为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2 3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;
为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured
Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;通过改善 pandas
UDFs 的性能来提升 PySpark;支持第四种调度引擎 Kubernetes clusters(其他三种分别是自带的独立模
式Standalone,YARN、Mesos)。除了这些比较具有里程碑的重要功能外,Spark 2.3 还有以下几个重要的更新:
引入 DataSource v2 APIs [SPARK-15689, SPARK-20928]
矢量化(Vectorized)的 ORC reader [SPARK-16060]
Spark History Server v2 with K-V store [SPARK-18085]
基于 Structured Streaming 的机器学习管道API模型 [SPARK-13030, SPARK-22346, SPARK-23037]
MLlib 增强 [SPARK-21866, SPARK-3181, SPARK-21087, SPARK-20199]
Spark SQL 增强 [SPARK-21485, SPARK-21975, SPARK-20331, SPARK-22510, SPARK-20236]
这篇文章将简单地介绍上面一些高级功能和改进,更多的特性请参见 Spark 2.3 release notes:https://spark.apache.org/releases/spark-release-2-3-0.html。

毫秒延迟的连续流处理
Apache Spark 2.0 的 Structured Streaming 将微批次处理(micro-batch processing)从它的高级 APIs 中解耦出去,原因有两个:首先,开发人员更容易学习这些 API,不需要考虑这些 APIs 的微批次处理情况;其次,它允许开发人员将一个流视为一个无限表,他们查询流的数据,就像他们查询静态表一样简便。
大数据学习可以加群:716581014
但是,为了给开发人员提供不同的流处理模式,社区引入了一种新的毫秒级低延迟(millisecond low-latency)模式:连续模式(continuous mode)。
