P2P下载器
一、P2P下载器功能简介
P2P下载器是一个可以跨Windows和Linux平台的点对点下载器项目,客户端通过搜索出局域网中的在线主机,向指定主机发送建立连接请求,获取主机共享文件列表,发送文件下载请求,服务端对客户端的请求做出响应,最终实现不同主机间共享文件的目的。
客户端:
1.查看网络中的共享主机,向网络中广播配对请求,得到相应在线主机列表
2.选择一个主机获取文件列表,向指定主机发送获取列表请求
3.基于线程池,将文件的所有数据下载进行分块传输。
客户端的主要接口:
Client
{
//获取在线主机,向所有IP地址发送配对请求,判断是否在线
public:
void HostPiar(uint32_t ip) //直接向主机发送配对请求,判断是否在线
bool GetOnlineHost() //获取网卡信息,得到每个主机的IP地址
bool GetShareList(uint32_t)//获取指定主机的共享文件列表,打印出来供用户选择
bool Download(uint32_t ip,const std::string &filename);
private:
std::vector<uint32_t> _online_host_list; //保存所有在线主机IP信息
}
服务端:
1、网络通信模块:基于HTTP协议实现http服务器的搭建,实现客户端主机匹配、列表获取、文件下载的功能
2、文件操作模块:基于boost库中文件操作,实现指定目录下的文件信息迭代获取,以及文件的基本读写操作
服务端的主要接口:
//服务端模块
Server
{
//1、搭建http服务器,对http请求进行业务处理作出相应 --使用第三方库httplib实现
//2、针对客户端的功能请求进行业务处理接口的实现即可
void HostPair()//针对客户端主机配对请求做出正确响应
void ShareList()//针对客户端的获取共享文件列表做出正确响应
void Download() //针对客户端下载请求做出正确响应
}
二、客户端功能细分
1、获取在线主机
1.1 获取网卡信息,得到局域网中的所有IP地址列表
- 由于UDP协议自带局域网广播功能,但是可能丢包,我们采用tcp协议。
- 获取所有主机IP地址。(IP地址组成:网络号+最大主机号)
//网络号=本机IP地址 和 子网掩码相与 最大主机号:子网掩码取反
//以下是获取本机网卡信息
Adapter
{
public:
uint32_t _ip_addr; //网络字节序的IP地址
uint32_t _mask_addr; //子网掩码信息
}
AdapterUtil
{
#ifdef _WIN32
static GetALLAdapter(std::vector<Adapter> *list) //获取所有网卡信息,返回信息数组
//由于在求得的 0~最大主机号 中,全0和全1是不能用的,实际上我们取出的是 1-254
#else
static GetALLAdapter(std::vector<Adapter> *list) //获取所有网卡信息,返回信息数组
}
当然我们是先获取到所有在线主机,存入vector数组,才逐个的发送配对请求
1.2 逐个对IP地址列表的主机发送配对请求
想要对所有在线主机发送配对请求,就必须采用多线程。每对一个主机发送配对请求,就分配一个线程
在这里,主机配对的线程入口函数是void HostPair(this,uint32_t ip),将这个函数作为参数传进主机配对的每个线程函数,即就是:
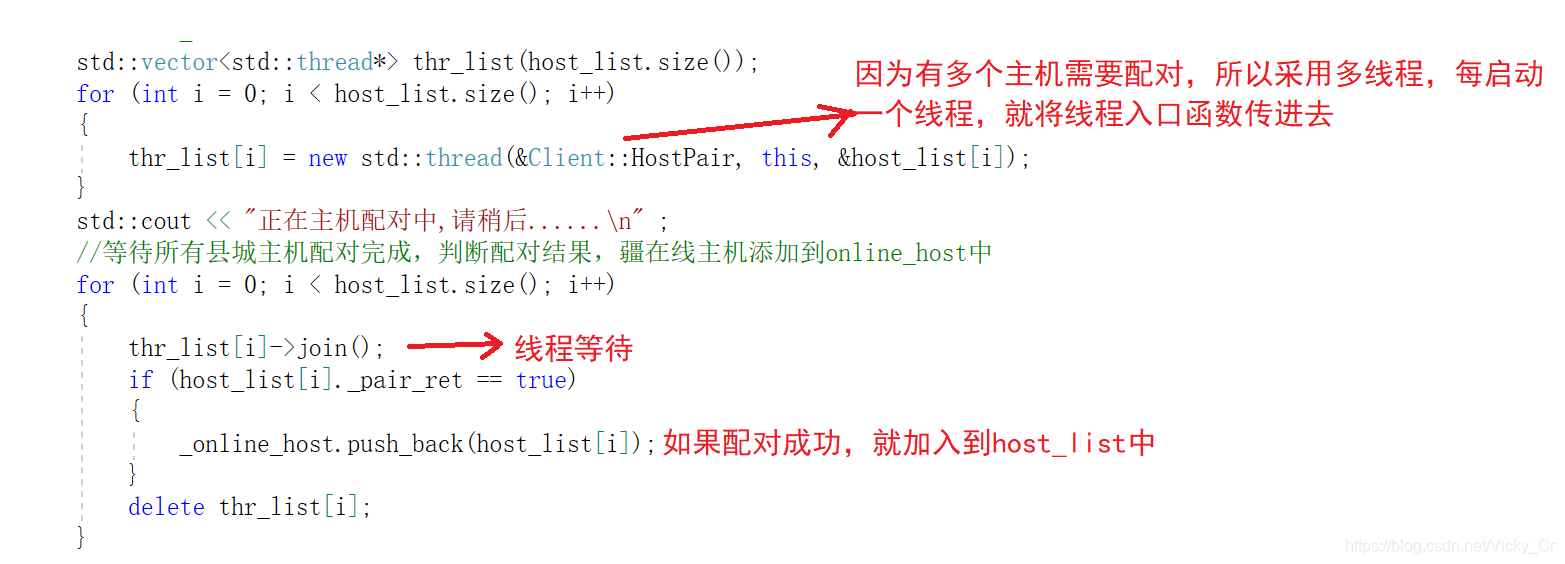
这里最重要的就是主机配对函数—HostPair(this,uint32_t)应该怎么写?需要用到第三方库httplib,搭建服务器
httplib的处理流程
对于客户端来说:
1、它想要配对,必然是自己作为一个客户端给对方发送请求,那这里就要先组织一个http请求数据
2、搭建tcp客户端,与主机建立连接,发送请求数据
3、等待服务器的响应,接收响应数据
4、对响应数据进行解析,判断状态码,200则表示配对成功
对于服务端来说:
1、搭建一个最简单的tcp服务器
2、等待客户端发送的数据
3、按照http的协议格式,对数据进行解析
4、根据请求的资源路径以及字符串进行业务处理
5、组织http协议格式的响应,返回给客户端
关于客户端和服务端的交互,我们就必须要说httplib中最重要的两个类:

那我们接下来就是存放主机的配对结果,成功则为true,失败则为false

1.3 配对得到响应,将在线主机列表的IP地址加入到on_line_host列表中

2、获取指定主机文件列表
接口设计: bool GetShareList(std::string &host_ip)
主要流程:
向服务器发送一个文件列表获取请求
1、先发送请求
2、得到相应之后,解析正文
3、下载指定主机上的指定共享文件
接口:DownloadFile()
本质:网络通信中的文件传输,其实传输的是文件数据,对方打开文件,读取文件数据发送,接收方,创建文件,接收到文件数据,写入文件中,主要流程如下:
1、向服务端发送文件下载请求
2、得到相应结果,相应结果中的body正文就是文件数据
3、创建文件,将文件数据写入新建的文件中,关闭文件
这里就涉及到我们的一个文件操作,所以我们定义了专门的文件操作类,主要包含以下操作:

三、服务端功能细分
服务端主要是对客户端的请求作出响应,比如我们之前在httplib库搭建服务器的时候,客户端会使用Get请求方法,组织成一个数据发送给服务端,这里服务端的响应是:
//添加针对客户端请求处理方式对应关系:
_srv.Get("/hostpair", HostPair); //如果我们接收到hostpair这个请求,那就调用HostPair这个请求方法,后面的函数也是类似功能,很对不同的请求,找到对应的外部函数请求方法
_srv.Get("/list", ShareList);
_srv.Get("/download/.*",Download); //正则表达
3.1 接收到主机配对请求,则做出200响应

