1、流程框架

2、在命令行中输入scrapy,会有scrapy常见命令参数


cd到创建好的项目目录中,然后执行scrapy genspider quotes quotes.toscrape.com,创建spider,指定spider名称--->quotes,
指定spider抓取的网址-->quotes.toscrape.com
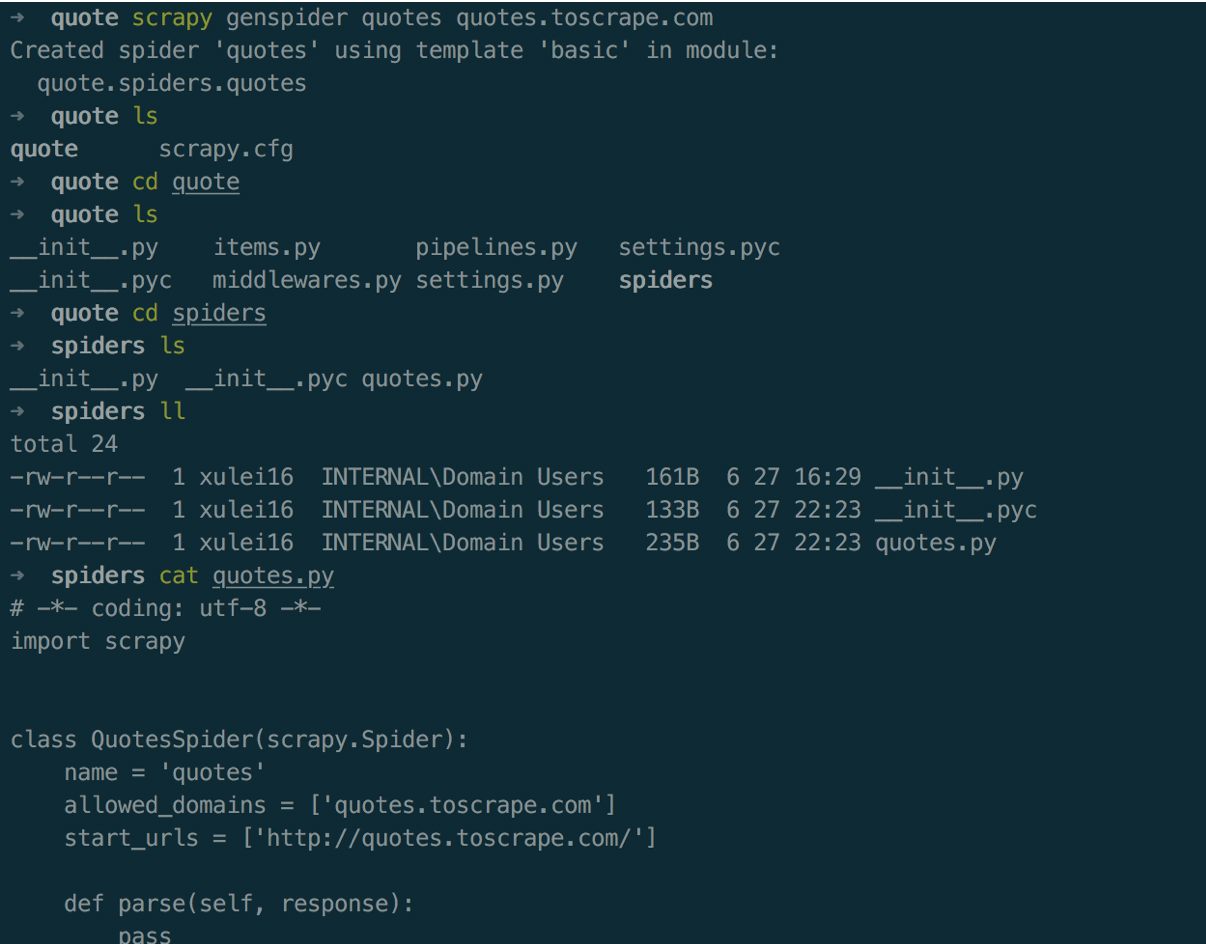
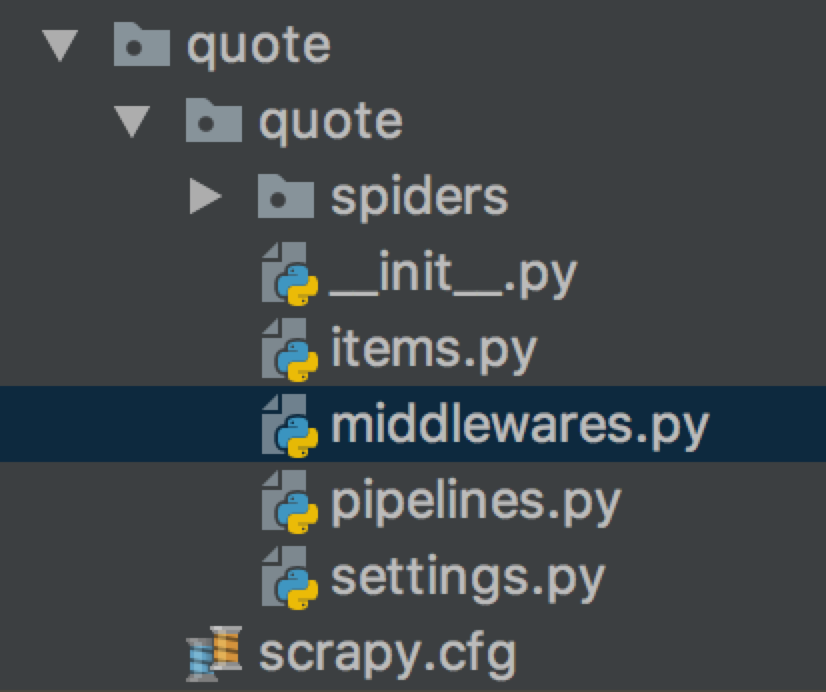
这是一个scrapy框架默认目录结构
scrapy.cfg --> 配置文件,指定settings配置文件路径
quote/ ---> 该项目的python模块,之后您将在此加入代码。
quote/items.py --> 用来保存数据接口
quote/middlewares.py --> 存储中间件
quote/pipelines.py --> 项目中的pipelines文件
quote/settings.py --> 定义一些配置信息
quote/spiders/ --> 放置spider代码的目录
