堆排序
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。首先简单了解下堆结构。
堆
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
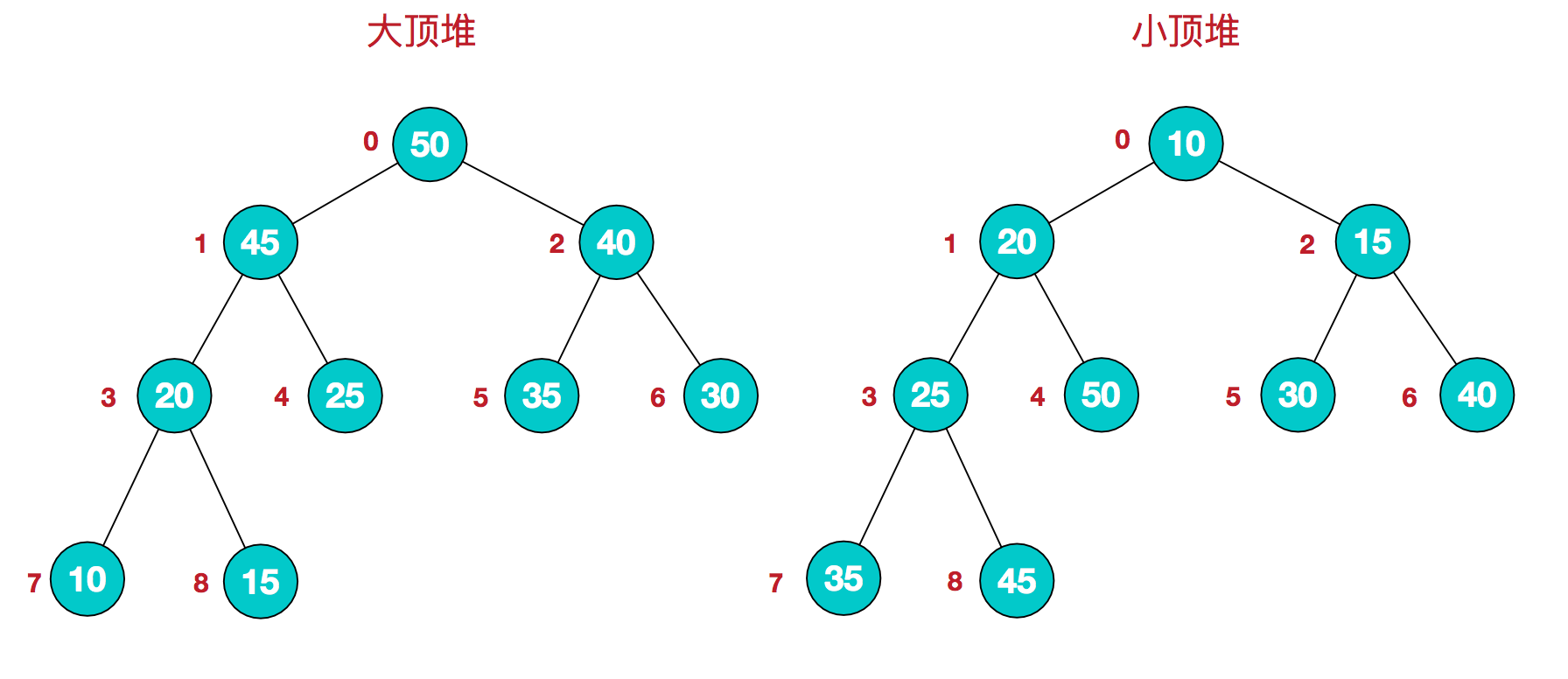
同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子

该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
第一个非叶子结点 arr.length/2-1
堆排序的基本思路:
a.将无序序列构建成一个堆,根据升序降序需求选择大顶堆(升序)或小顶堆;
最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1),从下至上,从右至左进行调整
升序:
b.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
c.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
排序算法(三)堆排序原理与实现(小顶堆)
void AdjustDown(int arr[], int i, int n) { int j = i * 2 + 1;//子节点 while (j<n) { if (j+1<n && arr[j] > arr[j + 1])//子节点中找较小的 { j++; } if (arr[i] < arr[j]) { break; } swap(arr[i],arr[j]); i = j; j = i * 2 + 1; } } void MakeHeap(int arr[], int n)//建堆 { int i = 0; for (i = n / 2 - 1; i >= 0; i--)//((n-1)*2)+1 =n/2-1 { AdjustDown(arr, i, n); } } void HeapSort(int arr[],int len) { int i = 0; MakeHeap(arr, len); for (i = len - 1; i >= 0; i--) { swap(arr[i], arr[0]); AdjustDown(arr, 0, i); } }
冒泡排序
/* * 冒泡排序 */ public class BubbleSort { public static void main(String[] args) { int[] arr={6,3,8,2,9,1}; System.out.println("排序前数组为:"); for(int num:arr){ System.out.print(num+" "); } for(int i=0;i<arr.length-1;i++){//外层循环控制排序趟数 for(int j=0;j<arr.length-1-i;j++){//内层循环控制每一趟排序多少次 if(arr[j]>arr[j+1]){ int temp=arr[j]; arr[j]=arr[j+1]; arr[j+1]=temp; } } } System.out.println(); System.out.println("排序后的数组为:"); for(int num:arr){ System.out.print(num+" "); } } }
归并排序