3.2 接收到文件列表请求
1、检测获取指定共享目录下的文件信息
2、将所有文件名组织成为http响应正文

3.3 接收到指定文件下载请求
接口:static void Download(const httplib::Request &req, httplib::Response &rsp)
流程如下:
1、通过文件名检测文件是否存在,若不存在则需要重新创建
boost::filesystem::exists(SHARED_PATH)
boost::filesystem::create_directory(SHARED_PATH);
2、检测文件是否是一个普通文件,是的话就浏览这个目录下的文件信息(选择使用C++boost库中提供的文件系统接口实现目录的浏览,以及文件的各种操作)
3、打开文件读取文件数据作为http相应正文给客户端
那这里涉及到一个文件的分块下载问题:
HTTP协议头中的Range字段,告诉服务器一个文档区间范围,若文件大小超过100M,则采用分块传输。所以我们提前得知道文件有多大,HEAD清秀方法就可以解决:HEAD/filename HTTP 1.1只要响应头信息而不要内容,通过响应正文的Content-Length可以知道正文有多大。以下是分块下载的主要代码分析:
bool RangeDownLoad(const std::string &host_ip,const std::string &name)
{
//1、发送HEAD请求,通过响应中的Content——Length获取文件大小
auto rsp=cli.Head(req_path,c_str);
std::string clen = rsp->get_header_value("Content-Length");
int64_t filesize = StringUtil::Str2Dig(clen);
//2、根据文件大小进行分块
// 若文件大小能整除块,则分块个数等于文件大小除以分块大小
range_count = filesize / MAX_RANGE; //计算块数
for (int i = 0; i < range_count; i++)
{
range_start = i * MAX_RANGE; //起始分块
if (i == (range_count - 1)) //末尾分块
{
range_end = filesize - 1;
}
else
{
//除不尽MAX_RANGE就需要+1
range_end = ((i + 1)*MAX_RANGE) - 1;
}
}
//3、注意请求分块数据,得到响应之后写入文件的指定位置
tmp << "bytes=" << range_start << "-" << range_end; //组织一个range头信息的区间值
httplib::Headers header;
header.insert(std::make_pair("Range", tmp.str()));
header.insert(httplib::make_range_header({ {range_start,range_end} }));
auto rsp=cli.Get(req_path.c_str(), header);
if (rsp == NULL || rsp->status != 206)
{
std::cout << "区间下载失败\n";
return false;
}
std::cout << "客户端分块写入文件"<<range_start<<"-"<<range_end<<std::endl;
FileUtil::Write(name, rsp->body, range_start);
} //将下载文件写入文件指定位置
四、项目总结
4.1 项目采用多线程的地方
1、在进行获取完所有的在线主机,我们得向这些主机发送配对请求,这里就采用多线程,发送一个配对请求,启动一个线程,将线程入口函数传递进去。
2、httplib库里面的多线程
3、分块传输的时候采用多线程,因为数据在比较大的情况下,需要分块,传输每个模块的时候,启动一个线程
4.2 项目中存在的问题
(1)httplib版本的适配,网卡信息的获取,分块传输
(2)在分块传输中,由于文件太大,httplib是将文件数据直接放到内存中进行传输,占用大量内存,传输大文件的时候,若内存不够用,存在两种情况:
1)因此产生了大量的内存交换,极大地降低了效率
2)内存不够程序直接崩溃
一开始分多少块,就启动多少线程,并没有解决实际问题,后来采用线程池,限制了同一时间能发送的请求数以及避免同一时间占用内存过多的情况。
(3)在文件下载过程中,下载文件的内容完全一致但是大小不一致,我们利用dos窗口,进入源文件和下载文件,实用工具MD5比较两个文件的大小是否一致(MD5对文件的所有内容进行运算,最终得到一个32字节的字符串,然后可以比较两个字符串是否相同),发现问题出在标准文件操作的问题,使用C++标准库进行文件操作的时候,默认是文本操作,会涉及到字符编码集的宽字符问题,导致读取的数据与写入数据不同,因此在读写文件的时候采用二进制方式读写(wb)问题成功解决
4.3 项目涉及的其他技术:
断点续传:当正在下载文件的时候,网络突然中断,导致文件没有下载完毕而失败,等到下次网络通畅的时候,可以继续从上次断开的位置开始下载文件,而不需要重新下载,来提高异常情况下文件的传输效率
HTTP协议中的数据传输就支持分块传输,但是咱们暂时不实现断点续传,我们使用的是分块传输。
4.4 项目的测试点
功能测试:是否能够正常完成下载功能
性能测试:服务端通信能够同时与多少个客户端进行数据通信,文件传输性能
使用了webbench测试工具对连接数进行了测评,因为虚拟机以及云服务器的资源限制,当前可以连接几十个,再多就会链接失败
对于文件传输,在程序中打了log,对文件传输其实以及结束时间进行时间统计,一个客户端传输50M/s;
4.5 项目的可扩展点
1)网络穿透技术:当前我们所写的p2p程序是一个局域网的p2p无法实现整个网络的p2p,因为局域网之间无法跨网络进行数据传输(因为局域网中的主机都是用的私网地址,并且通过NAPT映射之后才能通信),就算是我们知道对方的私网地址,但是因为我们并没有网络因此无法直接通信,局域网之间想要进行通信就要借助网络穿透技术实现
2)epoll多路转接技术实现总线时间监控
3)视频的直接点播