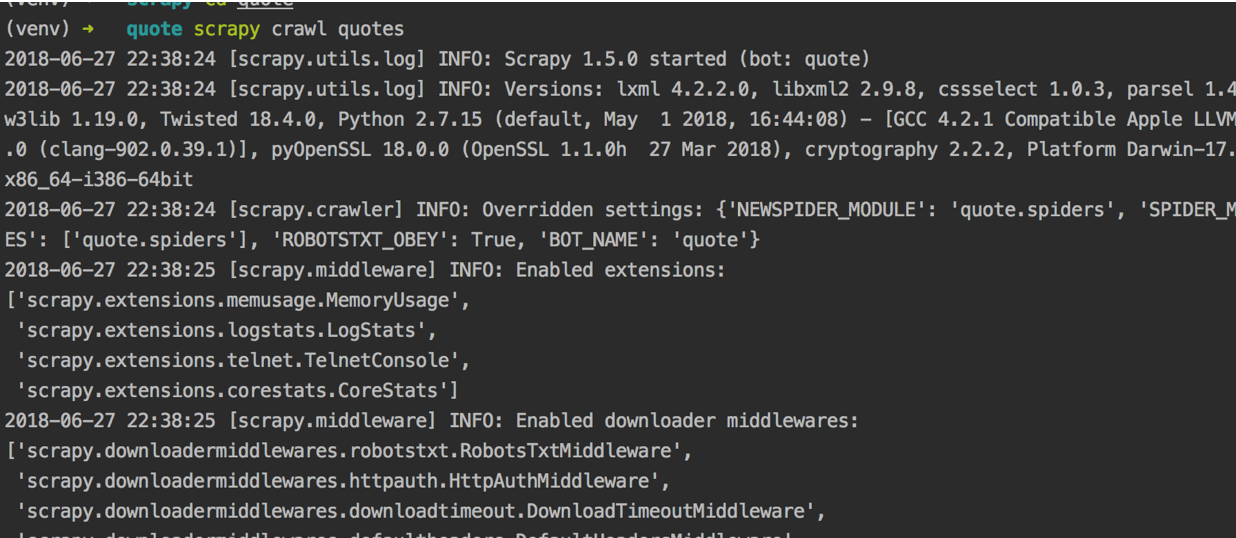
3、在命令行中输入scrapy crawl quotes,会输出一些配置信息
scrapy还有一个命令行调试模式,直接在命令行执行scrapy shell quotes.toscrape.com
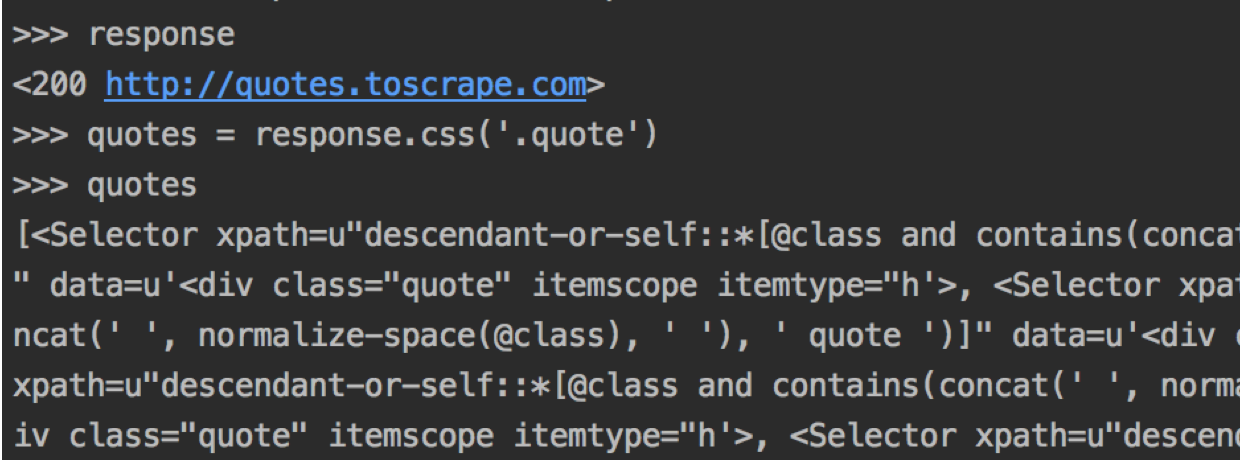
extract_first是输入第一个匹配的,是字符串,extract是匹配有多个结果的,输出列表类型

执行scrapy crawl quotes -o quotes.json可以保持到本地文件,还支持quotes.jl .csv ,还有支持向ftp传输数据
scrapy crawl -o ftp://user:[email protected]/path/quotes.csv
使用-o是可以指定保持需要的文件格式,这个保持方法scrapy都已经集成好了
4、抓取了一个网址先测试scrapy,具体代码请参考GitHub
https://github.com/watchxu/python/tree/master/ScrapyQuotes