public static int[] sort(int[] a,int low,int high){ int mid = (low+high)/2; if(low<high){ sort(a,low,mid); sort(a,mid+1,high); //左右归并 merge(a,low,mid,high); } return a; } public static void merge(int[] a, int low, int mid, int high) { int[] temp = new int[high-low+1]; int i= low; int j = mid+1; int k=0; // 把较小的数先移到新数组中 while(i<=mid && j<=high){ if(a[i]<a[j]){ temp[k++] = a[i++]; }else{ temp[k++] = a[j++]; } } // 把左边剩余的数移入数组 while(i<=mid){ temp[k++] = a[i++]; } // 把右边边剩余的数移入数组 while(j<=high){ temp[k++] = a[j++]; } // 把新数组中的数覆盖nums数组 for(int x=0;x<temp.length;x++){ a[x+low] = temp[x]; } }
快速排序
// 快速排序 static void quickSort(int left, int right, int[] nums) { if (left < right) { int pivot = nums[left]; int low = left; int high = right; while (low < high) { while (low < high && nums[high] >= pivot) { high--; } if (nums[high] < pivot) nums[low] = nums[high]; while (low < high && nums[low] <= pivot) { low++; } if (nums[low] > pivot) nums[high] = nums[low]; } nums[low] = pivot; quickSort(left, low - 1, nums); quickSort(low + 1, right, nums); } }
为什么先序遍历和后序遍历不能确定唯一的二叉树
前序和后序在本质上都是将父节点与子结点进行分离,但并没有指明左子树和右子树的能力,因此得到这两个序列只能明确父子关系,而不能确定一个二叉树。
由二叉树的中序和前序遍历序列可以唯一确定一棵二叉树 ,由前序和后序遍历则不能唯一确定一棵二叉树
顺序表 线性表 数组的区别
-
数组就是相同数据类型的元素按一定顺序排列的集合。
一句话:就是物理上存储在一组联系的地址上。也称为数据结构中的物理结构。
-
线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。
一句话:线性表是数据结构中的逻辑结构。可以存储在数组上,也可以存储在链表上。
-
线性表的结点按逻辑次序依次存放在一组地址连续的存储单元里的方法。用顺序存储方法存储的线性表简称为顺序表。
一句话:用数组来存储的线性表就是顺序表。
对一个无向图进行先深搜索时,得到的先深序列是唯一的 X
哈希法的平均查找长度不随表中结点数目的增加而增加,而是随负载因子的增大而增大
