些 peer 有这个文件呢? 这就用到种子啦,也即咱们比较熟悉的.torrent 文件。.torrent 文件由两部分组成,分别是:announce(tracker URL)和文件信息。(tracker谷歌翻译为跟踪器)
文件信息里面有这些内容:
- info 区:这里指定的是该种子有几个文件、文件有多长、目录结构,以及目录和文件的名字
- Name 字段:指定顶层目录名字
- 每个段的大小:BitTorrent(简称 BT)协议把一个文件分成很多个小段,然后分段下载
- 段哈希值:将整个种子中,每个段的 SHA-1 哈希值拼在一起
工作过程:
- 下载时,BT 客户端首先解析.torrent 文件,得到 tracker 地址,然后连接 tracker 服务器。
- tracker 服务器回应下载者的请求,将其他下载者(包括发布者)的 IP 提供给下载者。
- 下载者再连接其他下载者,根据.torrent 文件,两者分别对方告知自己已经有的块,然后交换对方没有的数据。
此时不需要其他服务器参与,并分散了单个线路上的数据流量,因此减轻了服务器的负担。
这个过程也可以看出,这种方式特别依赖 tracker。tracker 需要收集下载者信息的服务器,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。
虽然下载的过程是非中心化的,但是加入这个 P2P 网络的时候,都需要借助 tracker 中心服务器,这个服务器是用来登记有哪些用户在请求哪些资源。
所以,这种工作方式有一个弊端,一旦 tracker 服务器出现故障或者线路遭到屏蔽,BT 工具就无法正常工作了。
去中心化网络(DHT)
为了向彻底去中心化迈步前进,后来就有了一种叫作DHT(Distributed Hash Table)的去中心化网络。
每个加入这个 DHT 网络的人,都要负责存储这个网络里的资源信息和其他成员的联系信息,相当于所有人一起构成了一个庞大的分布式存储数据库。
有一种著名的 DHT 协议,叫Kademlia 协议。这个和区块链的概念一样,很抽象。
任何一个 BitTorrent 启动之后,它都有两个角色。一个是peer,监听一个 TCP 端口,用来上传和下载文件,这个角色表明,我这里有某个文件。另一个角色DHT node,监听一个 UDP 的端口,通过这个角色,这个节点加入了一个 DHT 的网络。
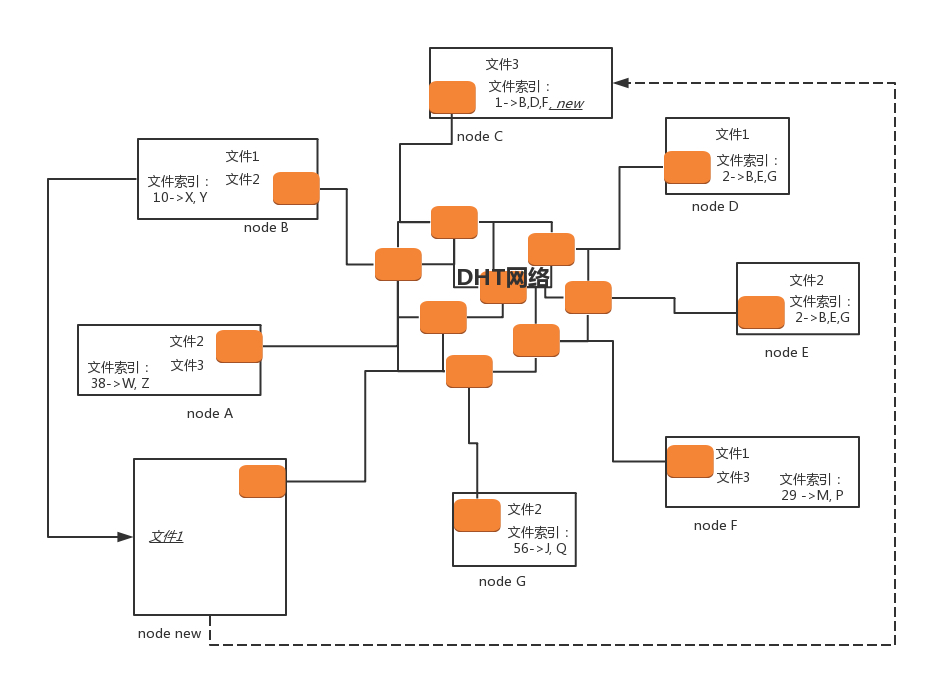
在 DHT 网络里面,每一个 DHT node 都有一个 ID。这个 ID 是一个很长的串。每个 DHT node 都有责任掌握一些知识,也就是文件索引,也即它应该知道某些文件是保存在哪些节点上。
它只需要有这些知识就可以了,而它自己本身不一定就是保存这个文件的节点。