在内部,结构化的流引擎逐步执行微批中的查询计算,执行周期由触发器间隔决定,这个延迟对大多数真实世界的流应用程序来说是可以容忍的。
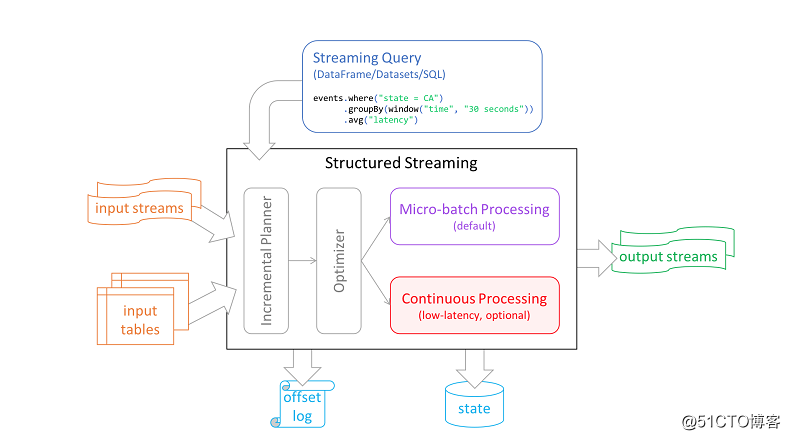
对于连续模式,流读取器连续拉取源数据并处理数据,而不是按指定的触发时间间隔读取一批数据。通过不断地查询源数据和处理数据,新的记录在到达时立即被处理,将等待时间缩短到毫秒,满足低延迟的应用程序的需求,具体如下面图所示:
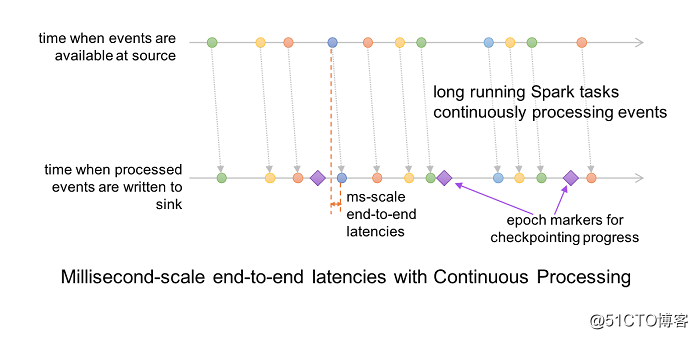
目前连续模式支持 map-like Dataset 操作,包括投影(projections)、selections以及其他 SQL 函数,但是不支持 current_timestamp(), current_date() 以及聚合函数。它还支持将 Kafka 作为数据源和数据存储目的地(sink),也支持 console 和 memory sink。
现在,开发人员可以根据延迟要求选择模式连续或微量批处理,来构建大规模实时流式传输应用程序,同时这些系统还能够享受到 Structured Streaming 提供的 fault-tolerance 和 reliability guarantees 特性。
简单来说,Spark 2.3 中的连续模式是实验性的,它提供了以下特性:
端到端的毫秒级延迟
至少一次语义保证
支持 map-like 的 Dataset 操作
流与流进行Join
Spark 2.0 版本的 Structured Streaming 支持流 DataFrame/Dataset 和静态数据集之间的 join,但是 Spark 2.3 带来了期待已久的流和流的 Join 操作。支持内连接和外连接,可用在大量的实时场景中。
广告收益是流与流进行Join的典型用例。例如,展示广告流和广告点击流共享您希望进行流式分析的公共关键字(如adId)和相关数据,根据这些数据你可以分析出哪些广告更容易被点击。
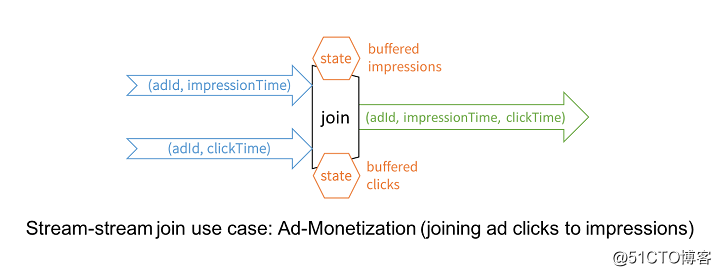
这个例子看起来很简答,但是实现流和流的Join需要解决很多技术难题,如下:
需要缓存延迟的数据,直到从其他流中找到匹配的事件;
通过 watermark 机制来限制缓存区使用增长;
用户可以在资源使用和延迟之间作出权衡;
静态连接和流式连接之间保持一致的SQL连接语义。
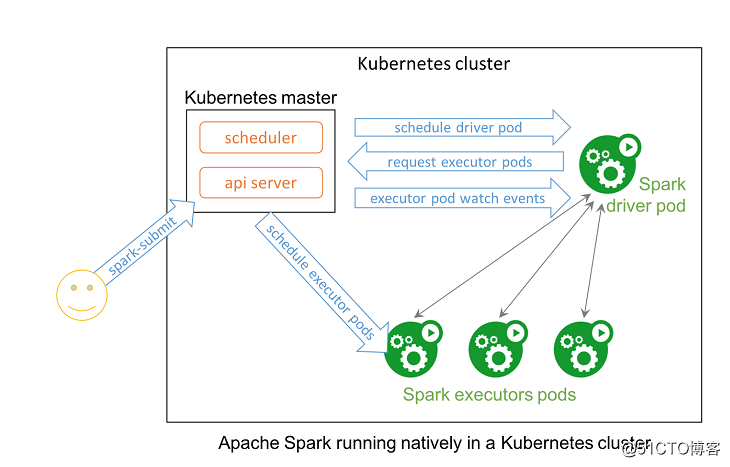