采用哈希表组织100万条记录,以支持字段A快速查找
理论上可以在常数时间内找到特定记录
所有记录必须存在内存中
拉链式哈希曼最坏查找时间复杂度是O(n)
哈希函数的选择跟A无关
答案:C
A,记录共有100万条,一般的哈希表长度不可能做这么长,因此要解决散列冲突问题,因此一般不能再常数时间内找到记录
B,哈希查找可以在外存中查找,可以用哈希表映射到文件,分级查找
C,最坏情况是所有记录的散列值都冲突,这样就退化为线性查找,时间复杂度为O(n)
D,哈希函数的选择跟A关系密切,跟A的字段类型有关,哈希函数设计的好坏也影响着查找的速度
二叉树在线索化后,仍不能有效求解的问题是后序线索二叉树中求后序后继
前序遍历(中左右)、中序遍历(左中右)的最后访问的节点都是左或右叶节点, 叶节点是没有子树的,所以两个指针域空出来了,可以存放线索指针。但是后续遍历(左右中), 最后访问的子树的根节点,子树根节点的两个指针域都指向子树了,所以不能空出来存放线索信息。
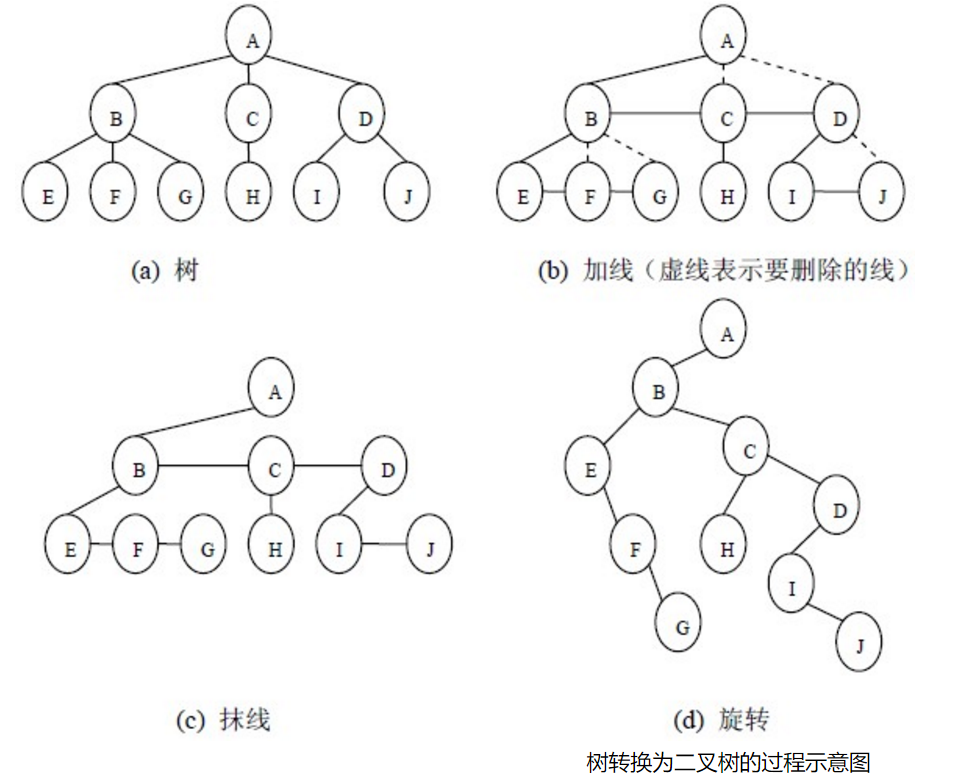
把一棵树转换为二叉树后,这棵二叉树的形态是唯一的
若一个有向图的邻接矩阵对角线以下元素均为零,则该图的拓扑有序序列必定存在
一个有向图能被拓扑排序的充要条件就是它是一个有向无环图。
双链表中至多只有一个结点的后继指针为空
强连通分量是无向图的极大强连通子图
有向图强 连通分量 :在 有向图 G中,如果两个顶点vi,vj间(vi>vj)有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点 强连通 (strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个 强连通图 。有向图的极大强连通子图,称为强连通 分量 (strongly connected components)。
如果约定树中结点的度数不超过2,则它实际上就是一棵二叉树 X
因为已经说是树了,所以不考虑回路的问题,其次二叉树度为2,子树有左右之分,次序不能颠倒。因此仅仅说度不超过2不能说是一颗二叉树。
外部排序思想
现在我要进行排序,不过需要排序的数据很大,有1000G那么大,但是我的机器内存只有2G大小,所以每次只能把2G的数据从文件中传入内存,然后用一个“内部排序“算法在内存排好序后,再将这有序数据,载入一个2G大小的文件。然后再载入第二个2G数据。。。循环500遍之后,我现在得到500个文件,每个文件2G,文件内部是有序的,然后我再比较这500个文件的第一个数,最小的肯定就是这1000G数据的最小的。那么之后的过程你肯能想到了,就是不断将这500个2G 数据进行一个归并,最终就能得到这1000G的有序数据文件了。
举个例子,比如我要排序10个数,但是我的内存一次只能装下5个数,所以最初的10个数我只能放到文件里面(文件时外存,只要硬盘或磁盘够大,想多大就多大)。内部排序肯定是得需要将数据载入内存中才可以进行的。
这10个数是[ 2 ,3,1,7,9 ,6, 8,4 ,5 ,0 ]。
第一次载入前五个数2,3,1,7,9. 排好序后是:1,2,3,7,9 然后导入一个只存五个数的文件中。
第二次载入后五个数6,8,4,5,0 排好序后是:0,4,5,6,8,然后倒入一个只存五个数的文件中。
之后在归并两个有序数列
第一个有序子数列的头位1,第二个为0,因为0然后在进行第二次比较,1和4进行比较。。。
重复进行最终得到一个有序数列的文件,里面存着,0,1,2,3,,,7,8,9
问题是:在这个过程中,你能想到哪些优化?
(擦,,,背景描述了半天,问题就一句话。。。当时我也很无语。。。)
解答:
想了大概一分钟,除了增设一个缓冲buffer,加速从文件到内存的转储之外,我脑子里面一片空空。。。而且我想到的那个缓冲buffer所得到的回复是“假设这个优化系统已经帮你优化了” 。。。无语。。。
他看我眉头紧锁,然后给我做了一个提示:假设我现在把文件中的2G数据载入内存这个过程定义为”L”,把内存中的排序过程定义为”S” ,把排序好的 2G数据再转储到另一个文件这个过程定义为”T”…
他还没说完,瞬间反应过来了!“用流水线并行实现“,然后我把流水线那个图画了出来,就是在计算机组成原理那本书中经常出现的“流水线图”。图画好后,他点点头,我也长嘘一口气。。。
然后他问我,用流水线技术之后为什么会加速整个过程。
当然这个问题就很容易了,过去得把一组2G数据的三个过程全部处理完之后,才能进行下一个2G数据的处理,现在就可以三个过程并行着进行了。当时我也忘了,加速比怎么计算了,所以就没提这个东西。。。
他接着问,做了这个并行处理之后,会出现什么问题?
。。。MD,又是一个恶心问题,其实我清楚,问题不难,但是“找问题”好讨厌啊。。。
想了一下,我说,在“S”这个过程,也就是内部排序的这个环节最好不要用“快速排序”,因为快速排序是不稳定的排序,所以在流水线那个图中会出现不均匀的时间块,影响整体性能。
他想了一下,点点头。问,还有吗?给你个提示吧,你想想加了这个优化之后,某个资源会不会出问题?
我想了想,“资源”,计算机的资源没几样啊,CPU,内存。。。再一次,瞬间恍然大明白,是内存出的问题,因为,如果并行进行的话,打个比方,比如现在同时处理的过程是,第一个2G数据的“T”阶段(因为第一个2G数据,比较早的进入流水线,所以之前的两个阶段已经处理完毕),第二个2G数据的“S”阶段,第三个2G数据的“L”阶段,那么这三个阶段是都需要把数据放到内存中的,所以一共得需要6G内存,但是目前计算机的实际内存只有2G啊!!!
解决方法很简单,将内存平均分为三份,分别用于处理三个阶段的数据。
这样带来的影响是,现在一次就不能处理2G数据了,只能处理2/3G的数据,流水线会加长。
他看这块处理的差不多了,就继续提示,你看看在最后的归并上有什么优化?
最后的归并就是不断在一组有序数列中找最小值,还用刚才那个例子,最后不是得到500个2G有序数列吗,但是扫描每个文件头,找最小值,最差情形要比较500次,平均复杂度是O(n),n为最后得到的有序数组的个数,此例子为500。
他既然问有没有什么优化?那么必然是存在logn的算法了。一提logn和最小值,那没的说,必须是“堆”啊!!!
然后我给他说了一下具体实现细节
就是维护一个大小为n的“最小堆”,每次返回堆顶元素,就为当前所有文件头数值的那个最小值。然后根据刚才弹出的那个最小值是属于哪个文件的,然后再将那个文件此时的头文件所指向的数,插入到最小堆中,文件指针自动后移。插入过程为logn复杂度,但是每次返回最小值的复杂度为O(1),运行时空间复杂度为O(n)。 OK,搞定。
下面的排序方法中,关键字比较次数与记录的初始排列无关的是:
堆排序和选择排序的排序次数与初始状态无关,即最好情况和最坏情况都一样
堆排序平均执行的时间复杂度和需要附加的存储空间复杂度分别是O(Nlog2N)和O(1)