Apache Spark 和 Kubernetes
Apache Spark 和 Kubernetes 结合了它们的功能来提供大规模的分布式数据处理一点都不奇怪。在 Spark 2.3 中,用户可以利用新的 Kubernetes scheduler backend 在 Kubernetes 集群上启动 Spark 工作。 这使得 Spark 作业可以和 Kubernetes 集群上的其他作业共享资源。
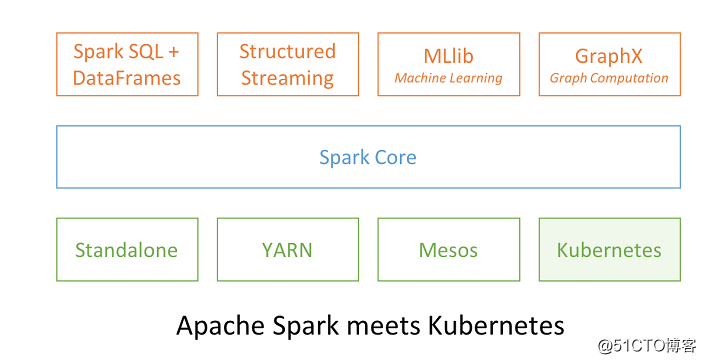
此外,Spark 可以使用所有管理功能,例如资源配额(Resource Quotas),可插拔授权(Pluggable Authorization)和日志记录(Logging)。
支持 PySpark 的 Pandas UDFs
Pandas UDFs 也称为 Vectorized UDFs,是提升 PySpark 性能的主要推动力。它构建在 Apache Arrow 的基础上,为您提供两全其美的解决方案:低开销和高性能的UDF,并完全使用 Python 编写。
在 Spark 2.3 中,有两种类型的 Pandas UDF:标量(scalar)和分组映射(grouped map)。 两者均可在 Spark 2.3 中使用。
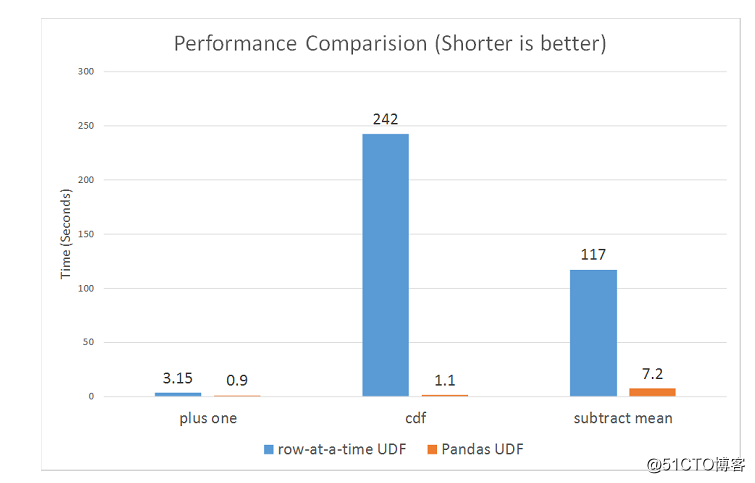
下面是运行的一些基准测试,可以看出 Pandas UDFs 比 row-at-time UDFs 提供更好的性能。
MLlib 提升
Spark 2.3 包含了许多 MLlib 方面的提升,主要有算法、特性、性能、扩展性以及可用性。这里只介绍其中三方面。
首先,为了将 MLlib 模型和 Pipelines 移动到生产环境,现在拟合的模型(fitted models)和 Pipelines 可以在 Structured Streaming 作业中使用。 一些现有的管道(Pipelines)需要修改才能在流式作业中进行预测。
其次,为了实现许多 Deep Learning 图像分析用例,Spark 2.3 引入了 ImageSchema [SPARK-21866] 用于在 Spark DataFrame中表示图像,以及加载常见格式图像的实用程序。
最后,对于开发人员来说,Spark 2.3 引入了改进的 Python API以编写自定义算法。
大数据学习QQ群:716581014 专注大数据分析方法,大数据编程,大数据仓库,大数据案例,人工智能,数据挖掘,AI等大数据内容分享交流。不定期举办线上线下大数据内容分享活动